前言
上一期介绍了NLP中使用到的基础网络结构RNN和LSTM。本篇博客将介绍以该网络为基础的NLP模型:Seq2Seq Model。
序列生成
首先我们来看如何将自然语言输入到网络当中。我们知道一篇文章是由多个语句组成的,而一个句子是由多个词语或者字组成的。我们在第一期有介绍到词向量的表示,因此,实际上将自然语言输入到网络中就是将一个一个词或字通过向量表示输入到模型当中。
以一个简单的RNN为例,每次输入前一个时间点的token,模型将生成语料中下个词出现的概率分布。
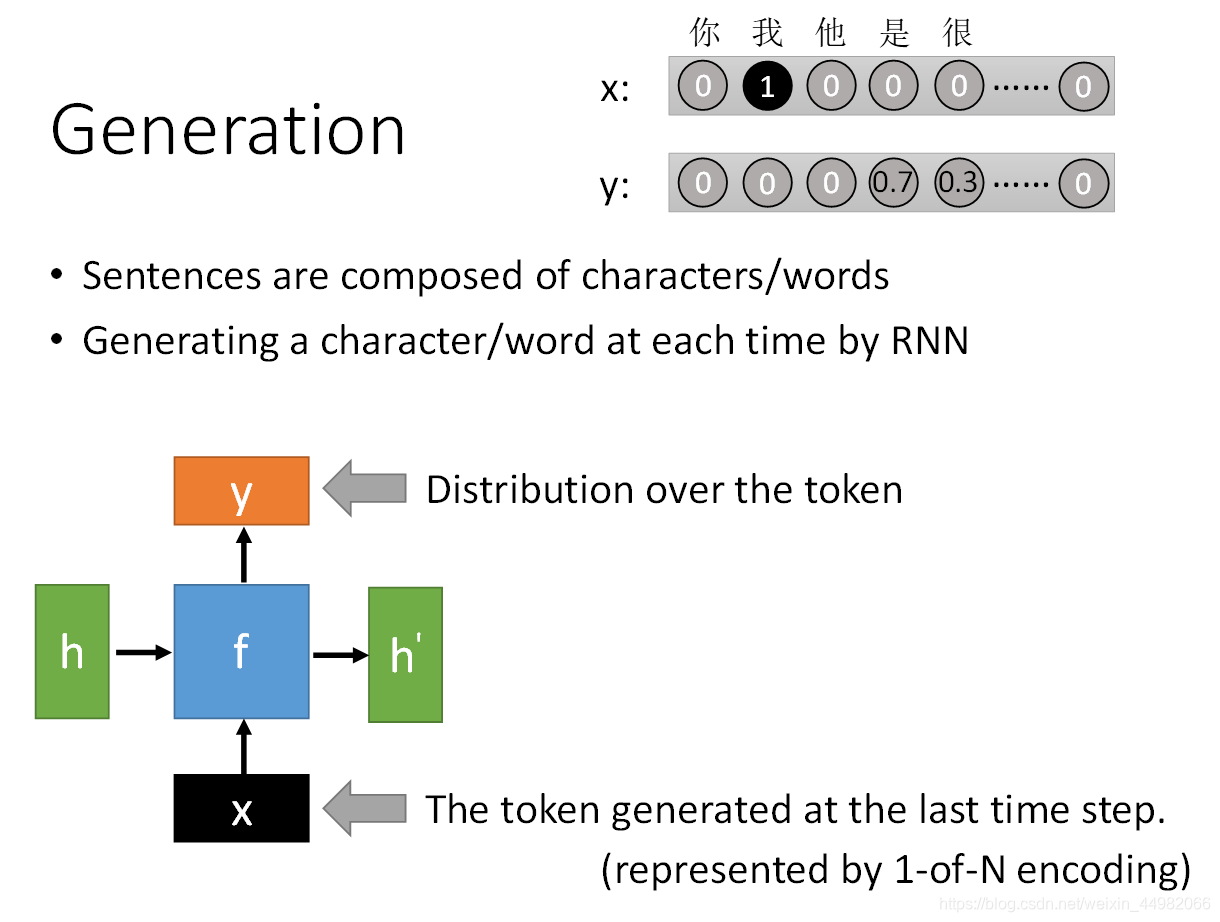
上图中右上角展示了这一过程,假如本次输入的token表示的是 “我”(这里使用的是one-hot表示),那么模型预测下一个应该出现的字是 “是” 的概率为0.7,“很” 的概率是0.3。
