目录
2.1 Fuzzer-driven Taint Inference
2.1.2 Comparison with Traditional Taint Analysis.
2.1.3 Identify Direct Copies of Inputs.
2.2.1 Prioritize Bytes to Mutate
2.2.3 Determine Where and How to Mutate
2.3.2 Conformance-Guided Seed Updating
2.3.3 On-the-fly Mutation Rebase
3.2 Static Analysis and Instrumentation.
6.3 Seed Updating and Selection
Abstract
数据流分析(例如,动态污点分析)已经被证明有助于指导fuzzer探索难以访问的代码并发现漏洞。然而,传统的污点分析是劳动密集型的、不准确的、缓慢的,影响了模糊化的效率。除了污点,很少使用数据流特性。
本文提出了一种数据流敏感的模糊化解决方案greyone,首先利用经典的特征污点来指导模糊化。采用一种轻量级的、合理的模糊驱动的污点推断(fti)方法,通过在模糊过程中改变输入字节的同时监测变量的值变化来推断变量的污点。针对这个问题,我们提出了一个新的输入优先级模型来确定要探索的分支、要变异的字节以及如何变异。此外,我们使用另一个数据流特征约束符合性,即污染变量到未触及分支中预期值的距离,来调整模糊化的演化方向。
我们实现了一个greyone的原型,并在LAVA数据集和19个真实世界程序上对其进行了评估。结果表明,在代码覆盖率和漏洞发现方面,它都优于各种最新的模糊器。在lava数据集中,greyone发现了所有列出的bug,还有336个未列出。在现实世界的程序中,Greyone平均发现了2.12倍的独特程序路径和3.09倍的独特错误比最先进的进化模糊器,包括AFL,Vuzzer,Collafl,Angora和Honggfuzz,而且,Greyone平均发现了1.2倍的独特程序路径和1.52倍的独特错误比最先进的符号解释辅助模糊器Qsym。共发现105个新的安全漏洞,其中41个已被CVE确认。
Introduction
基于进化的变异的模糊算法(如afl[44])已经成为当前最流行的漏洞发现方法之一,并得到了广泛的应用和研究。这类模糊器的核心任务是确定进化方向,以及在何处以及如何变异种子输入,以探索难以访问的代码,并满足复杂的数据流约束以触发潜在的漏洞。一个常见的解决方案是利用符号执行来解决控制流约束,并帮助fuzzer探索代码,如driller[37]、qsym[43]和diggfuzz[45]所提出的。然而,符号执行太重,无法扩展到大型应用程序,也无法解决许多复杂的约束,如单向函数。研究人员还试图通过预测要变异的字节和要采取的变异操作,通过深度学习和强化学习来改进模糊器。然而,它们仍处于早期阶段,改进并不显著。
相反,数据流分析1(例如,动态污点分析)被证明对指导模糊化是有用的。TaintScope[40]利用它来定位校验和。vuzzer[30]使用它来标识分支指令中使用的字节和值。angora[10]使用它来绘制与路径约束相关的输入字节的形状。这些解决方案利用污点来确定在哪里以及如何以不同的方式变异,并在一些应用程序中显示出良好的性能。
1.1questions to address
然而,传统的动态污点分析方法存在一些局限性。首先,这是劳动密集型的,需要大量的人工劳动。例如,vuzzer[30]最初只支持x86平台。通常,这些解决方案必须使用自定义污染传播规则以本机或中间表示形式解释每个指令。他们还必须为外部函数调用或系统调用构建污点模型。其次,这是不准确的。例如,一些受污染的数据值可能会影响控制流,从而进一步影响其他数据,形成隐式数据流。如果隐式流被忽略,则会导致欠污染;如果这些流都被计算在内,则会导致过度污染[19]。最后,它非常慢(通常是管理费用的几倍),使得模糊效率很低。这些严重限制了动态污染分析在模糊控制中的应用和效率。因此,首先要解决的研究问题是:rq1:如何为有效的模糊化执行轻量级和精确的污染分析?
使用推断的污点属性,Vuzzer[30]对分支指令中使用的输入字节进行变异,并不精确地用期望值(例如,幻数)替换它们。redqueen[4]进一步标识了输入的所有直接副本,即直接用于分支约束的输入字节(如幻数和校验和),并用期望值替换它们。然而,它们既不能解决与输入的间接副本(即在分支约束中转换和间接使用的输入字节)相关的分支约束,也不能确定要探索的分支和要变异的字节的优先级。因此,需要解决的第二个研究问题是:rq2:如何有效地引导带有污染的突变?
