【清华大学】操作系统 陈渝 Part4 ——物理内存管理 之 非连续内存分配
连续内存分配的缺点
- 分配给一个程序的物理内存是连续的
- 内存利用率较低
- 有外部碎片、内碎片的问题
非连续内存分配的优点
- 一个程序的物理地址空间是非连续的
- 更好的内存利用和管理
- 允许共享代码与数据(共享库等)
- 支持动态加载和动态链接
非连续内存分配的缺点
- 如何建立虚拟地址和物理地址之间的转换?
1.软件方案:开销大
2.硬件方案:分段,分页
4.1 分段(Segmention)
程序的分段地址空间
计算机程序是由各种各样的段组成的,根据每个段的属性划分出不同的段,每个段的大小不固定。
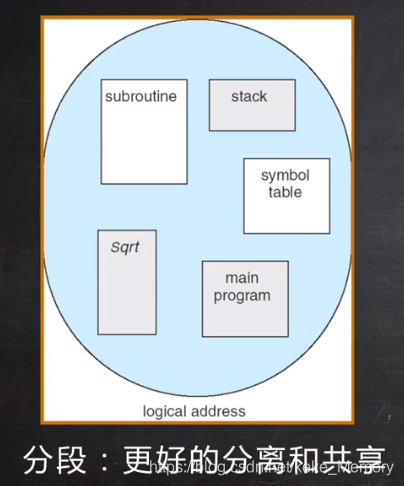
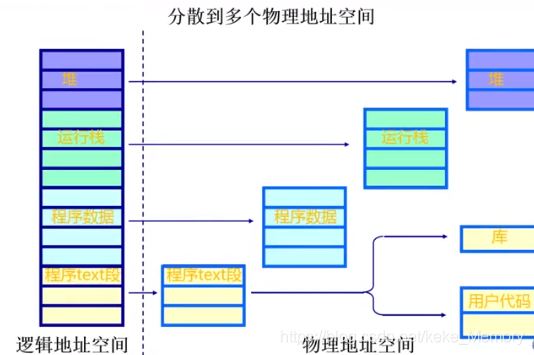
把逻辑地址空间看成一维的连续数组,通过映射关系(分段技术支持)把不同的段(堆,运行栈,程序数据…)映射到不同的物理地址空间去。
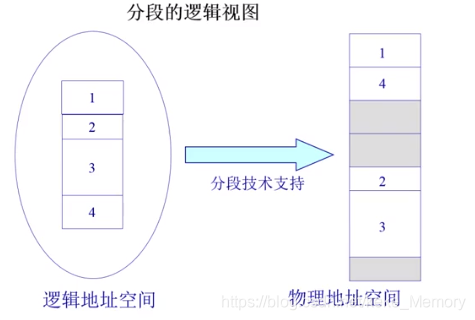
分段寻址方案
一维连续的逻辑地址是由不同的段组成的,把一维地址分成两部分:段号和段内地址
段访问机制
- 新概念:一个段就是一个内存"块"
代表一个逻辑地址空间 - 程序访问内存地址需要:
一个2维的二元组(s,addr)
| s | addr |
|---|---|
| 段号 | 段内偏移 |
两种情况:
1.段号和地址分开的寻址方式:段寄存器+地址寄存器
2.段号和段内便宜形成一个完整的地址:段寄存器
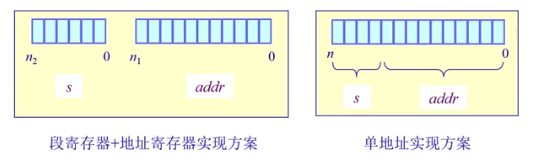
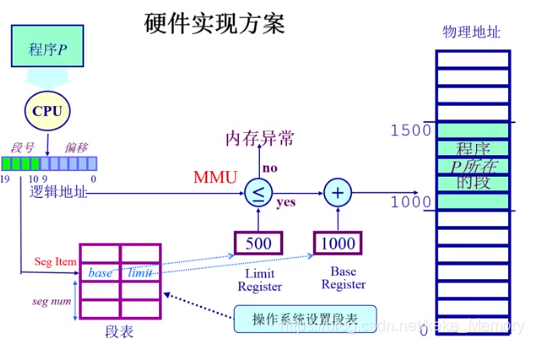
硬件实现方案
如何建立段映射机制?
