摘要:
当今的数据中心为成千上万台计算机的群集提供了巨大的聚合带宽, 但是即使在最高端的交换机中,端口密度也受到限制,因此数据中心拓扑通常由多根树组成,这些树在任何给定的主机对之间都具有许多等价路径。 现有的IP多路径协议通常依赖于每流静态哈希,并且由于长期冲突而可能导致大量带宽损失。
在本文中我们介绍了Hedera,这是一种可伸缩的动态流调度系统,可自适应地调度多级交换结构以有效利用聚集的网络资源。 我们描述了使用商用交换机和未修改主机的实施方式,对于模拟的8,192个主机数据中心,Hedera提供的对等带宽为最佳的96%,比静态负载平衡方法高113%。
背景/问题:
大型组织正以几年前无法预料的速度和规模建立庞大的数据中心,以支持数万台机器,而由于许多应用程序都需要大量的群集内带宽,其他公司也渐渐开始将其计算、存储和操作转移到云计算托管提供商。
数据中心中使用的路由和转发协议是针对非常特定的部署设置而设计的。传统上,普通的企业/内联网环境使用少量的流行通信目标可以相对预测通信模式,通常主机之间只有很少的路径,辅助路径主要用于容错。与之相反,数据中心设计依靠路径多样性来实现主机的水平缩放,由于这些原因,数据中心拓扑与典型的企业网络有很大不同。
由于高端商用交换机中端口密度的限制,数据中心拓扑通常采用具有更高速度链路的多根树的形式,但随着层次结构的增加,聚合带宽逐渐降低。这些多根树在所有主机对之间都有许多路径,一个关键的挑战是沿着这些路径同时动态地转发流,以最小化/减少链路超额预订并提供可接受的聚合带宽。不幸的是,现有的网络转发协议被优化为在没有故障的情况下为每个源/目的地对选择一条路径。此类静态单路径转发可能会严重利用任何扇出的多根树。即使企业和数据中心环境中最先进的转发使用ECMP(等价多路径)来使用流散列在可用路径上静态剥离流,也不能通过流到路径的这种静态映射说明当前的网络利用率或流大小,这种情况下导致的冲突反而使交换机缓冲区不堪重负,降低了交换机的整体利用率。
解决办法:
本文介绍了Hedera,这是一种用于数据中心中多级交换拓扑的动态流调度系统,通过全面了解路由和流量需求,调度系统能够看到本地交换机无法实现的瓶颈。
Hedera从组成交换机收集流信息,计算流的无冲突路径,并指示交换机相应地重新路由流量。我们的目标是最大程度地提高网络总利用率(对等带宽),并以最小的调度程序开销或对活动流的影响来实现这个目标。
具体实现:
群集应用程序通常会在网络上成为瓶颈,而不是受到本地资源的限制,因此,改善应用程序性能可能取决于改善网络性能。大多数传统的数据中心网络拓扑都是分层树,这些树具有连接到端主机的小型廉价边缘交换机,这样的网络通过两层或三层交换机互连,以克服商用交换机可用的端口密度的限制。
随着建立包含数万台机器的大型数据中心的推动,最近的研究提倡横向扩展而非纵向扩展数据中心网络,网络将不再使用昂贵的具有更高速度和端口密度的核心路由器,而是利用任何给定源边缘交换机和目标边缘交换机之间的大量并行路径,即所谓的多根树形拓扑(如下图)。因此,我们发现自己陷入了僵局——使用多根拓扑的网络设计有可能在所有通信主机之间提供完整的二等分带宽,但没有有效的协议来转发网络内的数据或调度程序以将流量适当分配给路径利用这种高度的并行性。
