-
Kafka是一个分布式流平台(消息系统)。
-
Kafka用于流处理,网站活动跟踪,指标收集和监视,日志聚合,实时分析,CEP,将数据导入Spark,将数据导入Hadoop,CQRS,重播消息,错误恢复和保证分布式 提交用于内存计算(微服务)的日志。
-
Kafka is used for real-time streams of data(实时数据流的处理), to collect big data, or to do real time analysis (or both).
-
Kafka is a distributed streaming platform that is used publish and subscribe to streams of records.
-
Kafka是一个分布式流平台,用于发布和订阅记录流---我们可以通过Kafka发布或者获取消息记录。
-
备份机制保证数据安全性:
-
高吞吐、低延迟Kafka is designed to allow your apps to process records as they occur. (让你可以实时操作记录)
-
高效的持久化提供稳定性和速度:Kafka is fast and uses IO efficiently by batching and compressing records.通过批处理和压缩记录来有效地使用IO。
-
Kafka is used for decoupling data streams.(Kafka用于解耦数据流)
-
-
Kafka is used to stream data into data lakes, applications, and real-time stream analytics systems.(可以把数据流送到数据池、应用或者实时数据分析系统,比如Hadoop)
-
高并发
-
-
对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,Kafka是一个可行的解决方案。Kafka的目的是通过并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
Kafka官网:http://kafka.apache.org/
帮助文档页面:http://kafka.apache.org/documentation.html
wiki页面:https://cwiki.apache.org/confluence/display/KAFKA/Index
Kafka结构
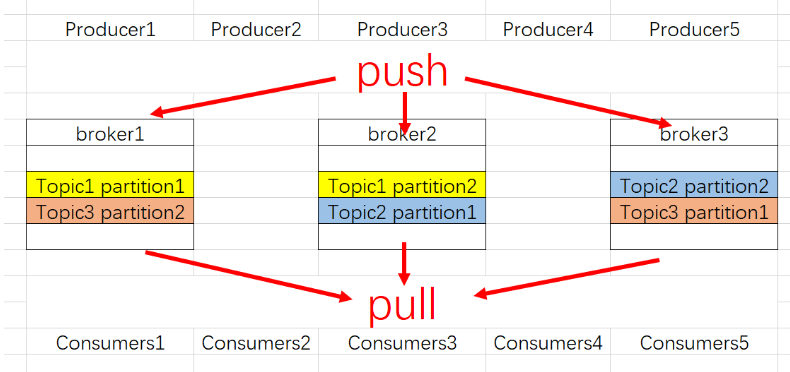
-
Broker: 一个Kafka 集群包含一个或者多个服务器,这些服务器被称为broker。
-
Topic: 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储;逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
-
Partition: topic是分区的(partition),Partition是物理上的概念,每个Topic包含一个或多个Partition。
-
Producer: 消息生产者,负责发布消息到Kafka broker。
-
Consumer: 消息消费者,向Kafka broker读取消息的客户端。
-
Consumer Group: 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Topic
-
每一个topic是一组消息的归纳,kafka对每个topic进行了分区处理(partition)。
-
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。
-
分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
-
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。
-
比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题(只要磁盘够)。
-
-
每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset,通过重新设置该值,可以读取旧的消息数据。
Partition
-
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。
-
每个分区都由一个服务器作为“leader”,零或若干服务器作为“followers”
-
leader负责处理消息的读和写
-
followers则去复制leader
-
如果leader down了,followers中的一台则会自动成为leader。
-
集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,这样集群就会据有较好的负载均衡。
-
-
leader和follower的管理是通过zk集群来进行管理的。
Producer
-
Producer是指Kafka集群的消息生产者。Producer将消息发布(push)到它指定的topic中,并负责决定发布到哪个分区。
-
通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。一般而言,现在比较常用的是第二种方式。
-
Consumer
-
抓取(pull)消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。
-
队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;
-
发布-订阅模式中消息被广播到所有的consumer中。
-
Consumers可以加入一个consumer 组,每个组都有且只有1台服务器能抓取到消息。
-
如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。
-
如果所有的Consumer在同一个组中,就是队列模式。
与Flume的区别