Project Loom是Hotspot Group赞助的项目之一,旨在向JAVA世界提供高吞吐量和轻量级的并发模型。 在撰写本文时,Loom项目仍在积极开发中,其API可能会更改。
Why Loom?
每个新项目可能会出现的第一个问题是为什么? 为什么我们需要学习新的知识,它对我们有什么帮助? (如果确实如此)
因此,要专门针对Loom回答这个问题,我们首先需要了解JAVA中现有线程系统如何工作的基础知识。
JVM内部产生的每个线程都以一个一对一OS内核空间中的相应线程,具有其自己的堆栈,寄存器,程序计数器和状态。 每个线程的最大部分可能是堆栈,堆栈大小以兆字节为单位,通常在1MB到2MB之间。 因此,这些类型的线程在启动和运行时方面都很昂贵。 不可能在一台机器上产生1万个线程并期望它能正常工作。
有人可能会问为什么我们甚至需要那么多线程? 鉴于CPU只有几个超线程。 例如 CPU Internal Core i9总共有16个线程。 好吧,CPU并不是您的应用程序使用的唯一资源,任何没有I / O的软件都只会导致全球变暖! 一旦线程需要I / O,操作系统就会尝试为其分配所需的资源,并同时调度另一个需要CPU的线程。 因此,应用程序中拥有的线程越多,我们可以并行利用这些资源的越多。
一个非常典型的示例是Web服务器。 每个服务器能够在每个时间点处理数千个打开的连接,但是同时处理多个连接要么需要数千个线程,要么需要异步的非阻塞代码(我可能会 write another post in the coming weeks to explain more about 异步的hronous code**) and as mentioned before thousands of OS threads is neither what you nor the OS would be happy about!
How Loom Helps?
作为Project Loom的一部分,一种称为纤维 is introduced. 纤维 also called 虚拟线程,绿线或用户线因为这些名称暗示完全由VM处理,并且OS甚至都不知道存在此类线程。 这意味着并非每个VM线程都需要在OS级别具有相应的线程!虚拟线程s might be blocked by I/O or wait to get a signal from another thread,however,in the meantime the underlying threads can be utilized by other 虚拟线程s!
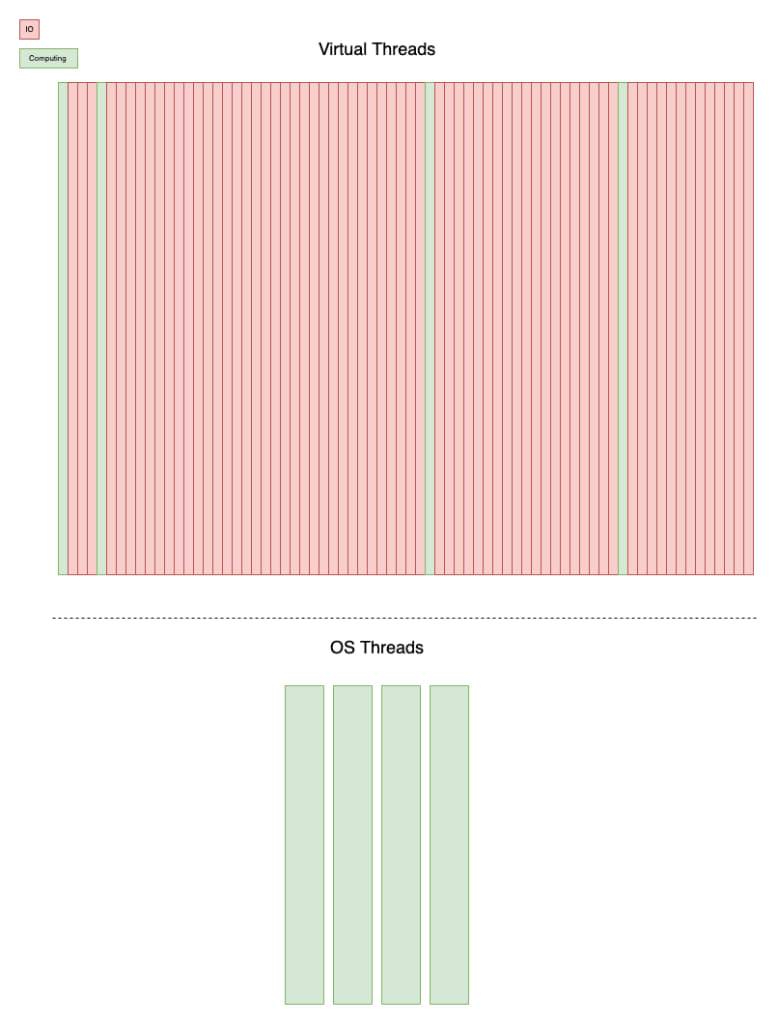
上图说明了虚拟线程和OS线程之间的关系。 虚拟线程可以简单地被I / O阻塞,在这种情况下,基础线程将被另一个虚拟线程使用。
这些虚拟线程的内存占用量将以千字节为单位,而不是兆字节。 如果需要,可以在生成它们之后扩展它们的堆栈,这样JVM不需要为它们分配大量内存。
因此,既然我们有一种非常轻巧的方式来实现并发,我们就可以重新考虑存在于Java经典线程中的最佳实践。
如今,用于在Java中实现并发的最常用的构造是的不同实现执行器服务。 它们具有非常方便的API,并且相对易于使用。 执行程序服务具有一个内部线程池,用于根据开发人员定义的特征来控制可以产生多少个线程。 该线程池主要用于限制应用程序创建的OS线程的数量,因为如上所述,它们是昂贵的资源,我们应该尽可能地重用它们。 但是现在可以生成轻量级虚拟线程了,我们可以重新考虑使用方式执行器服务s也一样
Structured Concurrency
小号tructured concurrency is a programming paradigm, a structured approach to write concurrent programs that are easy to read and maintain. The main idea is very similar to the structured programming if the code has a clear entrance and exit points for concurrent tasks, reasoning about the code would be way easier in comparison to starting concurrent tasks that might last longer than the current scope!