完整的过程便是:在序列输入开始时我们需要先输入<BOS>(Begin OF Sequence)到RNN,模型之后会输出第一个词的概率。接着,将此次输出进行词语选取,作为下一次RNN的输入。直到最后模型输出生成<EOS>(End OF Sequence),整个过程结束。
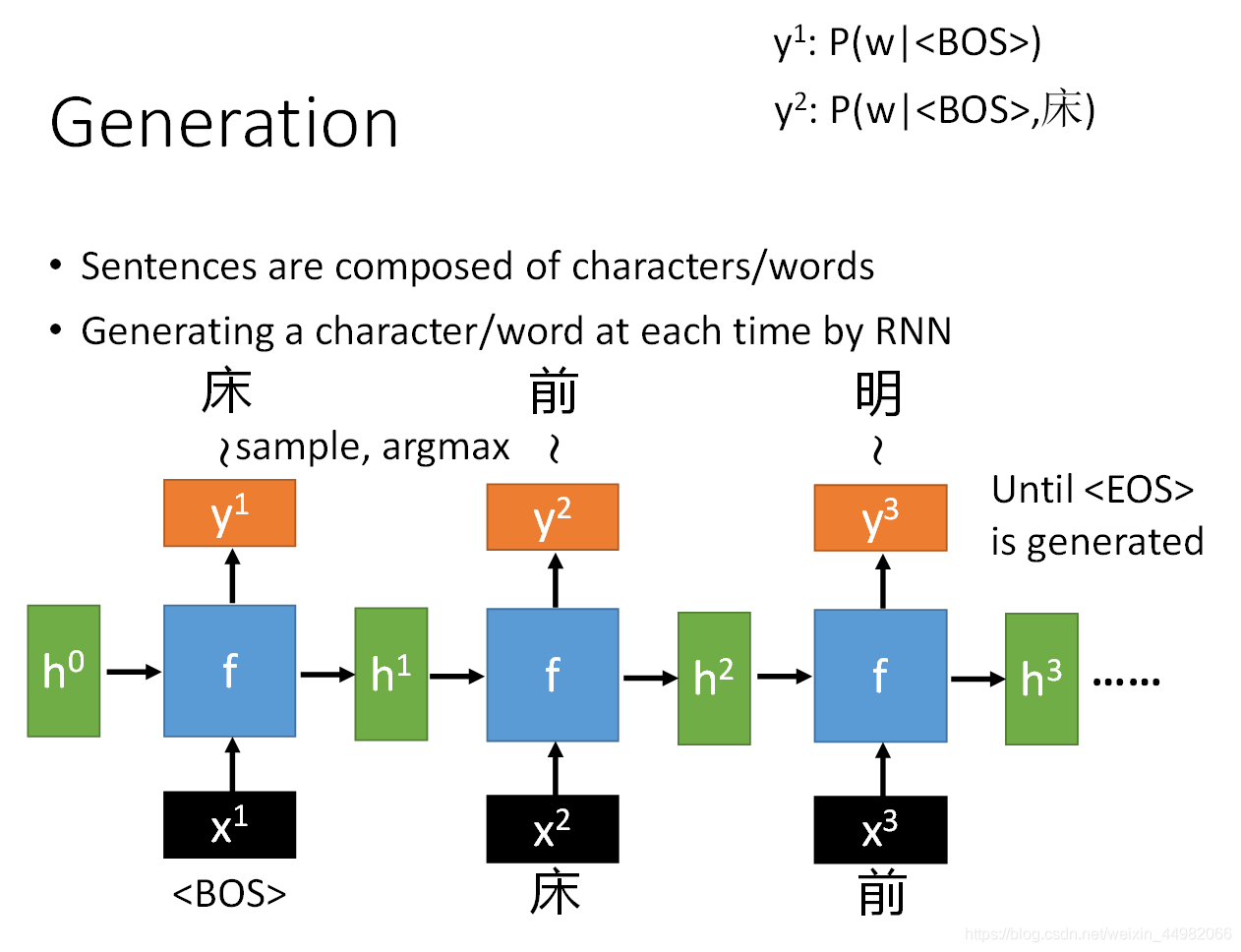
对于最后选取词的策略这里主要有两种方法:
- 一种是sample,意思是按照概率分布随机选取词语,这样每次输出可能会不一样,但是会让机器看起来更灵活,但是有可能出现类似概率分布词输出时会出现语法错误;
- 另一种是argmax,即取概率最大的词输出,这样每次输出都一样。
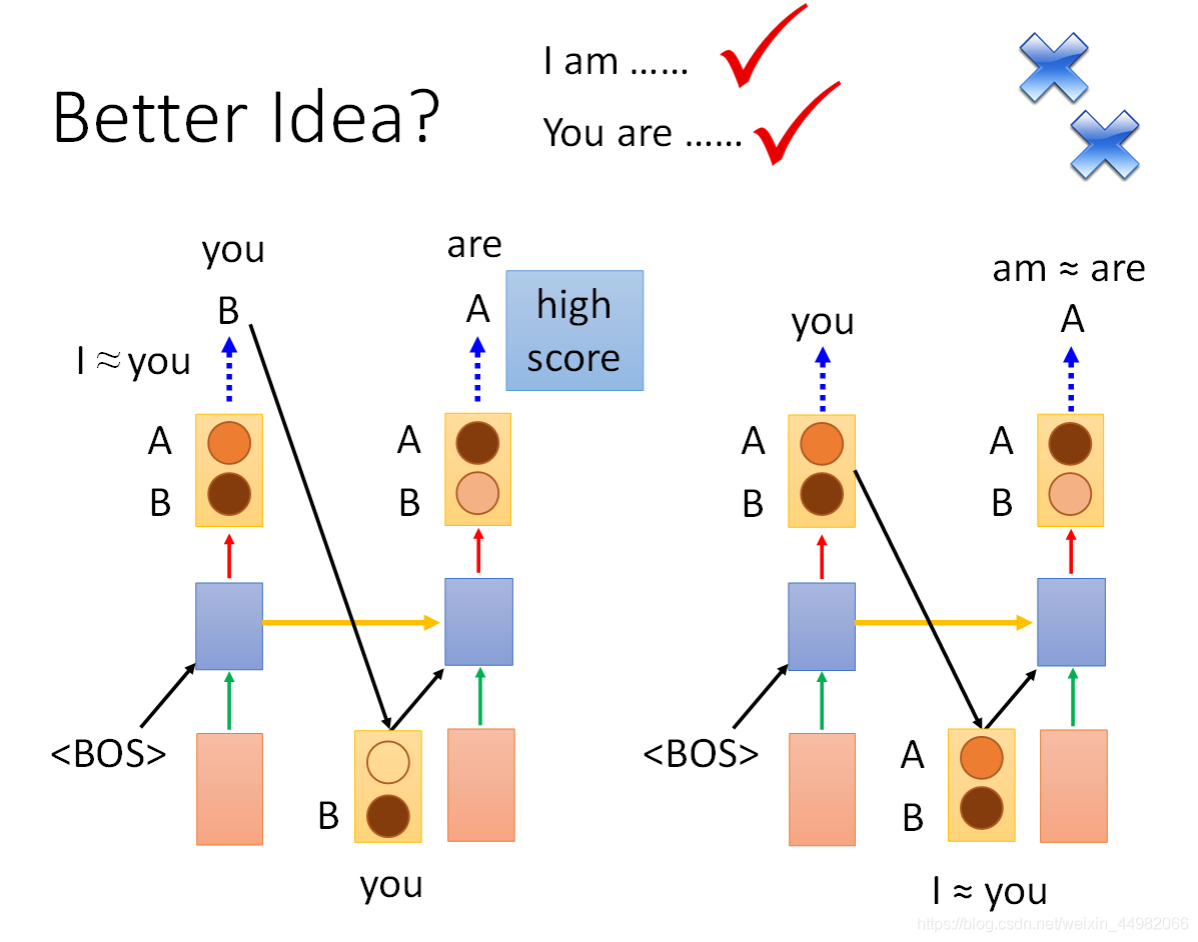
上图中,如果采用sample方式,那么am和are可能都有较高的概率分布,很有可能出现主谓语法错误。