现有的进化fuzzer一般演变为增加代码覆盖率。例如,afl[44]将发现新代码的测试用例添加到seed队列中,并从队列中一次选择一个进行变异。许多其他的解决方案,如aflfast[6]和collafl[14],被提出来进一步改进选择种子的方式,加速进化速度。然而,他们只考虑控制流特性,而不考虑数据流特性,例如污染属性或约束符合性,并且可能在变异期间浪费能量来探索难以到达的分支。因此,需要解决的第三个研究问题是:rq3:如何根据数据流特性调整模糊器的进化方向?
1.2 our solution
为了解决上述问题,我们提出了一种新的数据流敏感模糊解greyone。
fuzzer驱动污点推断(fti)。我们首先提出fti通过pilot的fuzzer阶段来推断变量的污染,在此阶段,我们系统地改变每个输入字节(一次一个)并监视变量的值。如果变量的值在输入字节发生变化时发生变化,我们可以推断前者受到了污染,并依赖于后者。
这个推论是合理的,即没有过度污染的问题。它还对由隐式流或外部调用引起的不足污染问题免疫。实验表明,fti比传统的污染分析更准确,例如,能够找到2到4倍的依赖关系(没有假阳性)。此外,它避免了编写污染传播规则的劳动密集型工作,并且在运行时非常快速。这个轻量级的、可靠的解决方案可以扩展到大型程序,并为除模糊之外的其他应用程序场景提供支持。
污染导向突变。输入字节对代码覆盖率的贡献不同。我们利用fti提供的污点对输入字节进行排序。更具体地说,我们优先考虑影响更多未触及分支得的输入字节的变异,并使得依赖于更高优先级输入字节的未触及分支优先。当探索一个分支时,我们按照优先级顺序改变它的依赖输入字节,精确地用期望值(和较小的变化)替换输入的直接副本。
符合导向的进化。许多fuzzer(例如afl)使用控制流特性(例如代码覆盖率)来指导进化。为了有效地探索难以触及的分支(例如,那些与输入的indirect copies相关的分支),我们建议使用互补的数据流特征来调整演化方向。注意,对于未触及分支中使用的每个受污染变量,我们需要翻转一些位以匹配预期值。所需的工作量与符合约束有关,即受污染变量与未触及分支中预期值的距离。
我们使用这个数据流特性来调整模糊器的进化方向。首先,在种子队列中加入符合性较高的测试用例,使模糊器逐步提高整体符合性,最终满足非触及分支的约束。然后,对一符合较高的种子进行优先排序,从队列中选择变异种子,加速新分支的探索。这种进化可以更快地满足约束条件,就像Angora使用的梯度下降[10]。但它可以避免陷入局部极小值,带来长期稳定的改善。此外,我们将正在进行的突变重新定位到新的种子上,并在运行中获得更高的符合性。实验表明,该方法显著提高了突变效率。
1.3 result
我们实现了greyone的原型,并在lava-m数据集和19个开源应用程序上对其进行了评估。
我们的污染分析引擎fti优于经典的污染分析解决方案dfsan[2]。平均而言,它会发现1.3倍多的未触及分支受到污染(即,取决于输入字节),并在模糊期间生成1倍多的不同路径。
greyone在代码覆盖率和漏洞发现方面都优于6个最新的进化模糊器,包括afl和collafl[14]。在lava数据集中,greyone发现了所有列出的bug,还有336个未列出的bug。在现实世界的应用中,greyone发现了2.12倍的不同路径、1.53倍的新边、6倍的不同崩溃和3.09倍的错误比第二好的fuzzer。此外,greyone在绕过复杂的程序约束方面表现出了非常好的性能,甚至优于最先进的符号执行辅助fuzzer qsym[43]。
在实际应用中,greyone发现的不同路径是qsym的1.2倍,新边是qsym的1.12倍,不同崩溃是qsym的2.15倍,错误是qsym的1.52倍。Greyone总共在这些应用程序中发现了105个未知漏洞。在向上游供应商报告后,我们了解到其中25家供应商是已知的(但不是公开的)。其余80个bug中,有41个被cve证实。总之,我们做出了以下贡献:
我们提出了一种污染导向突变策略,能够优先考虑要探索的分支和要突变的输入字节,并确定如何(准确地)突变。
我们提出了一个新的符合性导向的演化解决方案来调整模糊化的方向,同时考虑到数据流的特性,包括污染属性和约束符合性。
我们实现了一个原型greyone,并在19个广泛测试的开源应用程序上对其进行了评估,结果表明它优于各种最新的fuzzer。
我们在19个应用程序中发现105个未知漏洞,并帮助供应商改进产品。
2 design of greyone

如图1所示,Greyone的整个工作流程与AFL类似,包括种子生成/更新、种子选择、种子变异和测试/跟踪等步骤。
首先,我们在模糊循环中引入一个新的步骤,即fti,来推断变量的污点。通过对输入种子执行字节级变异并对其进行测试,我们进行了一次pilot fuzzer。在pilot fuzzer过程中,我们监控程序变量的值变化。一旦变量的值发生变化,我们就可以推断它受到了污染,并且依赖于变化的输入字节。此外,我们还可以识别所有使用输入直接副本的受污染变量。
其次,利用fti提供的污染属性,进一步引导模糊算子以更有效的方式对种子进行变异。我们对哪些输入字节要变异,哪些分支要探索排序。此外,我们还确定如何改变输入字节,包括输入direct和indirect copies。
最后,我们利用符合性引导进化来调整模糊方向。除了代码覆盖率,我们在测试过程中跟踪受污染变量的约束符合性,并在种子队列中添加具有较高符合性的测试用例,使得模糊器逐渐增加符合性并到达未受影响的分支。然后,我们对符合性较高的种子进行优先级排序,以从队列中进行选择,从而加速进化。此外,一旦我们发现一个新的种子具有更高的符合性,我们就将正在进行的突变重新定位到这个新的种子上在运行中,从而提高突变效率。
2.1 Fuzzer-driven Taint Inference