从一维线性连续的逻辑地址空间通过段映射机制映射到不连续的物理地址空间中去,物理地址空间是由不同的段组成的。
当CPU要执行一段程序时,需要知道程序的数据在哪里,也就是地址在哪,才可以加载到内存中运行,CPU通过程序的指令知道了:段号 (段表中的索引)和 偏移;
段表 中存在逻辑地址和物理地址的对应关系:起始地址 和 长度限制(异常处理)。
段表是操作系统建立的,段表建立以后就可以正常过了,段表的建立和硬件有紧密的联系。
4.2 分页(Paging)
在分段机制中,段大小是可变的,而分页机制中,页的大小是一定的。
分页地址空间
划分物理内存至固定大小的帧
- 大小是2的幂,比如:512,4096,8192
划分逻辑地址空间至相同大小的页
- 大小是2的幂,比如:512,4096,8192
建立方案:转换逻辑地址为物理地址(pages to frames)
- 页表
- MMU/TLB
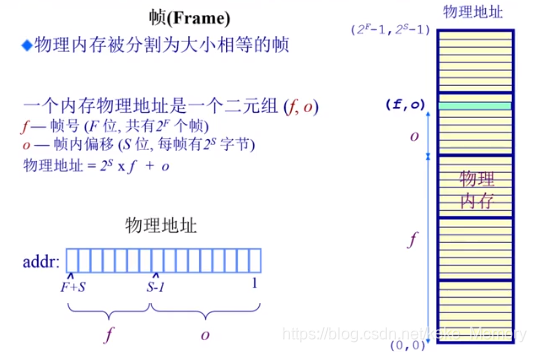
帧(Frame):物理页寻址方式
概念:物理内存被分割为大小相等的帧,是物理内存单元,布局方式,代表物理地址
组成:一个二元组(f,o)
| f | o |
|---|---|
| 帧号 | 帧内偏移 |

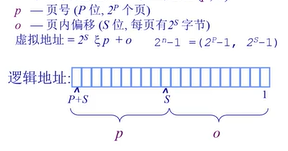
页(Page):逻辑地址的寻址方式
概念:一个程序的逻辑地址空间被划分为大小相同的页
- 页内偏移的大小 = 帧内便宜的大小
- 页号大小 和 帧号大小可能不一样
组成:一个二元组(p,o)
| p | o |
|---|---|
| 页号 | 页内偏移 |
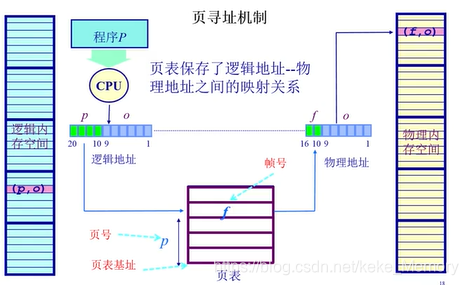
页寻址机制
程序本身的地址是连续的,由大小相等的页组成的逻辑地址,整个程序的容量和物理地址空间可能不一样。当一个程序要运行时,和分段机制一样,CPU会去寻址,无论是执行指令还是访问数据,它都需要知道指令和数据所在的位置,CPU通过程序的指令知道了:页号 (页表中的索引)和 页内偏移,通过页表机制来找到相应的物理地址。
页表是操作系统建立的,初始化时候就建立好了,页表建立以后程序就可以正常跑了。
分段机制和分页机制比较
| 分段机制 | 分页机制 |
|---|---|
| 段的大小不固定 | 页内偏移大小固定,硬件实现更简单 |
| – | 逻辑地址空间一般大于物理地址空间 |

4.3 页表(Page Table)
页表概述
页表记录着逻辑地址和物理地址之间的映射关系。
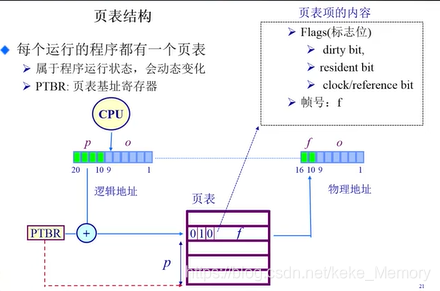
页表结构
页表索引:p
页表项内容 : f
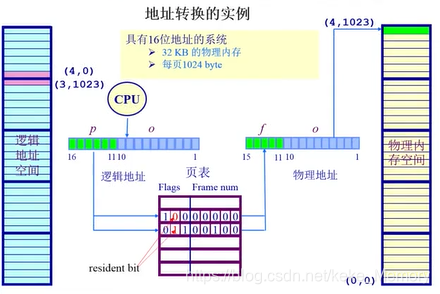
实例:
一个具有16位地址的系统,逻辑地址空间为2的16次幂,也就是64KB的逻辑地址空间。
而实际的物理内存为32KB,每页有1024 byte。
所以逻辑地址和物理地址空间大小不一定相等,但是每个页内偏移大小一样,页大小和帧大小都是1 KB。
二元数组(4,0)表示 : 逻辑页号为4,页内偏移为0。
分页机制的性能问题
逻辑地址到物理地址转换会带来 空间代价 和 时间消耗 两个问题,因此当实现时我们希望占用空间小,执行速度快,两者都要兼顾。
- 寻址时访问一个内存单元需要2次内存访问
- 一次用于获取页表项
- 一次用于访问数据
- 页表可能非常大
- 64位机器寻址空间的逻辑地址非常大,如果每页1024 Byte,那么这张页表的大小是多少呢?