介绍完序列生成模型,我们来说说如何训练这个模型。其实也很简单,让序列输入的RNN输出的概率分布和训练数据的one-hot计算交叉熵,目标函数就是最小化交叉熵。实际上就是将对的输出概率往1靠拢,错误的输出概率往0靠拢。
最后,这里虽然以简单的RNN举例,但实际上现在大多数都使用LSTM作为结构主体了。
Seq2Seq Model
我们先来分析一下上面介绍的模型有何不足之处:
- 不能处理序列是不定长的情况。如果序列长度未知,这个模型不知道什么时候该输出/,那么很有可能模型将一直输出下去,出现错误。
- 即使能够训练出一个模型,但是在实际使用时它只能随机生成语句,并不能根据输入进行特定的输出。
- 使用词袋作为输入时往往会丢失掉语句的顺序关系,这会造成句意上的歧义。
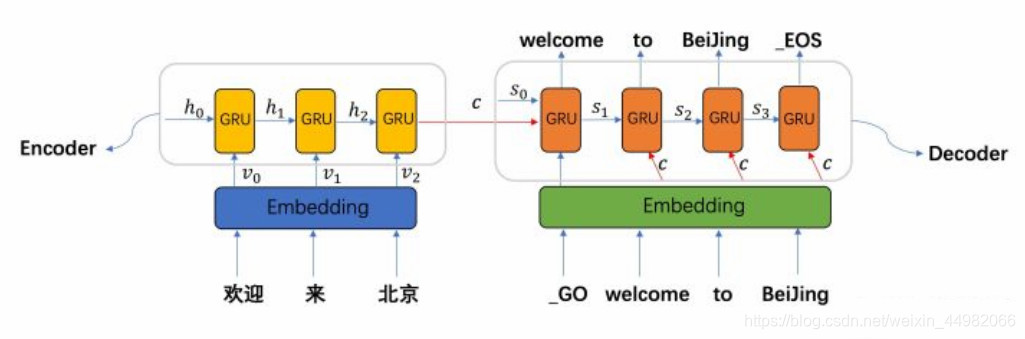