如[10,30]所示,污点分析可以引导fuzzer走向有效的突变,并帮助探索难以触及的分支。然而,传统的解决方案是劳动密集型的、缓慢的和不准确的。Greyone引入了一个轻量级且可靠的解决方案,即模糊驱动污点推断(FTI)。
直觉。如果一个变量的值在我们改变一个输入字节后发生变化,我们可以推断前者依赖于后者,无论是显式的还是隐式的。此外,更改此输入字节可能会更改使用此变量的分支的约束,从而导致新的分支探索。
Fti关联规则。假设我们有一个程序变量var(在给定的指令行)和一个种子输入s,另一个输入s[i]是通过改变输入s的第i个字节得到的,当给定输入s时,让v(var;s)是var的值。如果以下条件成立,我们声明变量var取决于输入s的第i个字节。
![]()
此外,如果分支指令br的任何一个操作数变量依赖于输入s的第i字节,则我们声明此分支br依赖于此输入字节。换句话说,如果从输入字节到分支的数据流不满足非关联规则[16],则后者依赖于前者。与传统的指令级污染分析(如taintinclude[46])不同,此规则捕获高级依赖项,并且更准确。如后文所述,它具有较少的误报(即过度污染)和假阴性(即污染不足)。
| Algorithm 1 Fuzzing-driven Taint Inference. Input: seed Output: {br,taint[seed]|br∈branches(P)} 1: // Target program is instrumented to collect information, as P' 2: State = Execute(P';seed) 3: for each candidate mutation method Opr do 4: for each available mutation operand Opd do 5: for each position pos in the seed do 6: seed’= Mutate(seed;Opr;Opd; pos) 7: State’= Execute(P';seed’) 8: for br∈uncovered_branches(State) do 9: for var∈br do 10: if State(var) ≠State’(var) then 11: br:taint[seed]∪= {pos} 12: end if 13: end for 14: end for 15: end for 16: end for 17: end for |
2.1.1 Taint inference
根据上述直觉和干扰规则,fti在一个piot模糊阶段推断污染属性,该阶段可与afl的确定性模糊阶段集成,具体步骤如下,如算法1所示。
字节级变异。我们使用一组预定义的变异规则(例如,单比特翻转、多比特翻转和算术运算),一次对种子输入进行一个字节的变异。对于每个种子输入和每个输入偏移位置,可以用这种方式导出一组新的测试用例blm(s,pos)。注意,由于以下原因,我们不会同时改变多个字节。首先,如果多个字节发生变异,导致污染不足或污染过度,我们无法准确确定哪个字节负责潜在的值更改。其次,单字节变异产生的测试用例更少,带来的性能开销更少。
可变值监控。然后,我们将生成的测试用例提供给测试,并在测试期间监视程序变量的值。为了支持监控,我们使用特殊的值跟踪代码对目标应用程序进行检测。注意,我们可以用这种方式监视所有程序变量。但是,为了模糊化的目的,我们只监视路径约束中使用的变量。首先,监控更少的变量要快得多。第二,只有这些变量才会影响路径探索,而仅仅为了探索所有分支而对它们进行监控就足够了。
污点推断。最后,在测试了每组测试用例blm(s,pos)之后,我们检查路径约束中使用的每个变量的值是否保持完整。如果变量var的值发生变化,我们可以推断var受到了污染,并且依赖于输入种子s的pos-th字节。
| 清单1:fti的激励示例 |
| / / magic number : direct copy of input [0:8] vs . constant 2 i f ( u64 ( input ) == u64 ( "MAGICHDR" ) ) { bug1 ( ) ; 4 } 5 / / checksum : direct copy input [8:16] vs . computed val 6 i f(u64 ( input +8) == sum( input +16 , len-16) ) { 7 bug2 ( ) ; 8 } 9 / / length : direct copy of input [16:18] vs . constant 10 i f ( u16 ( input +16) > l e n ) ) { bug3 ( ) ; } 11 / / indirect copy of input [18:20] 12 i f ( foo ( u16 ( input +18) ) = = . . . ) { bug4 ( ) ; } 13 / / implicit dependency : var 1 depends on input[20:24] 14 i f ( u32 (input +20) == . . . ) { 15 var 1 = . . . ; 16 } 17 / / var 1 may change if input [ 2 0 : 2 4 ] change s 18 / / FTI infers : var 1 depends on input [ 2 0 : 2 4 ] 19 i f ( v a r1 == . . . ) { bug5 ( ) ; } |
如清单1所示,它是从redqueen[4]扩展而来,当我们对输入的第20、21、22或23个字节进行变异时,我们可以在第20行的变化处检测分支中使用的变量var1的值。因此,var1依赖于这四个字节。