- 有多个应用程序的时候,每个程序都有一张页表,那么所有的程序占用的页表非常大
- 如何处理?
1.缓存(Caching) :提升访问速度 – TLB
2.间接(Indirection):减少页表占用空间大的问题 – 二级/多级 页表
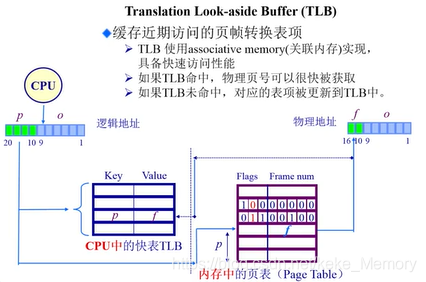
转换后备缓冲区(TLB)
CPU中内存管理单元(MMU)中有一个叫做Translation Look-aside Buffer(TLB)的缓冲,缓冲的是页表中的内容。TLB是一块特殊的区域,在CPU内部。
概念: 缓存近期访问的页帧转换表项
组成:二元数组(p,f),p 为 Key, f 为 value。
特点:访问速度块(如果在TLB中存在地址,不需要访问页表了),容量代价高
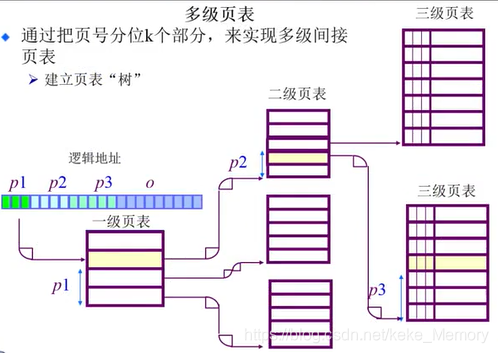
4.4 二级/多级 页表
TLB在速度上提高了地址映射机制,那么空间上怎么样减少呢?
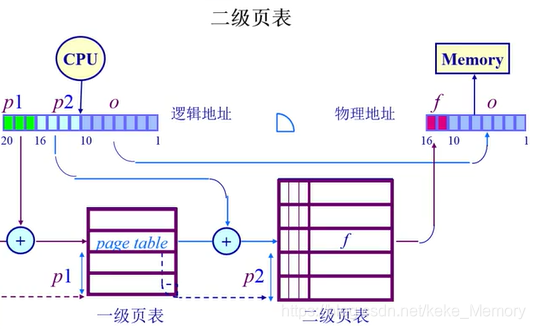
二级页表
把单一的page table 变成两张,逻辑地址中的p分成两部分:p1(一级页表页号) 和 p2(二级页表页号),使得对一个大地址的寻址变成对n个小页表的寻址。
结构
| 一级页表 | 二级页表 |
|---|---|
| p1是索引对应的是一级页表页表项 - 找到二级页表的起始地址p2 | p2是索引对应的是一级页表页表项 -找到帧号,和帧内偏移结合,便找到了物理地址 |
优势
节省空间,使得某些不存在的映射关系不占用内存。如果p1对应的页表项不存在,相应的二级页表就不会占用内存空间了。
多级页表
4.5 反向页表
大地址空间问题
有大地址空间(64 bits),前向映射表变得繁琐
- 比如:5级页表
不让页表与逻辑地址空间的大小相对应,而是让页表与物理地址空间的大小相对应
- 逻辑(虚拟)地址空间增长速度快于物理地址
现在,以物理地址的页号作为索引来查找对应的逻辑页号,怎么做呢?