所以我们需要的是一个有条件的序列生成模型。针对上述问题,Seq2Seq Model被提出。采用自编码器的思想,模型分为encoder和decoder两个部分。而编解码器内部的结构就是RNN。encoder部分相当于将序列处理为固定长度向量(Seq2Vec),decoder部分则是将向量再处理回序列(Vec2Seq)。
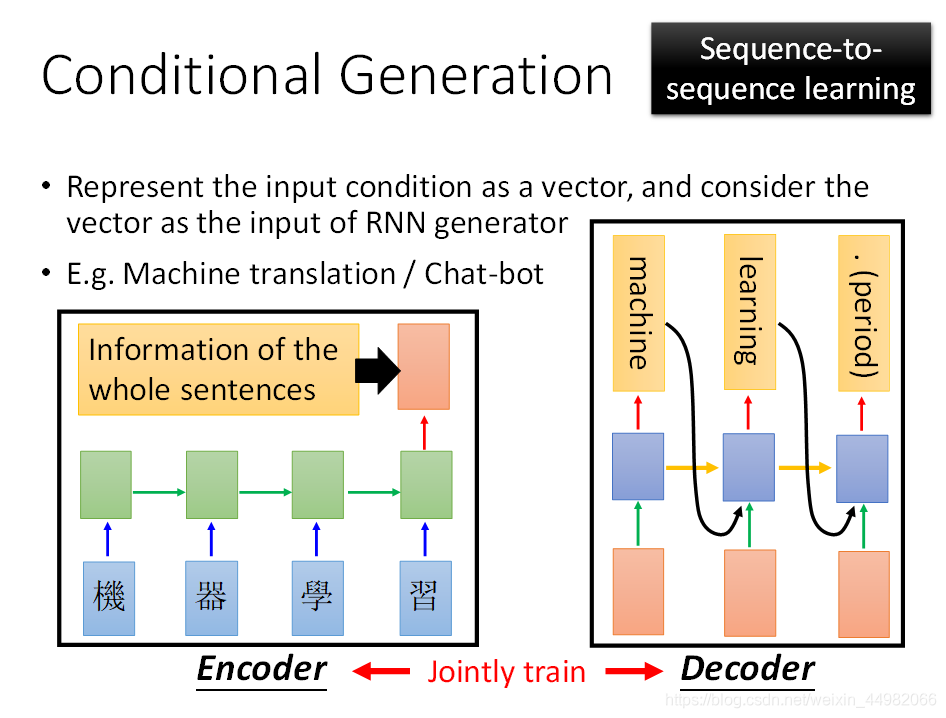
上图是一个举例,这里以机器翻译作为应用场景,当我们将 “机器学习” 四个字输入到编码器后,编码器将包含整个语句信息的输出交给解码器,解码器再进行序列生成,输出“machine learning.”。
这里我们稍微深入探讨一下编解码的方式。上图是直接拿RNN最后一次运算的隐含状态作为编码,但实际上也可以是将这个隐藏状态进行一个变换作为编码,还可以对RNN所有存在过的隐藏状态进行计算作为编码。