2.1.2 Comparison with Traditional Taint Analysis.
与传统的污染分析方法相比,fti方法所需的人工操作更少,而且更轻巧、准确。
体力劳动。传统的污染分析(如[20])需要劳动密集型的工作。一般来说,每个指令/语句都必须使用自定义指令特定的污染传播规则进行解释,或者提升/转换为中间表示形式,然后使用一般的污染传播规则进行分析。fti是独立于体系结构的,不需要额外的努力就可以移植到新的平台上。速度。快速道扫描速度很快。首先,它基于静态代码检测,而不是动态二进制检测。其次,它只监视路径约束中使用的变量的值,而不是所有的程序变量。第三,它不需要用自定义规则解释个别指令。
速度。快速道扫描速度很快。首先,它基于静态代码检测,而不是动态二进制检测。其次,它只监视路径约束中使用的变量的值,而不是所有的程序变量。第三,它不需要用自定义规则解释个别指令。
准确度。fti比传统的污染分析方法更准确。其推理规则是合理的。如果一个变量被报告依赖于一个特定的输入字节,那么它很可能是真的。换句话说,它没有过度污染的问题。它也有更少的污染问题。实际上,大多数未受污染的问题都是由无处不在的隐式数据流和外部函数或系统调用的丢失引起的。fti对这些病例免疫。然而,由于字节级变异导致的不完全模糊,fti可能仍然存在不足污染问题。图2展示了FTI的工作原理。与传统的动态污点分析不同,fti可以通过较少的努力来提高精度,而传统的动态污点分析只关注指令,存在着过度污点和不足污点的问题。

正面比较。值得注意的是,最近的几部作品都有类似的想法或类似的结果。taintinclude[46]可以为每个指令推断污染传播规则,而无需手动操作。但由于每条指令都有变异,因此在污点规则推断阶段速度非常慢。profuzzer[42]每次也会改变一个输入字节。但是它监视覆盖范围的变化而不是值的变化,无法推断污染依赖性。mutaflow[26]监视sink api中的更改,并可以判断参数是否被污染。但它关注的是api而不是变量,无法为变量提供精确的污染信息。此外,它缺乏系统的测试,例如fti进行的polit模糊测试,因此有更多的未受污染的问题。
2.1.3 Identify Direct Copies of Inputs.
通常,一些输入字节将直接复制到变量中,并与分支指令中的预期常量或计算值进行比较,如清单1中的第2行(幻数)、第6行(校验和)和第10行(长度检查)所示。这些输入字节应替换为分支中预期的精确值(或类似于±1![]() 的微小变化),以绕过难以到达的路径约束。
的微小变化),以绕过难以到达的路径约束。
fti可以有效地识别输入的所有直接拷贝。对于分支指令中使用的每个受污染变量,我们可以将其与依赖输入字节相匹配。如果它们的值相等,我们将变量报告为输入的直接副本。否则,我们将其报告为输入的间接副本。
2.2 Taint-Guided Mutation
基于变异的fuzzer将以某种方式变异种子输入并生成新的测试用例,以探索新代码并触发潜在的漏洞。Greyone利用FTI提供的污点来确定哪些字节要变异,哪些分支要探索,以及确定如何变异。
2.2.1 Prioritize Bytes to Mutate
如[29]所述,并非所有的输入字节都平等。一些字节应该优先进行变异,以获得更好的模糊效果。我们认为,如果一个输入字节可以影响更多未触及的分支,那么它应该优先于其他输入字节,因为改变这个输入字节更可能触发未触及的分支,并触发更复杂的程序行为,因为更多的分支状态已经改变。如图3所示,种子输入s的偏移位置处的每个输入字节可能影响多个变量,然后影响多个分支,其中一些分支未被任何测试用例探索。我们定义一个字节的权重为依赖于这个字节的未触及分支的计数,如下所示。

其中,如果到目前为止任何测试用例都没有探索分支br,则isuntouched返回1,否则返回0。根据fti,如果分支br依赖于pos-th输入字节,则函数depon返回1,否则返回0。
2.2.2 Prioritize Branches to Explore
如图3所示,一个程序路径可能有多个未触及的相邻分支。类似地,为了获得更好的模糊化结果,一些未触及的分支应该优先考虑,我们认为,依赖于更高权重输入字节的未触及分支应该优先于其他未触及分支。如果一个未触及的分支依赖于更多的高权重输入字节,为了探索这个分支,我们将对其依赖的输入字节进行变异。如上所述,对这些高权重输入字节进行变异更可能触发未触及的分支(包括与要探索的分支不同的分支)。因此,对于种子s,我们将未触及的分支br在相应路径中的权重作为其所有相关输入字节的权重之和进行计算,如下所示。

2.2.3 Determine Where and How to Mutate
利用输入字节和未探测分支的权重,可以进一步确定种子变异策略。
在哪里变异?给定一个种子和它运行的程序路径,我们将按照方程3的分支权重降序,沿着该路径逐个探索未受影响的相邻分支。在探索一个特定的未触及的邻居分支时,我们将根据等式2,按照字节权重的降序,对其相关的输入字节逐个进行变异。
在探索一个特定的未触及的邻居分支时,我们将根据等式2,按照字节权重的降序,对其相关的输入字节逐个进行变异。
如何变异输入的直接副本?如上所述,输入的直接副本应与未触及分支中预期的值匹配。因此,在变异过程中,我们将输入字节的直接副本替换为精确的期望值(对于幻数和校验和等)和具有微小变化的值(例如,长度检查±1![]() )。
)。
剩下的核心问题是如何得到期望值。有两种情况。如果需要一个常量(如幻数),我们用fti记录这个常量。如果需要运行时计算值(例如校验和),我们首先将格式错误的输入馈送到测试中,然后使用fti获取所需的运行时值。然后我们使用记录的值(和微小的变化)来修补依赖的输入字节。
注意,redqueen[4]也可以改变输入字节的直接副本。与greyone不同,redqueen无法精确定位从属字节的确切位置。它必须对种子进行数百次变异,才能得到一个具有更高熵的彩色版本,这条路径是相同的。再次测试着色版本,并与原始种子进行比较,以定位从属字节的潜在位置。着色过程非常缓慢,候选位置的数量也可能很大。因此,精确地对依赖字节进行变异要比灰体浪费更多的时间。
如何变异输入的间接副本?
如果某些输入字节影响未触及的分支,但它们的直接副本未在该分支中使用,则我们将根据等式2按字节权重降序逐个对这些字节进行变异。
更具体地说,我们将对每个相关字节应用随机位翻转和算术运算。与fti中使用的字节级变异不同,在这个阶段可以同时变异多个相关字节。
如后文所述,我们的符合性引导进化解决方案将使突变在运行中重新定位到更好的种子上,这将大大改进间接拷贝的突变。
减轻污染不足的问题。如前所述,FTI可能因未完成测试而存在污染问题。因此,对于任何未触及的分支,fti报告的依赖输入字节都可能不完整。为了探索这个分支,我们还必须对丢失的依赖输入字节进行变异。更具体地说,除了对fti报告的相关输入字节进行变异之外,我们还以小概率随机地对其相邻字节进行变异。
2.3符合性导向的进化
广泛的模糊器(如afl)使用控制流特征,如代码覆盖率,来指导模糊化的进化方向。为了有效地探索难以到达的分支(例如,那些与输入的间接副本相关的分支),我们建议使用互补的数据流特征来调整模糊化的演化方向。我们注意到,对于未触及分支中使用的每个受污染变量,我们需要翻转其依赖输入字节的一些位,使其与预期值匹配。一些测试用例比其他测试用例需要更少的努力(即,比特翻转)。所需的工作量与约束符合性有关,即受污染变量与未受影响分支中预期值的距离。符合性较高的种子更有可能产生使用未触及分支的测试用例。在此基础上,我们利用种子的约束符合性来调整模糊化的演化方向。我们对种子更新和选择策略进行了相应的修改,使模糊器朝着这个方向发展。模糊化过程中生成的测试用例更有可能具有更高的符合性,并最终满足难以达到的约束
2.3.1符合性计算
约束符合性指示目标(例如seed)与路径约束的匹配程度。
未触及分支的符合性。给定一个依赖于两个操作数var1和var2的未触及分支br,我们将其约束符合性定义如下。
![]()
其中,函数NumEqualBits![]() 返回两个参数之间的相等位数。注意,对于switch语句中的分支,它依赖的两个变量是switch条件和case值。
返回两个参数之间的相等位数。注意,对于switch语句中的分支,它依赖的两个变量是switch条件和case值。
基本块的符合性。给定一个种子s和一个基本块bb,bb可以有多个未触及的邻居分支(例如,switch语句)。我们将BB的约束符合性定义为其所有未触及的相邻分支的最大符合性:
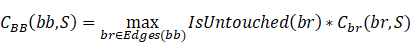
测试用例的符合性。给定一个测试用例,它的约束符合性定义为它所探索的所有基本块的符合性得分之和。

注意,具有较高约束符合性的种子可能具有(1)更多未触及的邻居分支,以及(2)具有较高约束符合性的单个未触及分支。因此,进一步的突变可能很快触发更多未触及的分支或针对单个未触及的分支。
2.3.2 Conformance-Guided Seed Updating
除了发现新代码的测试用例外,我们还将具有更高约束符合性的测试用例添加到种子队列中。为了有效地支持这种新的种子更新方案,我们提出了一种新的种子队列结构。
二维种子队列。传统的种子队列通常保存在一个链表中,每个节点代表一个探索唯一路径4的种子。我们将每个节点扩展为包含多个种子,这些种子探索相同的路径,具有相同的符合性但块符合性不同,从而形成一个二维种子队列,如图4所示。

种子队列更新。图4还显示了在以下三种情况下如何更新种子队列。
A新路径。如果测试用例发现新代码,那么它将作为一个新节点添加到seed队列中,与其他覆盖引导模糊器(例如afl)相同。
B.路径相同,但符合性较高。如果测试用例找不到任何新代码,但其符合性高于队列中相应节点(具有相同路径)中的种子,则此节点将被替换为仅包含此测试用例的新节点。
C 相同的路径和符合性,但基本块符合性不同。如果测试用例探索相同的路径,并且与队列中相应节点中的种子具有相同的符合性,但是基本块符合性的分布与该节点中的种子不同,那么我们将把此测试用例附加到该节点。
值得注意的是,在最后一种情况下,由于测试用例具有唯一的基本块符合性分布,因此它可以派生新的测试用例来快速触发一些基本块的非接触邻居分支,因此是有用的。
比较。这种种子更新策略使得模糊器以与安哥拉梯度下降算法相当的速度逐渐提高整体符合性,并以较快的速度满足未触及分支的约束[10]。但它可以避免像安哥拉那样陷入当地最低水平,并带来长期稳定的改善。
注意,honggfuzz[38]还比较了分支语句中操作数的相等性。如果分支的相等性增加,则会将测试用例添加到种子队列中。但是,它不排除与触碰分支相关的比较指令,这些指令对分支探索是无用的。此外,基本块内部可能有多个比较指令,但并非所有指令都与分支相关。最后,它缺乏本文提出的有效的二维种子队列结构,限制了它的效率。
2.3.3 On-the-fly Mutation Rebase
一旦我们发现一个测试用例与之前的种子运行相同的程序路径,但具有更高的符合性,即如前所述的案例B,我们不仅通过用一个新节点替换相应的节点来将该测试用例添加到种子队列中,而且还替换被替换种子的所有用途。特别是,如果被替换的种子被一个正在进行的突变所使用,我们将把突变重新定位到新种子上,因为新种子更好。这个操作可以动态完成,如图1中的红线所示。实验表明,该优化技术是非常有效的。例如,它将在LAVA数据集中查找相同数量的错误的速度提高了三倍。
2.3.4符合性指导下的种子选择
许多工作[6,14]已经证明,种子选择策略可以加速模糊进化。我们建议在种子选择过程中优先考虑符合性较高的种子。更具体地说,我们迭代种子队列的链表,并选择具有更高符合性和更高概率的链接节点。然后在这个连接节点中随机选择一个种子进行进一步的变异。利用该方案,更容易选择符合性较高的种子。进一步的突变更有可能产生符合性更高的测试用例,这可以满足非接触分支难以达到的约束。
3 Implementation
我们用20000行C/C++代码实现了GyyOne的原型。当前的原型支持使用llvm字节码分析应用程序。在这里,我们将介绍它的一些实现细节。
3.1 Modularized Framework
如图1所示,greyone由几个核心成分组成,如种子更新、种子选择、种子突变和检测。我们实现了一组可扩展接口来支持各种策略和未来的改进。
测试用例评分。进化模糊器通常根据一定的测试用例评分算法,将一些测试用例放到种子库中进行进一步的变异。我们实现了测试用例评分的通用接口,能够支持afl采用的覆盖引导种子更新策略和greyone采用的符合性引导策略。
种子优先级。模糊算子通常根据某种种子评分算法对种子进行优先排序,以选择和分配不同的能量进行变异。我们实现了一个种子评分的通用接口,能够支持greyone采用的符合性指导的种子选择策略和其他fuzzer使用的策略(如collafl[14]和aflfast[6])。
种子变异算法。除了其他模糊算子(如afl)实现的变异算子(如字节翻转)外,我们还增加了对fti使用的字节级变异的支持,以及直接拷贝变异,其中模糊算子被告知要使用的确切偏移量和确切值。
块管理。模糊器通常需要特殊的数据结构来支持组件之间的有效通信和有效的决策。我们构造了许多基于树和哈希表的结构来存储这些信息,包括控制流图、代码覆盖率、种子符合性、变量的污染属性和变量的值。
选择性测试。除了代码覆盖跟踪,Greyone在测试过程中还有两种模式:(1)用于FTI的可变值监视模式;(2)用于进化调整的符合性引导跟踪模式。为了有效地调度这些不同的测试模式,我们扩展了afl使用的fork服务器,以便根据需要在它们之间进行切换。例如,在模糊化过程中,如果一个种子花费了太多的变异能量或者符合性暂时没有增加,那么我们将从符合性跟踪模式切换到常规覆盖跟踪模式。
3.2 Static Analysis and Instrumentation.
为了支持本文提出的策略,我们需要首先使用静态分析来分析目标应用程序,并在运行时收集一些信息。在clang的帮助下进行了一些基本的过程间控制流分析,得到了控制流图和其他必要的信息。
覆盖范围跟踪。collafl[14]指出,传统的覆盖跟踪方案(如afl)存在严重的散列冲突问题。我们用复制了collafl的缓解方式。
符合性跟踪:为了支持符合性跟踪,我们检测每个分支语句(包括条件分支和switch语句)以计算其操作数的相等位数(通过诸如“内置”popcount之类的操作)。
变值监控:fti依赖于模糊化过程中的变值监控。我们测试应用程序以记录路径约束中使用的变量值。更具体地说,我们为所有这些变量分配唯一的id,并将它们的值存储在一个位图中(id作为键),类似于存储afl使用的代码覆盖率的位图。
6 Related Work
基于进化变异的模糊算法由于其可扩展性和高效性,在实际应用中取得了巨大的成功。代表解afl[44]以获得更高的码覆盖率为进化方向,以几乎随机的方式突变种子。许多其他的解决方案,包括污点分析,已经被提出来改进基于变异的模糊。
6.1 Taint Inference
污点分析是包括模糊化在内的许多应用的基本技术。传统的污点分析解决方案[2,20]在很大程度上依赖于为每个指令编写污点传播规则的手动操作,并且遭受严重的污点不足和过度污点问题。
对传统污点分析的改进。针对传统污点分析中存在的误差问题,提出了许多改进方案。dytan[11]跟踪间接污点传播,以缓解污点不足的问题,但带来了许多误报。dta++[19]定位隐式控制流分支,并使用离线符号执行进行污点下诊断。然而,它的缺点是解决了复杂的条件和高性能的开销。taintinclude[46]采用基于测试的解决方案自动推断污点传播规则。但它的重量很重,不能解决不准确的问题。
基于变异的推断。最近的一些工作提出了基于变异的污点推断,在某些应用中有较好的性能。sekar[31]采用黑盒测试,利用预先定义的突变规则推断污染,能够检测注入攻击。mutaflow[26]通过对敏感源api进行变异来监控安全敏感api的变化,能够检测到易受攻击的信息流。这两种方法侧重于局部程序行为,仅限于信息流检测。在模糊应用中,redqueen[4]使用随机变异给输入着色,以推断与直接复制输入相关的污点。fairfuzz[24]和profuzzer[42]监视多个运行之间的控制流变化模式,以推断变异字节的部分类型。这些解都没有考虑到变异后变量值的变化,因此都不能提供准确的污染信息。
本文提出了一种模糊驱动的污点推断方法fti。我们执行系统的字节级变异来执行pilot模糊。在模糊化过程中,我们监控变量的值变化,并据此推断污染属性。该解决方案自动化、轻量级且更精确。
6.2 Seed Mutation
许多研究[10,13,30,44]表明,种子突变是提高模糊处理效率和准确性的最热点和最困难的方向之一。人们提出了许多方法试图解决如何以及在哪里变异。
a)基于静态分析的优化。steelix[25]和laf-intel-pass[1]将这些长常量比较静态地分解为多个短比较。从而使bomb随机模糊器以更高的概率满足路径约束。然而,它带来了太多的语义等价路径,无法处理非恒定比较。symfuzz[8]利用静态符号分析来检测输入位之间的依赖关系,并使用它来计算最佳变异率。然而,这一过程是缓慢的,并且计算出的位之间的依赖关系并没有显示出许多变异的改进。
b)基于学习的模式。Rajpal等人[29]提出了一个基于RNN的模型,根据历史突变及其相应的代码覆盖反馈,预测种子中的最佳突变位置。康斯坦丁等人[7]利用深度强化学习对模糊循环进行建模,并在随后的模糊迭代中选择最佳的变异动作。这些解决方案尚处于早期阶段,尚未显示出显著的改进。neuzz[35]确定了程序平滑的重要性,并使用增量学习技术来指导变异
c) 基于符号的解决方案。这类解决方案本质上是利用符号执行来解决复杂的路径约束,而这些约束是基于变异的模糊算法难以满足的。driller[37]周期性地选择陷入基于变异的模糊化的路径,并使用符号执行来解决这些路径的约束。qsym[43]将符号执行移植到本机x86指令并放宽要解决的路径约束,从而提供更好的分析性能并降低约束解决的速度。Diggfuzz[45]设计了一个概率路径优先化模型来量化每条路径的难度,并对它们进行优先排序,以便共同执行。由于约束求解的开放性挑战,所有这些基于符号的解决方案都无法扩展到大型应用中。
d)基于污染的突变。一些模糊者利用污染来引导突变。Dowser[17]和Borg[27]分别使用Taint来定位缓冲区边界冲突和缓冲区过度读取漏洞。buzzfuzz[15]使用dta跟踪影响敏感库或系统调用的外部种子输入区域。TaintScope[40]利用细粒度DTA来标识校验和分支。Vuzzer[30]能够跟踪比较变量和常量(如幻数)的分支,并相应地指导变异。angora[10]基于dta进行形状推断和梯度下降计算。这些解决方案受到不精确的污染,限制了复杂程序的效率。
此外,dta的高开销极大地限制了dta在大型应用中的应用。在轻量级污染导向突变解中,fairfuzz[24]和profuzzer[42]无法获得变量的精确污染属性,在探索难以到达的分支时效率低下。此外,它们还会重复地改变一些输入字节,即使相关的分支已经被探索过,因为它们对分支状态不敏感。redqueen[4]专注于识别输入的直接副本和使用它们的分支,无法处理输入的间接副本的普遍使用。
我们的解决方案greyone利用轻量级和声音污染推理解决方案fti来获得更多的污染属性(没有过度污染),以及输入偏移和分支之间的精确关系,以确定要探索的分支和要变异的字节的优先级,并确定如何精确地变异它们。
6.3 Seed Updating and Selection
种子更新和选择可以调整模糊的进化方向。一个好的解决方案可以提高fuzzer查找更多代码和错误的效率[28]并朝着潜在易受攻击的目标代码[5,9,39]前进。
种子更新的研究很少,但近年来提出了许多种子选择的解决方案。这些解决方案一般收集越来越多的辅助控制流信息来指导种子选择。在一开始,afl[44]优先处理那些较小的种子和较短的执行时间,以便在给定的时间段内生成更多的测试用例。然后,aflfast[6]指出了种子选择的重要性,并对很少被采摘变异和探索寒冷路径的种子进行了优先排序。从那时起,各种控制流特性被用于指导种子选择,例如,通过优先排序较深路径[30]或未接触的相邻分支[14]。
然而,这些解决方案没有考虑任何数据流特性,因此在探索具有复杂约束的路径时效率低下。honggfuzz[38]和libfuzzer[32]利用弱数据流特性来指导种子选择。更具体地说,它们计算所有分支的操作数之间的距离,并将其用于指导种子选择。
Greyone只对所有受污染的未触及分支评估约束一致性,从而改进了此策略。它还利用了一种新颖的二维种子队列结构,为高效的种子更新和选择提供支持。它能够避免安哥拉使用的基于学习的解决方案所面临的局部最小问题[10]。此外,greyone还应用了一种新的动态突变rebase来进一步加速模糊的进化。
6.4 Performance Optimization
性能是有效模糊化的一个重要因素。为了提高模糊处理的性能,人们提出了几种解决方案,如提高并行执行能力[41]或提高插装能力[18,36]。untracer[36]最近的工作消除了已经探索过的基本块中不必要的工具,并减少了开销。Greyone还对仪器进行了优化,根据需要选择了更多的轻量级测试模式,并在不同的模糊模式之间切换,提高了模糊的速度。
