2.4 图像取样和量化
无论是哪种获取图像的方法,我们的目的都是从感知的数据生成数字图像。多数传感器的输出是连续的电压波形,这些波形的幅度和空间特性都与感知的物理现象有关。为了产生一幅数字图像,我们需要把连续的感知数据转换为数字形式。这种转换包括两种处理:取样和量化。
2.4.1 取样和量化的基本概念

如图(a)显示了一幅连续图像f,目标是把它转换为数字形式。一幅图像的 x 和 y 坐标及幅度可能都是连续的。为将它转换为数字形式,必须对坐标和幅度都进行取样操作。对坐标值进行数字化称为取样,对幅值数字化称为量化。
图中(b)的一维函数是图(a)中沿线段 AB 的连续图像幅度值(灰度级)的曲线。随机变化是由图像噪声引起的。为了对该函数取样,我们沿线段 AB 等间隔地对该函数取样,如图©所示。每个样本的空间位置由图形底部的垂直刻度指出。样本用函数曲线上的白色小方格表示。这样的一组离散位置就给出了取样函数。然而,样本值仍(垂直)跨越了灰度值的连续范围。为了形成数字函数,灰度值也必须转换(量化)为离散量。图©右侧显示了已分为8个离散区间的灰度标尺,范围从黑到白。垂直刻度标记指出了赋予8个灰度的每个特定值。通过对每个样本赋予8个离散灰度级中的一个来量化连续灰度级。赋值取决于该样本与一个垂直刻度标记的垂直接近程度。取样和量化操作生成的数字样本如图(d)所示。从该图像的顶部开始逐行执行这一过程,会产生一幅二维数字图像。图中意味着除了所用的离散级数外,量化所达到的精度强烈地依赖于取样信号的噪声。
数字图像的质量在很大程度上取决于取样和量化中所用的样本数和灰度级。
2.4.2 数字图像表示
令 f(s, t) 表示一幅具有两个连续变量 s 和 t 的连续图像函数。通过取样和量化,可以把该函数转换为数字图像。假设把这幅连续图像取样为一个二维阵列 f(x, y) ,该阵列包含有 M 行和 N 列,其中(x, y)是离散坐标。规定:x = 0, 1, 2,···, M-1 和 y = 0, 1, 2,···, N-1。这样数字图像在原点的值就是 f(0, 0),通常,图像在任何坐标(x, y)处的值记为 f(x, y),其中 x 和 y 都是整数。由一幅图像的坐标张成的实平面部分称为空间域,x 和 y 称为空间变量或空间坐标。
有三种基本方法表示 f(x, y),如图所示。

