Hadoop优势
- 高可靠性:由于在不同的节点或者相同的节点都存在着一份或者多份的数据副本也就是备份(后面会我会告诉大家如何设置数据备份的数量),所以面对类似单点故障的情况也不会发生一些数据安全的问题。
- 高扩展性:我们利用Hadoop框架进行集群的搭建,所以我们可以进行结点的扩展,很方便,便于算力、资源的扩展。
- 高效性:Hadoop框架使用的是并行处理的处理方式,多个节点同时工作,效率非常高。
- 当然可能大家在别的学习途径上还能看到一些其他的优点,但是这是我体会比较深的三个。也可以说是最重要的。
HDFS架构概述
在上一次的伪分布的安装介绍中我们有一幅图中提到了Hadoop中的四个主要部分,链接在这里添加链接描述
而其中HDFS分布式文件系统更是基础中的基础。
- 在我们的集群中不同的节点充当不同的角色。HDFS的体系中,有namenode和datanode以及secondaryNamenode这三种角色。
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
MapReduce
简单来讲MapReduce就是一个分布式的计算框架,而它的命名也就非常好的体现了MapReduce的真谛。哈哈,我说一下我自己的理解啊,不那么专业,但是真的很好让人理解。
所谓MapReduce我们分成两个单词看,先是Map然后在进行Reduce操作,什么是Map呢,就是将数据Map,即将数据分块;那么什么是Reduce呢,就是当我们经过map的过程之后就出现了成千上万个map也就是数据块,那这可不行我们要将他们的数量减少,进行一定的计算处理进而达到合并的效果,这不就是Reduce吗。
Yarn架构
说完了HDFS,MapReduce就生下了Yarn了,那接下来就是Hadoop架构中的负责资源管理和调度的yarn的结构介绍了。这里我们先看一下这个Yarn的架构图。
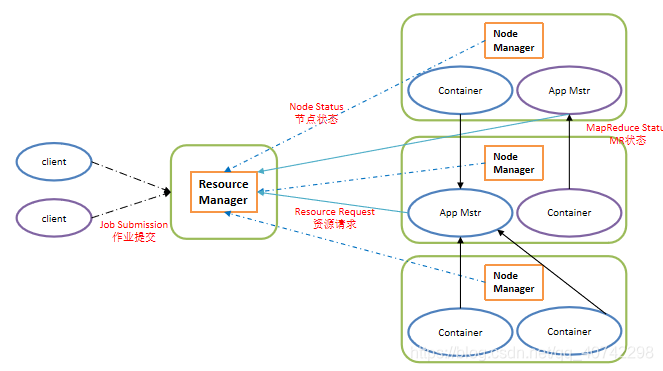
这个图片其实我们也看到了不同的节点角色。其中包括:
- Resource Manager:处理客户端的请求,并进行资源的分配和调度,可以理解为管理者,同时监控着Node Manager的情况。
- Node Manager:负责一个结点的资源的分配和调度,同时响应Resource Manager的命令,同时也响应App Master的命令。
这是主要的架构,同时我们可以发现其实有点像HDFS的架构,因为都有共同的特点就是主从结构,在后面的学习中我们会经常看到这样的架构模式出现在大数据的体系中。
HDFS写数据的流程(这里我们以上传文件为例)
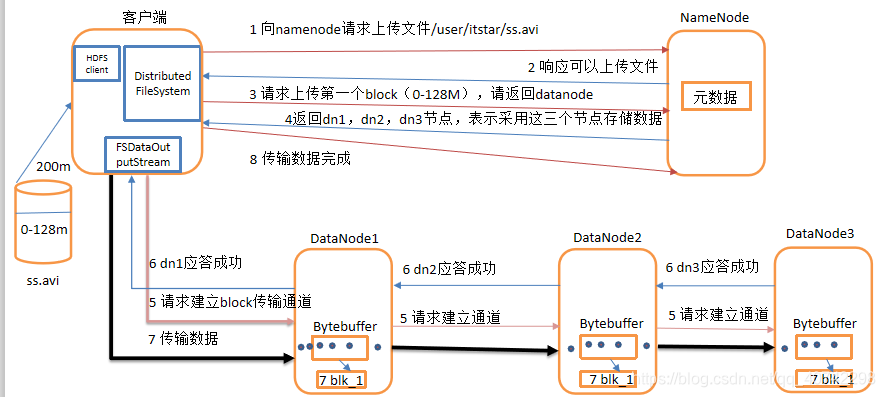
上面的图片中客户端的FSDataOutputStream就是一个java的工具类。后面我会交大家配置和使用。
这是让我受益良多的一张流程图,非常清楚了解释了HDFS进行数据写入时的具体流程,大家可以先看一下答题的流程,后面我会亲自演示如何进行文件的上传到分布式系统,同时使用webConsoleDase进行管理查看。
以上图片来自潭州教育
由于暑假参加了信安比赛还有实践,然后开学来了又帮朋友写了应用,所以断更了一段时间,真的很抱歉,以后我每周都努力更三篇大数据和4篇数据分析的博文(当然是事少的时候)。一起共勉。
