Word2vec 算法
CBOW 和 Skip-Gram模型

CBOW通过周围词找到当前词,Skip-Gram通过当前词找到周围词,都是使用评估概率找到概率最大的
doc2vec
在word2vec的基础上增加一个段落向量,该模型也有两个方法:Distributed Memory(DM) 和 Distributed Bag of Words(DBOW)
doc2vec 的c-bow与word2vec的c-bow模型的区别
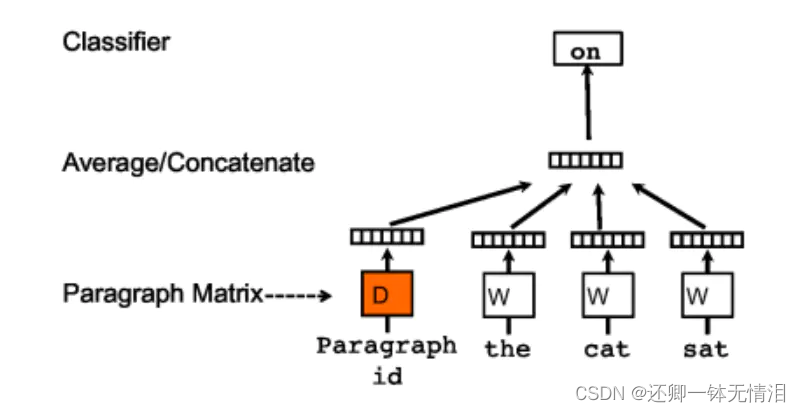
在训练过程中增加了每个句子的id(向量),计算的时候将paragraph vector和word vector累加或者连接起来,作为softmax的输入
在预测过程,给预测句子分配一个新的paragraph id , 重新利用梯度下降训练待预测的句子,待收敛后,即得到待测句子的paragraph vector
PV-DM
doc2vec的skip-gram与word2vec的skip-gram模型的区别
在doc2vec里,输入都是paragraph vector ,输出是该paragraph 中随机抽样的词
PV-DBOW

补充知识
One-hot Representation
采用稀疏方式存储,给每个词分配一个数字 ID,表示后配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务
缺点 任意两个词之间都是孤立的,光从这两个向量中看不出两个词是否有关系,容易发生维数灾难
Distributed representation
从原始的词向量稀疏表示法过渡到低维空间中的密集表示
决了维数灾难问题,并且挖掘了word之间的关联属性
Reference