图(a)是一幅函数图,它用两个坐标轴决定空间位置,第三个坐标是以两个空间变量 x 和 y 为函数的 f (灰度)值。虽然可以在这个例子中用该图来推断图像的结构,但++通常复杂的图像细节太多,以至于很难由这样的图像去解译++。
图(b)是更一般的表示。它显示了 f(x, y) 出现在监视器或照片上的情况。这里,每个点的灰度与该点处的 f 值成正比。
图©是第三种表示方法,将 f(x, y) 的数值简单地显示为一个阵列(矩阵)。在这个例子中,f 的大小为 600*600 个元素,或 360000 个数字,打印整个矩阵很麻烦,且传达的信息也不多,然而,在开发算法时,当图像的一部分被打印并作为数值进行分析时,这种表示相当有用。
图像显示(如图(b))允许我们快速地观察结果。数值阵列(如图©)用于处理和算法开发。
数字图像的原点位于左上角,其中正 x 轴向下延伸,正 y 轴向右延伸。
用更正式的数学术语表达取样和量化:令 Z 和 R 分别表示整数集和实数集。取样处理可视为把 xy 平面分为网格的过程,网格中的每个单元的中心坐标是笛卡儿积 Z2 中的一对元素,Z2 是所有有序元素对 (zi, zj) 的集合。zi 和 zj 是 Z 中的整数。因此,如果 (x, y) 是 Z2 中的整数,且 f 是把灰度值(即实数集 R 中的一个实数)赋给每个特定坐标对 (x, y) 的一个函数,则 f(x, y) 就是一幅数字图像。显然,这种赋值过程就是前面描述的量化处理。如果灰度级也是整数,则用 Z 代替 R,然后,数字图像变成一个二维函数,且其坐标和幅值都是整数。
数字化过程要求针对 M 值、N 值和离散灰度级数 L 做出判定。对于 M 和 N,除了必须取 ++正整数++ 外没有其他限制。然而,出于存储和量化硬件的考虑,++灰度级数通常取为 2 的整数次幂++, 即
L = 2^k
通常,将 L 个灰度值缩放至区间 [0, 1] 对于计算或算法开发目的是有用的,这时,它们不再是整数。++但多数情形下,这些值都会被缩放到用于图像存储和显示的整数区间 [0, L-1]++。
我们假设离散灰度级是等间隔的,且它们是区间 [0, L-1] 内的整数。有时,灰度跨越的值域非正式地称为动态范围。这里,将图像系统的动态范围定义为系统中最大可度量灰度与最小可检测灰度之比。原则上,上限取决于饱和度,下限取决于噪声。基本上,动态范围由系统能表示的最低和最高灰度级来确定,因此,这也是图像具有的动态范围。
将一幅图像中最高和最低灰度级间的灰度差定义为对比度。当一幅图像中像素可感知的数值具有高动态范围时,那么我们认为该图像具有高对比度。
存储数字图像所需的比特数 b 为
b = M * N * k
当一幅图像有 2k 个灰度级时,实际上通常称该图像为一幅 “k 比特图像”。例如,有 256 个可能的离散灰度值的图像称为 8 比特图像。
2.4.3 空间和灰度分辨率
取样值是决定一幅图像空间分辨率的主要参数。空间分辨率 是图像中可辩别的最小细节的度量。在数量上,空间分辨率可以有很多方法来说明,其中单位距离的线对数 和 单位距离的点数(像素数) 是最通用的度量。广泛使用的图像分辨率的定义是:单位距离内可分辨的最大线对数量。单位距离的点数是印刷和出版业中常用的图像分辨率的度量。在美国,这一度量通常使用 每英寸点数(dpi) 来表示。很多时候讨论线对,主要是为了说明反应原始场景中的细节的能力。
类似地,灰度分辨率 是指在灰度级中可分辨的最小变化,是主观指标。
降低图像空间分辨率的效果说明

如上图所示,通过降低一幅图像的空间分辨率,得到的低分辨率的图像与原图像相比要小。为了比较细节方面的差异,通过复制行或列使抽样后的图像复原到原来的大小,即针对 512*512 图像为例,将第0行复制得到新的第1行,将原来的第1行作为新图像的第2行,同时将此行复制作为新图像的第3行,以此类推。如下图所示:

为了比较细节方面的差异,在另一个例子中将降低空间分辨率的图像都放大到了原图像的大小,如下图所示:

从图中可以看到,降低图像分辨率,会使图像中的信息丢失,当再将图像放大到相同的大小,图像会出现明显的失真。
结论:当改变了图像的取样值,即改变了空间分辨率会影响图像分辨细节的能力。
改变数字图像中灰度级数的典型效果