其次解码的方式也可以是不同的:可以将编码只作为第一步RNN输入使用,也可以在每一步输入中都使用。

同时编码器结构也可以进行堆叠,将各个句子分别经过各自的编码器后再进行一次编码,这样做可以根据历史上下文作出新的反应,而不会产生重复输出。
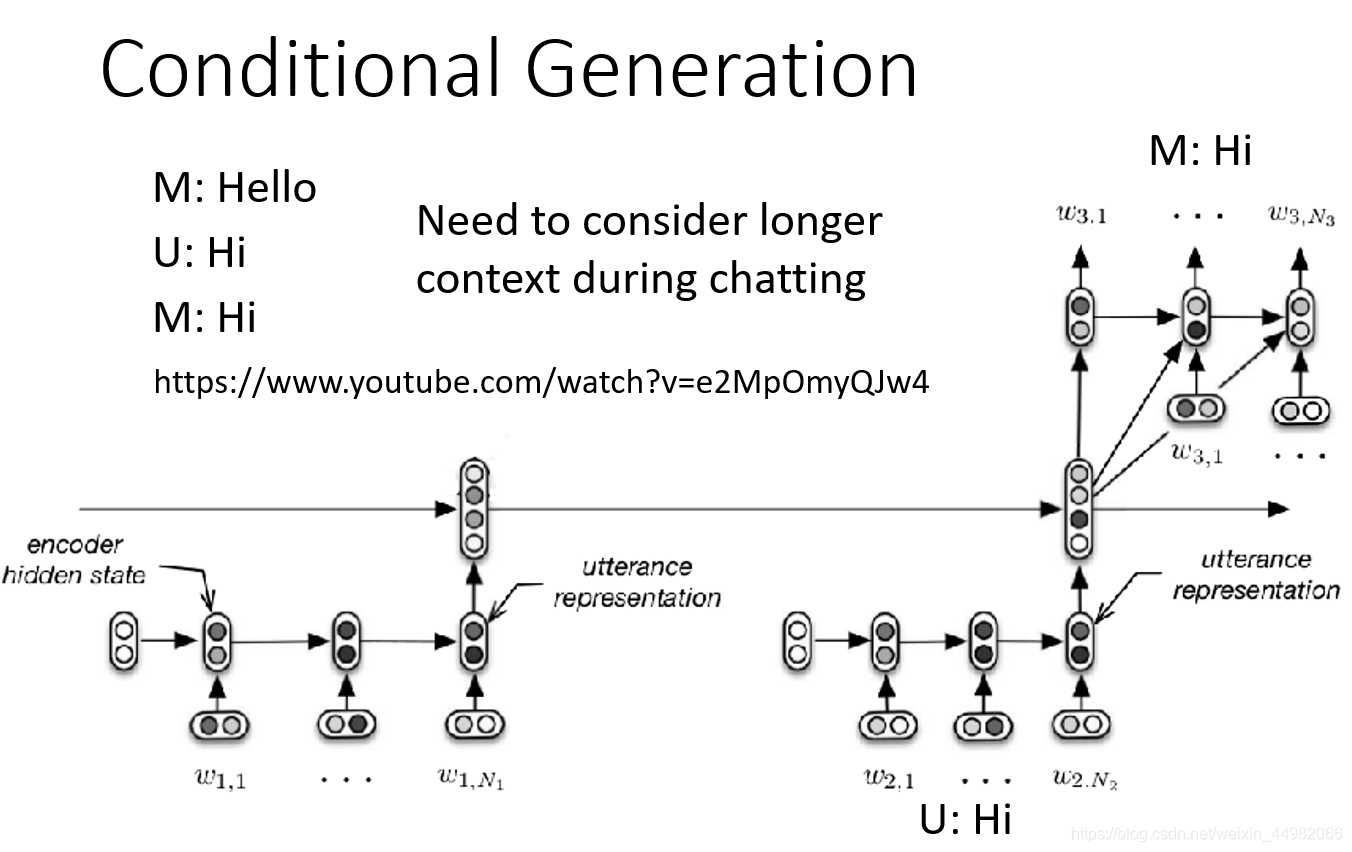
另外为了避免解码时错误的累积,可以在编码过程中添加参考输入,称为Teacher Forcing。在训练过程中,使用要解码的序列作为输入进行训练,但是在inference阶段不能使用。这一思想在transformer中也有所体现,transformer将在下一篇博客中介绍。
Attention-based Model
Seq2Seq Model需要一个固定长度的context向量来编码所有语义,这个是很困难的,要记住每一个细节是不可能的。简而言之,就是用一个向量记住整个语义是很困难的。
类似于人脑进行思考时,更多会将注意力集中在更加重要的地方,attention机制的思想即是让解码器每一步运算时自行选择需要关注的编码,此时编码器的RNN所有存在过的隐藏状态都会存下来以供解码器挑选,解码器每一次选择的编码输入也将不同。至于如何做到自行选择这一步,实际上就是网络需要训练的参数了,换言之,是学习得来的。
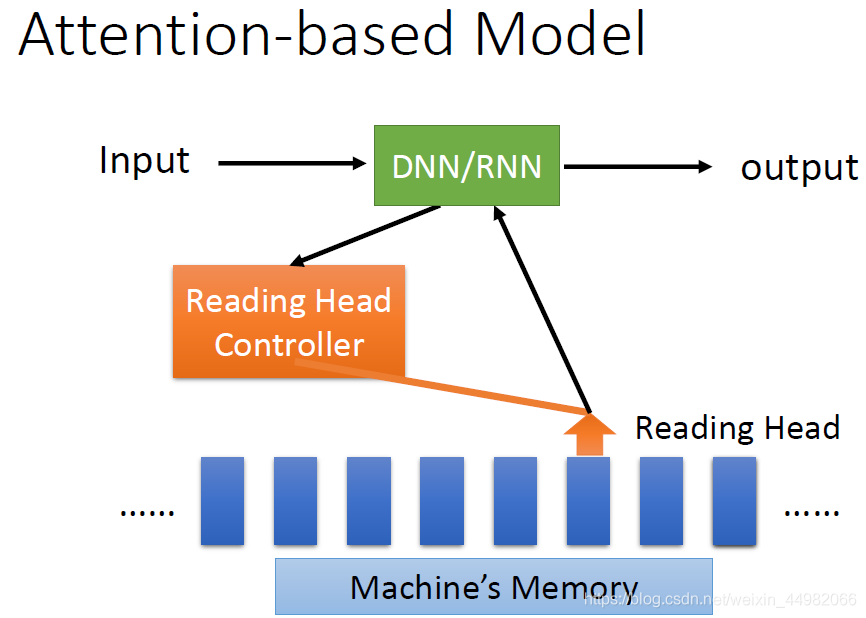
接下来我们介绍这种具体的运算机制:
- 计算输入输出匹配度:以decoder第0时刻的运算为例,首先设置一个网络参数z也被称为key,然后与每一次encoder的输出(或者隐藏状态)计算匹配度(match操作)得到α。
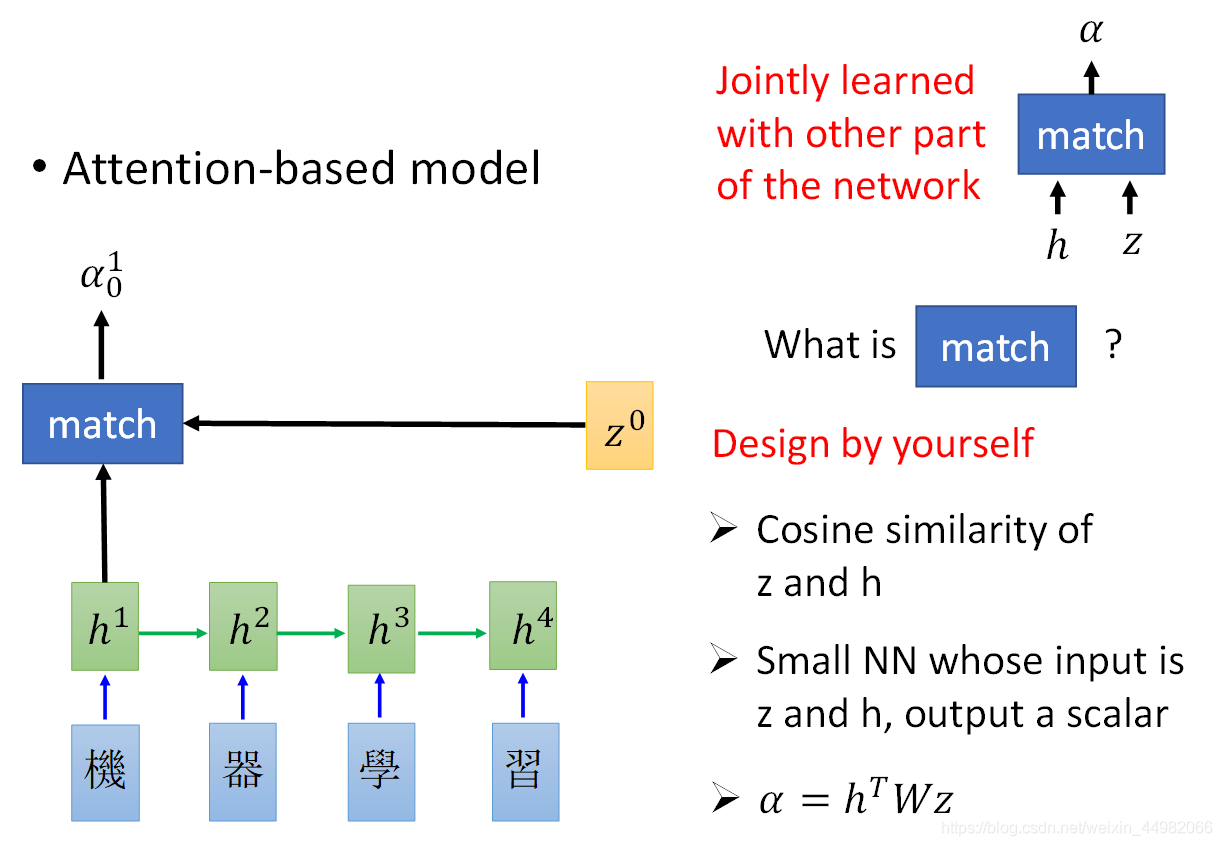 match操作可以是:
match操作可以是:
- 计算余弦相似度;
- 训练一个神经网络;
- 进行矩阵变换: 。
- 得到各个匹配度后通过softmax层计算出最终的权重,这样就可以将encoder的输出加权得到c,作为decoder在第0时刻的输入了。下一时刻的key通过上一时刻的c和z计算得到,循环进行,直到结束。
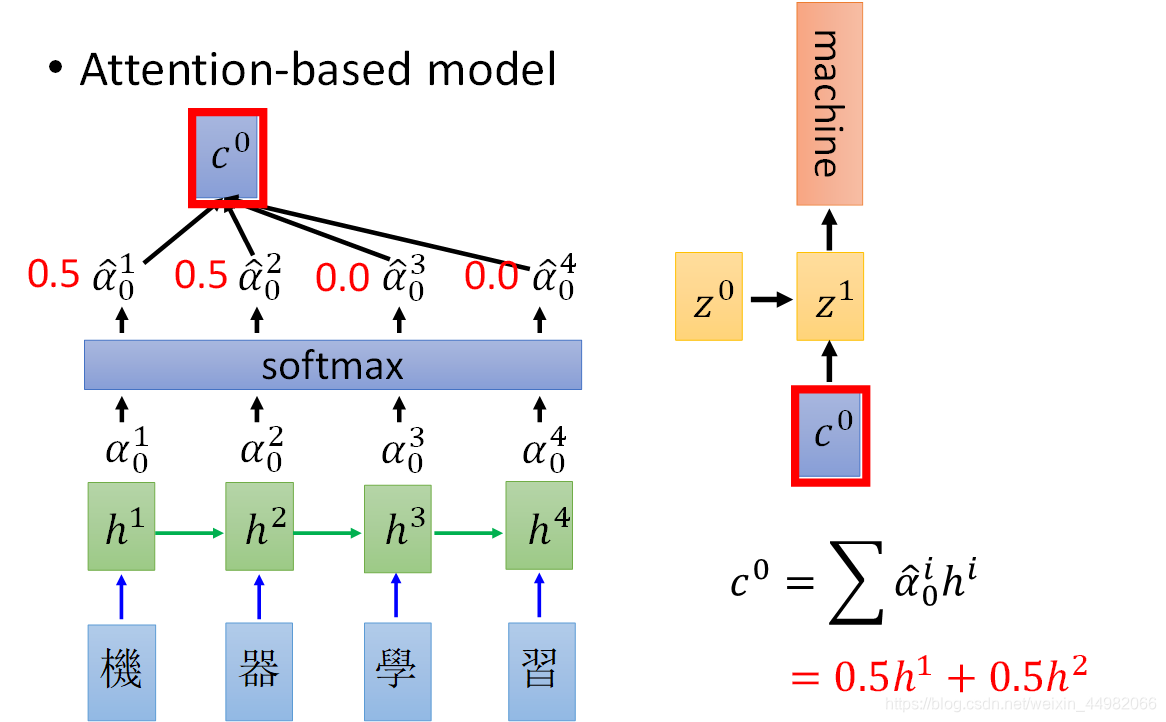

相关论文公式总结如下:
接下来讨论一下这种机制存在的一些问题:
上面的模型在训练和测试时会出现分布不一致的情况。这是因为训练时我们将正确的答案作为输入到RNN中,但测试时模型会将错误的生成作为输入,这时就会导致后续输出不一致。
究其原因,训练时,模型只记住了指定一部分正确的分支选择,测试时一旦错误的生成将会进入未知的分支,这样模型就会表现出没有被训练的状态。
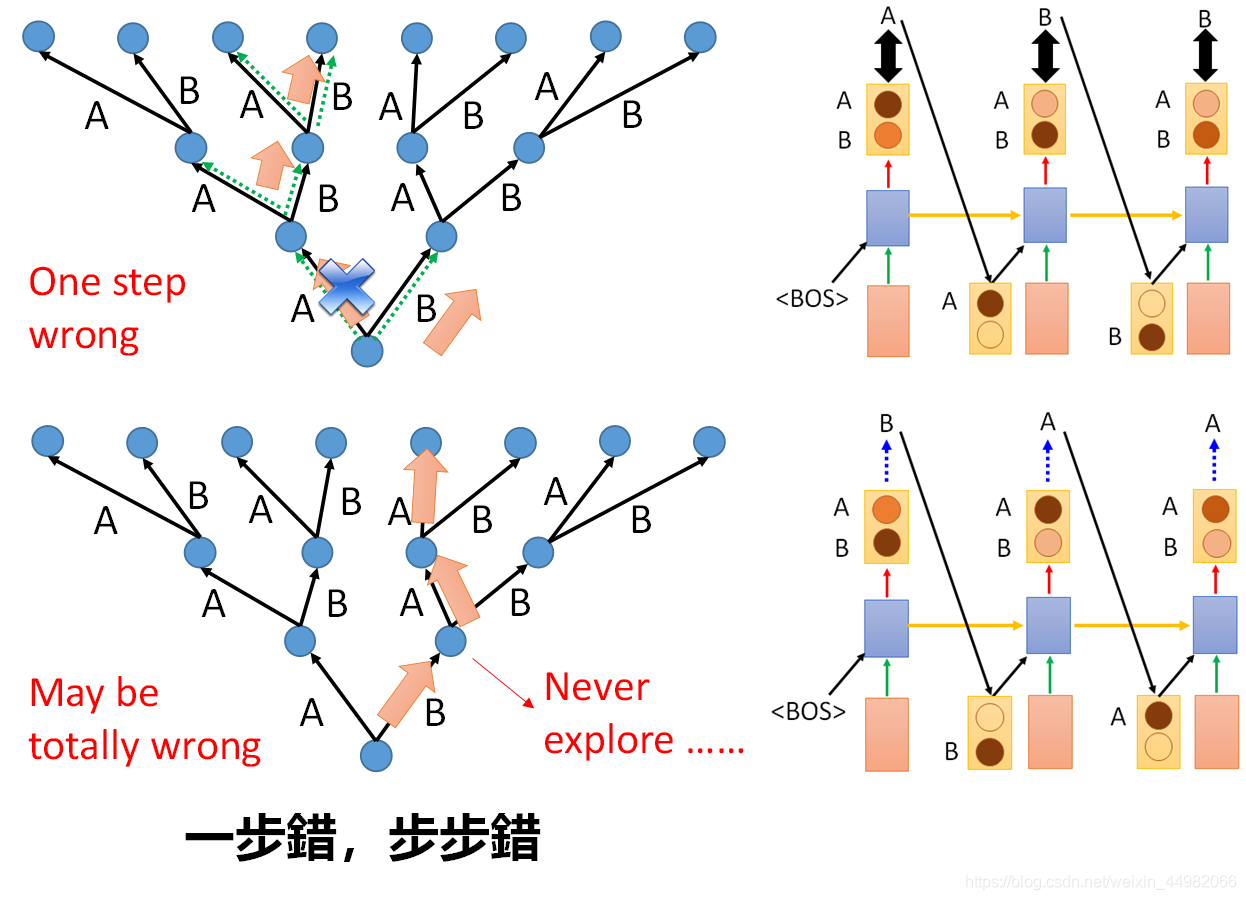
解决这个问题有这样一些方法:
- 训练时将模型的输出作为下一个输入,但是这样没有解决本质问题,还是会出现进入未知分支的情况。
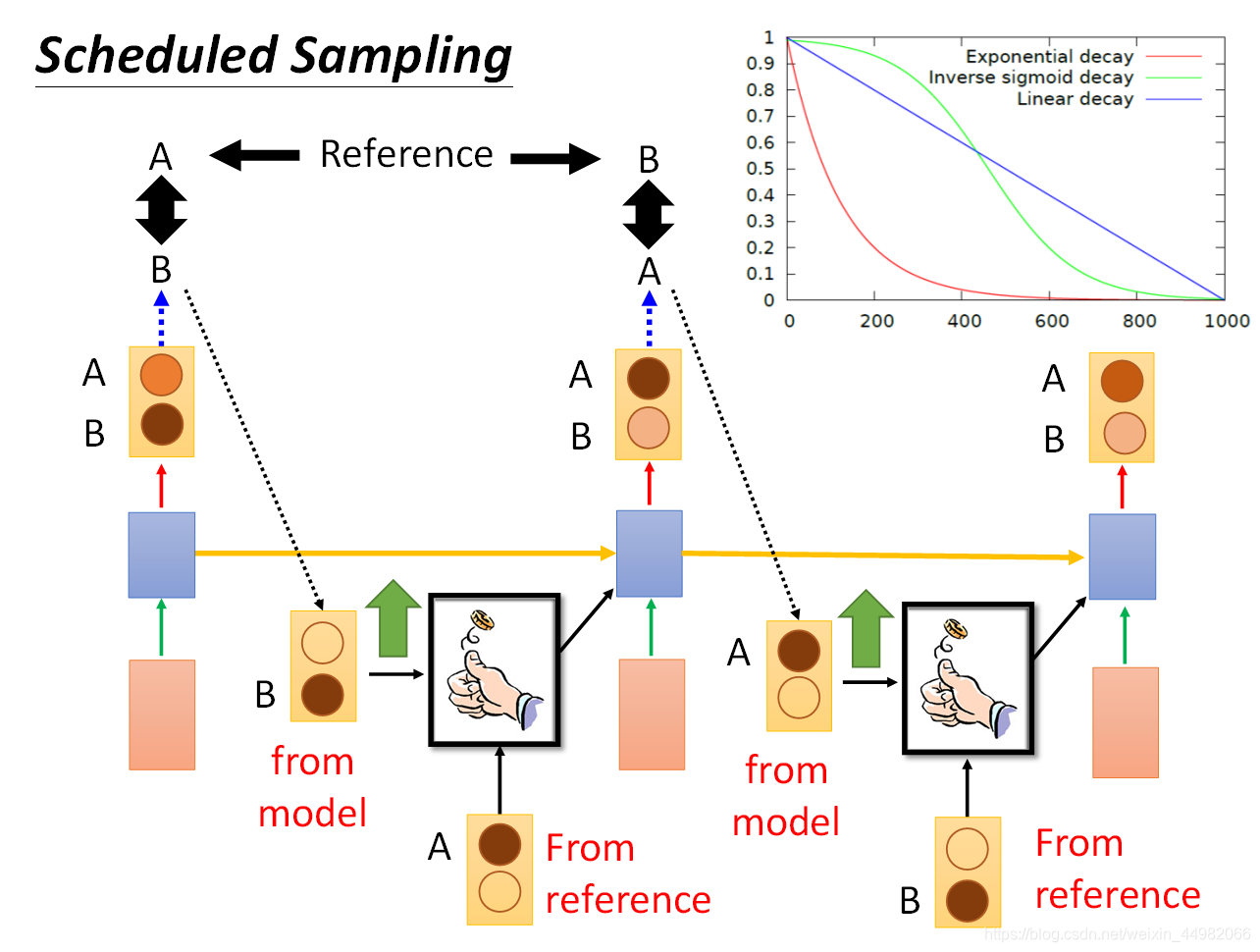
- Scheduled sampling:下一个输入按照概率选择是正确答案或模型输出,可以在训练最开始时正确答案的几率高,随后模型输出的几率越来越高。
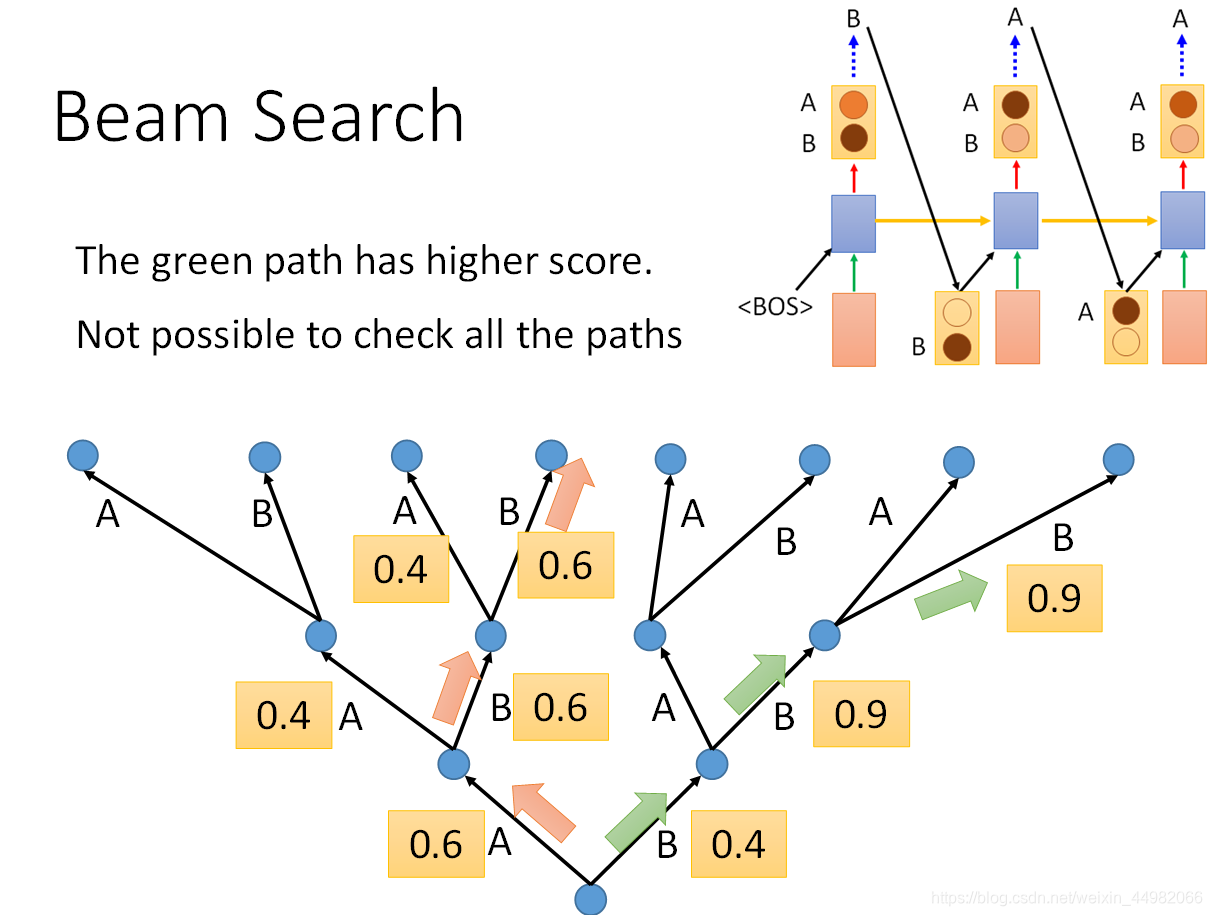
- Beam search:由于联合概率最高才是最好的选择路径,RNN每次选择概率较高的路径从全局来看未必是最优解。因此每次生成序列时,保留前n个分数最高的可能。当然,这种办法仅在测试时使用有效。