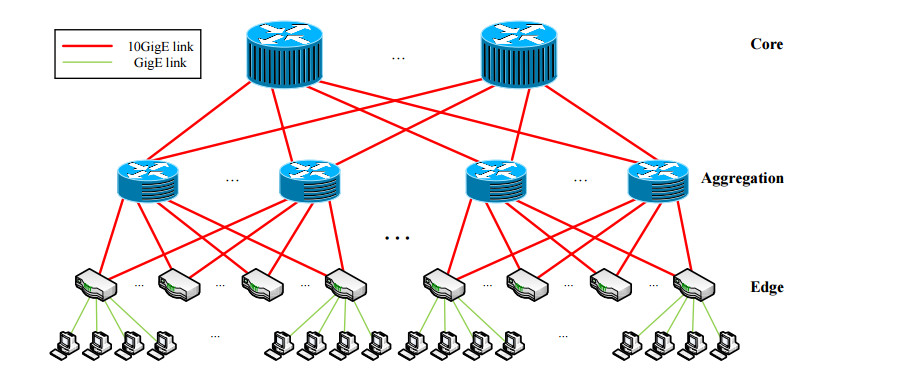
为了解决这些问题,我们介绍了Hedera的体系结构,该系统利用数据中心拓扑中的路径分集来为各种流量模式提供近乎理想的对等带宽。
为了利用数据中心拓扑中的多条路径,当前的最新技术是使用等价多路径转发(ECMP)。
启用ECMP的交换机配置有给定子网的几种可能的转发路径,当具有多个候选路径的数据包到达时,将在对应于该数据包标头中所选字段的哈希值的哈希值上以路径数为模的转发数据,从而将负载分配给跨多个路径的每个子网。这样,流的所有数据包都采用相同的路径,并维持其到达顺序。密切相关的方法是有效负载平衡(VLB),该方法通过从随机选择的中间“核心”中释放来自网格中源交换机的单个数据包,从本质上保证了网格网络中等价的负载平衡,交换机最终将这些数据包转发到其目标交换机。 VLB实现在每个流而不是每个数据包的基础上执行随机转发,以保留数据包的顺序。请注意,每流VLB实际上等效于ECMP。 ECMP的一个关键限制是,两个或多个大的长寿命流可以在其哈希上碰撞并最终在同一输出端口上,从而产生了可避免的瓶颈。
如下图所示,我们考虑一个示例通信模式。

多根1Gbps网络拓扑中的主机子集。
我们确定了哈希引起的两种冲突。首先,由于哈希冲突,TCP流A和B在交换机Agg0本地进行了干扰,并受出站到Core0的1Gbps容量的限制。其次,由于受到下游干扰,Agg1和Agg2独立转发数据包,并且无法预见流C和D的Core2冲突。
在此示例中,所有四个TCP流本可以通过改进的转发达到1Gbps的容量。流A可以转发到Core1,流D可以转发到Core3,但是由于这些冲突,所有四个流均以500Mbps的速度瓶颈,两等分带宽损失为50%。由于ECMP和基于流的VLB的性能本质上取决于流大小和每个主机的流数,在网络中的主机同时执行彼此之间的全通信或仅使用几个RTT的单个流进行全通信的情况下,基于哈希的转发效果很好,非均匀的通信模式,特别是涉及大数据块传输的通信模式,需要更加谨慎地安排流量以避免网络瓶颈。
于是改进办法就是引入Hedera中的中央调度程序去动态调控,中央调度程序可能会复制以实现故障转移和可伸缩性,它会根据当前网络范围内通信需求的定期更新动态地控制边缘交换机和聚合交换机的转发表。调度程序旨在将流分配给无冲突的路径,更具体地说,它试图不将多个流放在不能满足其组合自然带宽需求的链路上。在此模型中,只要流持续存在一段时间并且其带宽需求超过定义的限制,我们就会使用本篇论文中所述的一种调度算法为它分配一条路径,根据此选择的路径,调度程序会将流条目插入到该流的源容器的边缘和聚合开关,这些条目在新选择的路径上重定向流,流终止后,流条目将在超时后过期。
Hedera对ECMP进行了补充,为导致ECMP问题的通信模式补充了默认的ECMP行为。