# 导入工具包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torch.utils.data import random_split
# 数据集构造
x=torch.randn([10000,1])
y=x*2+0.5
#如果设备上有GPU使用GPU 否则使用CPU
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
# 构建特征值 目标值
x,y=x.to(device),y.to(device)
# 构建模型
class Linearmodel(nn.Module):
def __init__(self,input):
super().__init__()
self.fc=nn.Linear(1,1)
def forward(self,input):
output=self.fc(input)
return output
# 实例化模型 损失函数选择,优化器选择 学习率选择
model=Linearmodel(x).to(device)
criterion=nn.MSELoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.05)
# 迭代训练模型
epotchs=10
for epotch in range(epotchs):
optimizer.zero_grad()
output=model(x)
loss=criterion(y,output)
loss.backward()
optimizer.step()
print(loss)
if (epotch+1)%5==0:
print("第{}次的损失为{}".format(epotch,loss.data))
# 模型保存与加载
torch.save(model,'./model01')
model01=torch.load('./model01')
# 模型评估
model01.eval()
out_predict=model01(x)
out_predict=out_predict.cpu().detach().numpy()
# 真实的
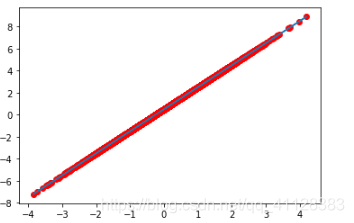
plt.scatter(x.cpu().data.numpy(),y.cpu().data.numpy(),c='r')
# 预测
plt.plot(x.cpu().data.numpy(),out_predict)
plt.show()
迭代10个批次:
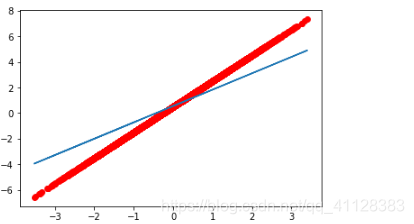
迭代100个批次: