参考资料 :
https://radimrehurek.com/gensim/models/word2vec.html
接上篇 :
import jieba
all_list = jieba.cut(xl['工作内容'][0:6],cut_all=True)
print(all_list)
every_one = xl['工作内容'].apply(lambda x:jieba.cut(x))
import traceback
def filtered_punctuations(token_list):
try:
punctuations = [' ', '\n', '\t', ',', '.', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%',':',
'/','\xa0','。',';','、']
token_list_without_punctuations = [word for word in token_list
if word not in punctuations]
#print "[INFO]: filtered_punctuations is finished!"
return token_list_without_punctuations
except Exception as e:
print (traceback.print_exc())
from gensim.models import Doc2Vec,Word2Vec
import gensim
def list_crea(everyone):
list_word = []
for k in everyone:
fenci= filtered_punctuations(k)
list_word.append(fenci)
return list_word
aa_word = list_crea(every_one)
print(type(aa_word))
#aa_word 是 个 嵌套的list [[1,2,3], [4,5,6], [7,8,9]]
model = Word2Vec(aa_word, min_count=1) # 训练模型,参考英文官网,在上面
say_vector = model['java'] # get vector for word
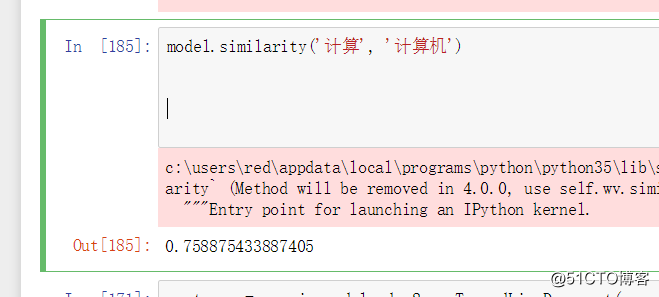
model.similarity('计算', '计算机')