1.基于页寄存器(Page Registers)的方案
以物理地址的帧号为索引,页表项内容是页号。
页寄存器的方案设计使得寄存器容量只与物理地址空间大小相关,和逻辑地址空间大小不相关。
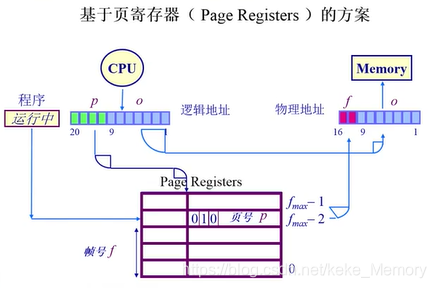
如何使用页寄存器

页寄存器的权衡
| 利 | 弊 |
|---|---|
| 转换表的大小相对于物理内存来说很小 | 需要的信息和分页机制对调了,即根据帧号可找到页号 |
| 转换表的大小和逻辑地址大小无 | 如何转换回来?即根据页号找到帧号 |
| – | 再需要在反向页表中搜索想要的页号 |
根据这样的结构似乎还是不可以有效的根据页号找到帧号。
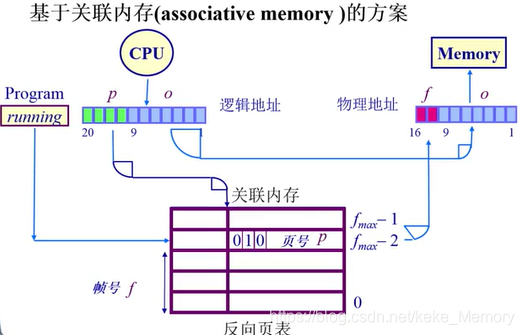
2.基于关联内存(associative memory)的方案
并行的查找页号和帧号,key是页号,value是帧号。
在反向页表中搜索一个页对应的帧号
- 如果帧数较少,页寄存器可以被放置在关联内存中
- 在关联内存中查找逻辑页号
成功:帧号被提取
失败:页错误异常(page fault)
限制因素
- 大量的关联内存非常昂贵
难以在单个时钟周期内完成
耗电
需要放进CPU里, 成本开销大,设计很复杂,无法做到大容量。
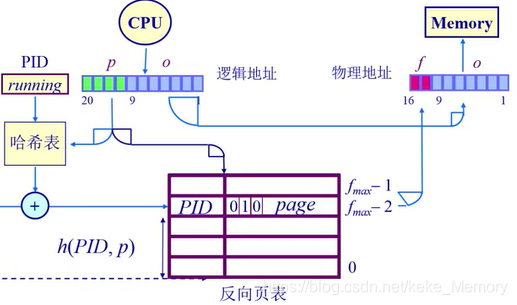
3.基于哈希(hash)查找的方案
利用哈希表实现根据页号查找帧号的过程
基于哈希计算的反向页表,哈希函数是一个简单的数学计算,用硬件加速的方法提高效率,加上一个PID作为input,设计一个简单的函数,算出对应的帧号。
在反向页表中通过哈希算法来搜索一个页对应的帧号
- 对页号做哈希计算,为了在"帧表"(每帧拥有一个表项)中获取相应的帧号
- 页 i 被放置在表中 f(i) 位置,其中f 是设定的哈希函数
- 为了查找页 i ,执行下列操作:
1.计算 哈希函数 f(i) 并且使用它作为页寄存器表的索引
2.获取对应的页寄存器
3.检查寄存器是否包含 i ,如果包含,则代表成功,否则失败。
| 利 | 弊 |
|---|---|
| 可以有效的缓解完成映射带来的开销 | 查找中可能会出现哈希碰撞,输入一个input可能会有多个outout,所以通过程序的PID来缓解多个帧号输出值的冲突 |
| 不受逻辑地址空间限制,可以做到很小,只与物理地址空间相关 | 反向页表在内存中,在做哈希计算时还需要去内存中取数,依然需要访问内存取数,对内存的开销依然很大,还需要类似TLB机制来缓存,降低访问反向页表时间。 |
目前,只有高端的CPU有反向页表机制,因为需要高速的哈希计算来自硬件支持,还需要有解决冲突的机制才能使得访问效率得到保障。软件和硬件的配合可以解决空间上还有时间上的限制。
