训练集文本数据相关分析
import pandas as pd
读取数据
train_data=pd.read_csv('D:/Ai/05-深度学习与NLP/20200410_data/cn_data/train.tsv',sep="\t")

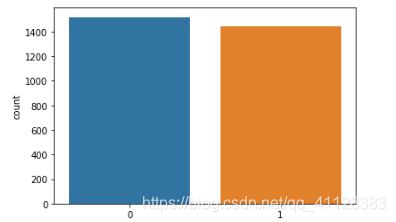
分析目标值是样本比例
获取目标值
label=train_data['label']
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot("label", data=train_data)
plt.title("train_data")
plt.show()
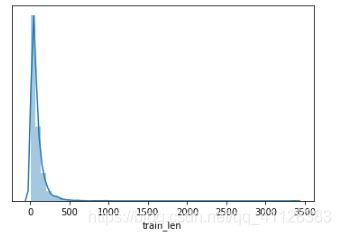
获取训练集句子长度分布
train_data['sentence']
train_data['train_len']=list(map(lambda x:len(x),train_data['sentence']))
plt.figure(figsize=(30,10))
sns.countplot(train_data['train_len'])
plt.title("train_len")
plt.show()

# 绘制dist长度分布图
sns.distplot(train_data["train_len"])
plt.yticks([])
plt.show()
获取训练集正负样本长度散点分布
plt.figure(figsize=(30,10))
sns.stripplot(x='label',y=train_len,data=train_data)
plt.title("train_len")
plt.grid(ls='--')
plt.show()

训练集不同词汇总数统计
import jieba
from itertools import chain
vocabs=set(chain(*map(lambda x:jieba.lcut(x),train_data['sentence'])))
vocab_len=len(vocabs)
print(vocab_len)
结果:
12162
文本特征处理-数据增强
- 回译数据增强法: 将文本数据翻译成另外一种语言(一般选择小语种),之后再翻译回原语言, 即可认为得到与与原语料同标签的新语料, 新语料加入到原数据集中即可认为是对原数据集数据增强.
逻辑代码实现
>>> from googletrans import Translator
>>> translator=Translator()
>>> content='电视不好用, 没有看到足球'
>>>
>>> translations=translator.translate([content],dest='ko')
>>> ko_res=list(map(lambda x:x.text,translations))
>>> ko_res
['TV가 잘 작동하지 않습니다, 나는 축구를 볼 수 없습니다']
>>> zh_res=translator.translate(ko_res,dest='zh-cn')
>>> zh_re=list(map(lambda x:x.text,zh_res))
>>> zh_re
['电视不工作,我不能去看足球']
文本特征处理-文本长度规范
一般模型的输入需要等尺寸大小的矩阵, 因此在进入模型前需要对每条文本数值映射后的长度进行规范, 根据句子长度分布分析,取合理长度, 对超长文本进行截断, 对不足文本进行补齐,
逻辑代码实现
from tensorflow.keras.preprocessing import sequence
cutlen=8
def padding(train_data):
# 对输入文本张量进行长度规范
return sequence.pad_sequences(train_data,cutlen)
x_train = [[1, 500, 5, 32, 55, 63, 300, 21, 78, 32, 23, 1],
[2, 32, 1, 23, 1,100,200]]
res=padding(x_train)
print(res)
结果:
[[ 55 63 300 21 78 32 23 1]
[ 0 2 32 1 23 1 100 200]]
从结果可以看到长的列表从前面截断
缺点长度在前面补0
文本特征处理-提取n-gram特征
n-gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列,
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度
常用的是二元的Bi-Gram和三元的Tri-Gram
逻辑代码实现
ngram_range=2
def create_gram_set(train_list):
# 从数值列表中提取所有的n-gram特征
return set(zip(*[train_list[i:] for i in range(ngram_range)]))
input_list=[2,3,4,56,5,6,8]
res=create_gram_set(input_list)
print(res)
**该输入列表的所有bi-gram特征**
{(6, 8), (5, 6), (56, 5), (2, 3), (4, 56), (3, 4)}