在上述例子中,保持样本数恒定,将灰度级数以 2 的整数次幂从 256 减少到 2,左边 4 幅图像,从上到下,从左到右,灰度级依次为 256、128、64、32 ;右边的 4 幅图像,从上到下,从左到右,灰度级依次是 16、8、4、2(二值图像)。
同时,在上图红色方框框住的区域在原图中是看不出来的,这种效果是由数字图像的平滑区域中的灰度级数不足引起的,常称为 伪轮廓 ,之所以这样称呼,是因为这些脊状结构类似于地图中的地形轮廓。伪轮廓通常在以 16 或更少级数均匀设置的灰度级显示的图像中十分明显。例如:当原图的灰度级是 256 时,两个位置的像素值只差 1 , 则在图像显示上不会有太大的差异,依旧观察不出来;但是当灰度级变为 8 时,两个位置的像素值相差 1 ,则会有明显的差异,因此也就产生了 伪轮廓。
除此之外,随着灰度级的减少,会使原始图像中具有不同灰度级的像素,在新图像中具有相同的灰度级。
研究同时改变空间分辨率和灰度分辨率对图像质量的影响
通过同时改变图像的空间分辨率和灰度分辨率,得到结论:对于有大量细节的图像,可能只需要较小的灰度级,即在相同的空间分辨率下,改变灰度级对于图像的主观偏爱度没有明显改善。最可能的原因是 灰度级 k 的减小倾向于对比度的明显增加,人们通常感受到图像质量改变了的视觉效果。
2.4.4 放大和收缩数字图像
这两种操作与取样量化一幅数字图像之间的关键区别是放大和收缩是用于数字图像。取样量化针对的是模拟图像,对其取样量化得到数字图像。
采用复制行/列可以实现整数倍的放大图像,采用删除行/列可以实现整数倍的缩小图像,但两种方法都无法实现任意倍数和任意位置的放大和缩小图像。
放大和收缩数字图像要求执行两步操作:
- 计算新的像素在原图的对应位置;
- 为这些对应位置赋灰度值。
计算新的像素的对应位置
- f(x,y) 表示输出图像,g(u,v) 表示输入图像。几何运算(图像的放大或缩小也是图像的几何运算)可定义为:
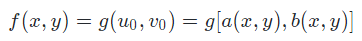
- 如果令:u0 = a(x,y) = x; v0 = b(x,y) = y。那么仅仅是把 g 拷贝到 f 而不加任何改动的恒等运算。
- 如果令:u0 = a(x,y) = x + x0; v0 = b(x,y) = y + y0。那么得到平移运算,其中点 (x0,y0) 被平移到原点。
- 如果令:u0 = a(x,y) = x/c; v0 = b(x,y) = y/d。那么会使图像在 x 轴方向放大 c 倍,在 y 轴放大 d 倍。
例如:将一幅 200x200 的图像 g(u,v) 放大 1.5 倍,那么将得到 300x300 的新图像 f(x,y)。产生新图像的过程,实际就是为 300x300 的像素赋值的过程。
假如为 f(150,150) 赋值 f(150,150) = g(150/1.5,150/1.5) = g(100,100);
假如为 f(100,100) 赋值 f(100,100) = g(100/1.5,100/1.5) = g(66.7,66.7)。由于图像像素都是在整数坐标中,所以没有坐标值为 (66.7,66.7) 的像素。所以要采用 插值 的方法给其赋值。
为对应位置赋灰度值(插值)
- 因为 (u0, v0) 不一定要在坐标点上,故需要插值求 g(u0, v0);
- 方法 1:最近邻内插
取点 (u0, v0) 最近的整数坐标 (u, v)。在上述例子中,为了求 (66.7, 66.7) 的灰度值,则用 (67, 67) 的灰度值来做插值。 - 方法 2:双线性插值
根据四个邻点的灰度值通过插值计算 g(u0, v0)。 - 方法 3:更多邻点的内插(更高次内插,这种方法往往能取得更为精确的结果,但是相应的计算量也会更大)。
2.4.5 图像内插
内插 是在诸如放大、收缩、旋转和几何校正等任务中广泛应用的基本工具。本质上,内插是用已知数据来估计未知位置的数值的处理。
1. 最近邻内插
把原图像中最近邻的灰度赋给了每个新位置。这种方法简单,但可能产生认为缺陷,例如某些直边缘的严重失真。由于这一原因,实际上这种方法并不常用。
2. 一维线性内插
如图所示:

假设我们已知坐标 (x0, y0) 与 (x1, y1),现在要得到 [x0, x1] 区间内某一位置 x 在直线上的值。根据图中所示,我们得到:
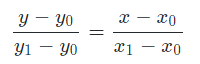
如果令
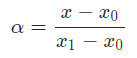
则
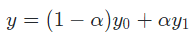
3. 双线性内插
实质上是在两个方向上分别做了一维线性插值。如下图所示:

其中 0 <= α,β <= 1。
如图中所示,(u0, v0) 是放大缩小图像后新像素点的坐标,但其坐标值不是整数,因此可以通过双线性内插方法在计算该处的灰度值,即计算 g(u0, v0) 。由以上假设可知,(u0, v0) 一定落在原图像中四个邻近的像素点 (u’, v’)、(u’, v’+1)、(u’+1, v’)、(u’+1, v’+1) 之间,以此为前提使用双线性插值方法。
具体做法:首先,在 u 方向上固定 v=v’,由于 (u’, v’)、(u’+1, v’) 处的灰度值 g(u’, v’)、g(u’+1, v’) 已知,即得到了如图所示平面 [g(u’, v’) , g(u’+1, v’) , (u’+1, v’) , (u’, v’)] ,在此平面上使用一维线性插值方法得到 g(u0, v’):
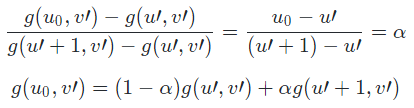
同理在平面 [g(u’, v’+1) , g(u’+1, v’+1) , (u’+1, v’+1) , (u’, v’+1)] 使用一维线性插值方法得到 g(u0, v’+1):
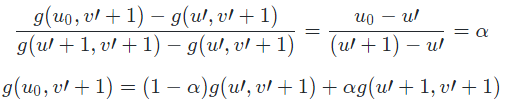
然后固定 u=u0,在 v 方向上使用一维线性插值方法,即在平面 [g(u0, v’) , g(u0, v’+1) , (u0, v’) , (u0, v’+1)] 上使用一维线性插值方法计算得出 g(u0, v0):
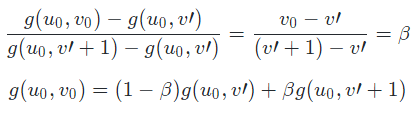
最终得:
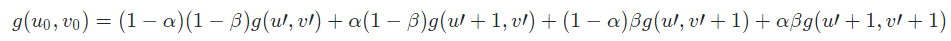

如上图所示,将 64X64 大小的图像放大为 512X512 大小的图像时,对比邻近插值和双线性插值的效果,可见由于使用邻近插值,新像素点将直接被赋值为最近邻的像素点的灰度值,因此在图中会有很多区域的像素值是相同的,在图像显示上呈现出很多的方格;使用双线性插值虽然增加了计算量,但有效地避免了上述情况的发生,放大后的图像效果明显优于邻近插值的效果。
当图像从 32X32 大小放大到 512X512 大小时,上述对比将更加明显,如下图所示:

4. 双三次内插
双三次内插方法的复杂度较高,它包括 16 个最近邻点,赋予点 (x, y) 的灰度值是使用下式得到的:
4. 双三次内插
双三次内插方法的复杂度较高,它包括 16 个最近邻点,赋予点 (x, y) 的灰度值是使用下式得到的:
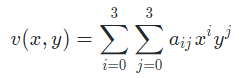
式中,16 个系数可用由点 (x, y) 的 16 个最近邻点写出的未知方程确定。通常,双三次内插在保持细节方面比双线性内插相对要好。双三次内插是商业图像编辑程序如 Adobe Photoshop 和 Corel Photopaint 的标准内插方法。
注意
尽管更高次数的插值方法随着复杂度的提高,变换后生成的新图像的效果更好,但由于其计算复杂度的提升,并没有被最广泛的使用。在大多数图像几何变换的过程中,双线性插值方法折中了计算复杂度和变换效果,是使用最为广泛的图像插值方法。
在内插中,有可能采用更多的邻点和更复杂的技术。例如,采用 样条 和 小波,在某种情况下,可以得到比刚刚讨论的方法更好的结果。对于三维图形和医学图像处理,保留精细细节特别重要,而对于普通数字图像处理,较少考虑额外的计算负担,所以双线性内插和双三次内插是人们选择的典型方法。
式中,16 个系数可用由点 (x, y) 的 16 个最近邻点写出的未知方程确定。通常,双三次内插在保持细节方面比双线性内插相对要好。双三次内插是商业图像编辑程序如 Adobe Photoshop 和 Corel Photopaint 的标准内插方法。
注意
尽管更高次数的插值方法随着复杂度的提高,变换后生成的新图像的效果更好,但由于其计算复杂度的提升,并没有被最广泛的使用。在大多数图像几何变换的过程中,双线性插值方法折中了计算复杂度和变换效果,是使用最为广泛的图像插值方法。
在内插中,有可能采用更多的邻点和更复杂的技术。例如,采用 样条 和 小波,在某种情况下,可以得到比刚刚讨论的方法更好的结果。对于三维图形和医学图像处理,保留精细细节特别重要,而对于普通数字图像处理,较少考虑额外的计算负担,所以双线性内插和双三次内插是人们选择的典型方法。