为了更清楚地了解结构化并发代码的外观,请考虑以下伪代码:
void notifyUser(User user) {
try (var scope = new ConcurrencyScope()) {
scope.submit( () -> notifyByEmail(user));
scope.submit( () -> notifyBySMS(user));
}
LOGGER.info("User has been notified successfully");
}
notifyUser方法应该通过电子邮件和SMS通知用户,并且一旦成功完成此方法将记录一条消息。 使用结构化并发,可以保证在两种通知方法完成后立即写入日志。 换句话说,如果尝试范围在其中所有已启动的并发作业都完成了,那么它将完成!
注意:为了使示例简单,我们假设notifyByEmail和notifyBySMS在上面的示例中,请在内部处理所有可能的极端情况,并始终使其通过。
Structured Concurrency with JAVA
在本节中,我将展示如何在JAVA中编写结构化并发应用程序以及如何纤维类一个非常简单的示例将有助于扩展应用程序。
What we are going to solve
想象一下,所有I / O绑定有1万个任务,而每个任务恰好需要100毫秒才能完成。 我们被要求编写高效的代码来完成这些工作。
我们用上课工作以下定义以模仿我们的工作。
public class Job {
public void doIt() {
try {
Thread.sleep(100l);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
First attempt
在第一次尝试中,我们使用缓存线程池和操作系统线程。
public class ThreadBasedJobRunner implements JobRunner {
@Override
public long run(List<Job> jobs) {
var start = System.nanoTime();
var executor = Executors.newCachedThreadPool();
for (Job job : jobs) {
executor.submit(job::doIt);
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
var end = System.nanoTime();
long timeSpentInMS = Util.nanoToMS(end - start);
return timeSpentInMS;
}
}
在此尝试中,我们没有应用Loom项目中的任何内容。 只是一个缓存的线程池,以确保将使用空闲线程,而不是创建新线程。
让我们看看使用此实现可以运行10,000个作业所需的时间。 我使用下面的代码来查找运行速度最快的10个代码。 为简单起见,未使用任何微基准测试工具。
public class ThreadSleep {
public static void main(String[] args) throws InterruptedException {
List<Long> timeSpents = new ArrayList<>(100);
var jobs = IntStream.range(0, 10000).mapToObj(n -> new Job()).collect(toList());
for (int c = 0; c <= 100; c++) {
var jobRunner = new ThreadBasedJobRunner();
var timeSpent = jobRunner.run(jobs);
timeSpents.add(timeSpent);
}
Collections.sort(timeSpents);
System.out.println("Top 10 executions took:");
timeSpents.stream().limit(10)
.forEach(timeSpent -> System.out.println("%s ms".formatted(timeSpent)));
}
}
我的机器上的结果是:
Top 10 executions took:
694 ms
695 ms
696 ms
696 ms
696 ms
697 ms
699 ms
700 ms
700 ms
700 ms
到目前为止,我们有一个代码,最好情况下大约需要700毫秒才能在我的计算机上运行10,000个作业。 让我们这次使用Loom功能实施JobRunner。
Second Attempt (with Fibers)
在执行中纤维类要么虚拟线程,我还将以结构化的方式编写并发代码。
public class FiberBasedJobRunner implements JobRunner {
@Override
public long run(List<Job> jobs) {
var start = System.nanoTime();
var factory = Thread.builder().virtual().factory();
try (var executor = Executors.newUnboundedExecutor(factory)) {
for (Job job : jobs) {
executor.submit(job::doIt);
}
}
var end = System.nanoTime();
long timeSpentInMS = Util.nanoToMS(end - start);
return timeSpentInMS;
}
}
也许关于此实现的第一个值得注意的事情是它的简洁性,如果将其与ThreadBasedJobRunner进行比较,您会发现该代码的行数更少! 主要原因是ExecutorService接口中的新更改现已扩展自动关闭结果,我们可以在try-with-resources范围内使用它。 所有提交的作业完成后,将执行try块之后的代码。
这正是我们用来在JAVA中编写结构化并发代码的主要结构。
上面代码中的另一个新事物是我们构建线程工厂的新方法。 线程类有一个新的静态方法,称为建造者可以用来创建一个线要么线Factory。 这行代码正在做的是创建一个创建的线程工厂Virtual threads。
var factory = Thread.builder().virtual().factory();
现在,我们来看看使用此实现可以运行10,000个作业所需的时间。
Top 10 executions took:
121 ms
122 ms
122 ms
123 ms
124 ms
124 ms
124 ms
125 ms
125 ms
125 ms
鉴于Project Loom仍在积极开发中,并且仍有提高速度的空间,但结果确实很棒。 不论是全部还是部分应用,都可以以最小的努力受益于Fibers! 唯一需要更改的是线程工厂线程池就是这样!
具体来说,在此示例中,应用程序的运行时速度提高了约6倍,但是,速度并不是我们在这里实现的唯一目标!
Although I don’t want to write about the memory footprint of the application that has been drastically decreased by using Fibers, but I would highly recommend you to play around the codes of this post accessible here and compare the amount of memory used along with the number of OS threads each implementation takes! You can download the official early access build of Loom here.
在接下来的帖子中,我将详细介绍Loom引入的其他API项目,以及我们如何将其应用于现实生活中的用例。
请不要犹豫,通过评论与我分享您的反馈!
from: https://dev.to//psychoir/openjdk-loom-and-structured-concurrency-2e0e
