(首先说明一下我只是个大四在读学生,在自学深度学习,期间遇到很多问题,通过各种资料解开了疑问。写这篇博客的目的是加深对理论的理解,同时也希望能给和我一样存在疑问的初学者一些参考。所以请各位大佬在看到错误的时候指出来,不胜感激!)
学过深度学习的小伙伴们想必对神经网络的工作原理都有所了解。这里拿用于分类的神经网络举例。它通过一层层神经元,将输入的数据不断进行特征提取,将数据映射成一列概率值,并由这个概率值给出一个分类判断。同时以一定的损失函数为目标函数,通过求偏微分以及梯度下降或牛顿方法来对神经元权重参数进行优化,在经过多次迭代后,让神经元变得适合这类数据,从而以尽可能小的损失来对样本进行分类。
在神经网络的工作流程中,有一步激活函数的运算,相信不只是我一个人觉得这个概念抽象。激活什么,为什么要激活,为什么对于分类问题,前面都可以用ReLu,但最后却要用softmax?
其实这一过程主要是增加神经网络对训练集的拟合程度,将线性(隐层第一步的WX+b)转变成非线性,从而加大了神经网络的灵活度。拿ReLu激活函数来说,它把小于0的值映射成0,不仅增强了非线性,还在减小了过拟合程度。
比较典型的激活函数有ReLu,Sigmoid,Softmax和ReLu的变体。(当然还有其他的,本文不做讨论)。对于Sigmoid函数来说,在神经网络刚发展起来的时候,这确实是一个被广泛利用的激活函数,但随着发展,它的弊端也慢慢暴露,其中最为致命的就是它的“梯度消失现象”。
Sigmoid函数图像(梯度消失现象):

我们知道神经网络是通过求偏微分实现神经元的反向传播,而在图中,当 x>5或者x<-5 的时候,Sigmoid函数的导数几乎为0,这将导致神经元无法继续进行反向传播,因此这个函数慢慢被看似简单的ReLu激活函数代替了。
而本文想介绍的主要内容并不是中间层的激活函数,而是分类神经网络最后全连接层所接的激活函数(通常是Softmax),以及Softmax与Sigmoid之间的联系和分类原理。
这里先介绍按顺序几个概念:
①指数分布族
②广义线性模型(GLM)
③多项式分布
指数分布族
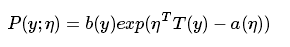
其中:η代表分布的自然参数
T(y)代表充分统计量(几乎任何一本概率论或统计学书中都有介绍)
a, b 是两个函数
那么给定了a, b, T, 对于参数η, 上式定义了一类概率分布。
(对于一般的高斯分布或伯努利分布来说,T(y)=y)
那么对于伯努利分布(只有0,1两种类型的取值,通常对服从这类分布的数据进行二分类任务):
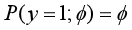
一般形式:
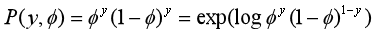
(y只能取0,1,将y = 0或1代入上式,就能得到伯努利分布,于是这个式子将两种情况考虑在一起,表达更漂亮)
将上式进一步推导,可以得到:
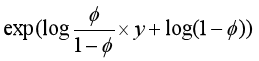
于是我们令
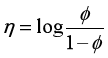
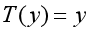

那么可以得到这属于一个指数分布族。通过η的式子我们可以得到:
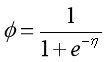
(看到这个形式与Sigmoid函数十分类似,我们在介绍完广义线性模型之后会将它转变成Sigmoid函数的形式)
广义线性模型
我们首先做出广义线性模型的三个假设:
①对于参数θ,y|x;θ 是指数分布族;(满足即可用广义线性模型拟合)
②给定一个 x,我们需要的目标函数为hθ(x)=E[T(y)|x];
③参数η与输入特征X之间的关系为:
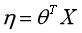
那么在这个假设的前提下,对于伯努利分布,有:
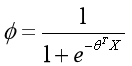
这就是Sigmoid函数,显然可以看出在如上前提中,对于伯努利分布,y = 1的概率就是这样一个函数,这也是Sigmoid函数的工作原理,对于二分类任务,它将输入特征X映射成概率值。而神经网络在不断反向传播中,优化的就是它的参数θ。
下面我们进入正题,讨论softmax函数的来源和工作原理。
在实际问题中,我们很多时候遇到的并不是简单的二分类任务。那么在面对多分类任务的时候,要把特征映射成概率值,我们需要的就是softmax函数。
先来介绍第三个概念。
多项式分布
考虑样本共有kk类,每一类的概率分别为ϕ1,⋯,ϕkϕ1,⋯,ϕk,由于∑i=1kϕi=1∑i=1kϕi=1,所以通常我们只需要k−1个参数即ϕ1,⋯,ϕk−1ϕ1,⋯,ϕk−1。
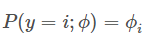
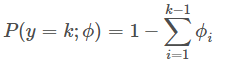
我们引入如下列向量:
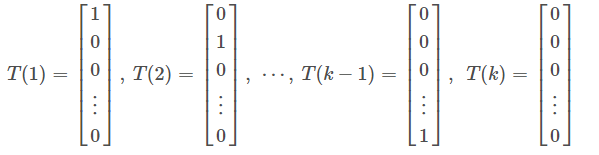
其中T(i)中,第i个值为1,其余值为0.(类似计算机中对k个类别进行编码)
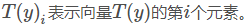
引入表达式1{⋅} ,如果大括号里面为真,则表达式结果为1,否则为0。(类似布尔型变量)
那么上述向量组可以表示为:
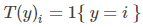
我们来证明可以用广义线性模型拟合多项式分布。
证明多项式分布可以表达成指数分布族的形式:
推导过程如下:
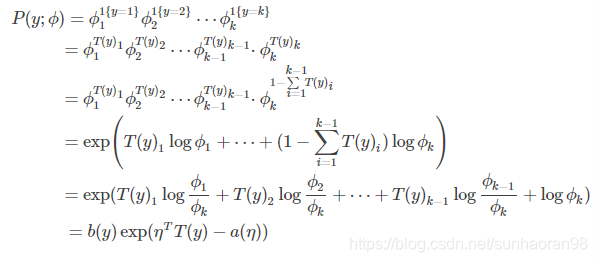
其中
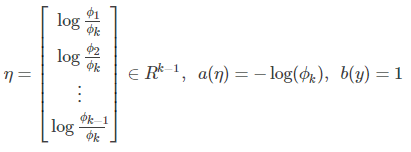
由指数分布族的定义,我们可以知道多项式分布可以转换成指数族分布的形式。由广义线性模型推导出的目标函数hθ(x)即为Softmax回归的分类模型。
Softmax函数
在使用广义线性模型拟合这个多项式分布模型之前,需要先推导一个函数,这个函数在广义线性模型的目标函数中会用到。这个函数叫做Softmax函数。
由η的表达式可得:
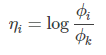
把它转化为ϕi关于ηi的表达式过程为:
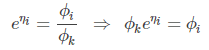
这里注意i的取值范围是(1,2,…,k-1)
(虽然很多地方将i的取值直接取到k,并且softmax函数一般形式也就是在这个前提下推导出来的,但过程并不严谨,这里给出较为严谨的推导结果。)
由上式:
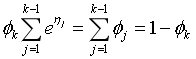
而由广义线性模型的假设③,
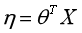
我们可以最终推导出ϕi的严格表达式:
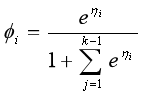
从而:
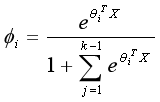
而这种表达较为麻烦,目前常用的softmax函数将i的取值去到k,那么会有这样的结论:
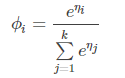
这是一般softmax函数的表达式,故softmax函数工作原理也是将输入特征映射成一个概率向量,如十分类任务,会映射成一个十维概率向量,softmax激活函数就是做了这样一件事,然后我们把概率值最大的变成1,其余变成0,就变成了我们之前定义的编码向量T(y).
softmax激活函数和softmax回归的区别
很多小伙伴都问我这两个概念是不是一个东西,解释起来也比较麻烦,就在这里顺带提一下。
对于softmax回归,根据广义线性模型的假设②:

就是输出了x∈{1,2,⋯,k−1}中每一类的概率,当然属于第k类的概率就是:
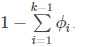
softmax回归做的事情是通过对数似然函数产生θ的极大似然估计(对数似然函数如下)
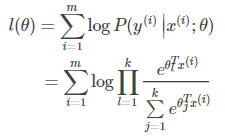
一般采用梯度下降或牛顿法来寻求对数似然函数的极小值,从而对参数进行估计。
(这里的参数θ其实是一个矩阵)
而softmax激活函数对参数的优化则是通过优化交叉熵损失函数的,函数如下:
通过一些列复合函数求偏导经过神经元一步步传递优化权重参数实现参数优化,这两个概念之间并无太多交集,只是用的函数都是softmax函数。
(本文不讨论两种方法参数优化的详细过程,softmax回归请参考任意数理统计书中极大似然估计部分和数值计算中牛顿法和梯度下降策略;神经网络优化参考https://blog.csdn.net/softdiamonds/article/details/80101440)
最后和没学过神经网络理论直接上手编程的小伙伴们解释一下batch,batch_size,epoch的概念。
比如有10000个图片,计算机无法一次计算这么大的数据,我们一般选择128,或64个数据为一个batch,128或64就是一个batchsize。我们将10000个数据分成几个batch进行迭代,每个batch迭代完优化一次参数,所有样本迭代一遍为一个epoch(这个例子中,若选择64为batchsize,那么一个epoch就是(10000/64)取整+1 个batch,权重参数在一个epoch期间也是更新了这些次,对于剩余样本不足一个batch的情况,我们在所有样本中随机抽取补满这个batch。如果将epoch值设成10次,意味着所有样本基本上都要迭代10遍(被抽到补位的样本被迭代的次数要多一些)。
