2.1 基本概念
1、串
(1)基本概念
串是一个有穷符号(symbol)序列
串s的长度,通常记作|s|,是指s中符号的个数
空串(empty string)是长度为0的串,用 ε(epsilon)表示:|ε|= 0
(2)基本运算
如果x和y是串,那么x和y的连接(concatenation),是把y附加到x后面而形成的串,记作xy
注意:εs = sε = s
幂运算:s0= ε , sn= sn-1s, n ≥1
2、字母表
(1)基本概念
字母表∑是一个有穷符号集合,例如:
➢二进制字母表:{ 0,1 }
➢ASCII字符集
➢Unicode字符集
(2)基本运算
字母表∑1和∑2的乘积( product)即∑1∑2 ={ab|a ∈ ∑1, b ∈ ∑2}
字母表∑的n次幂( power) ∑0 ={ ε } ∑n=∑n-1 ∑, n ≥ 1,长度为n的符号串构成的集合
字母表∑的正闭包( positive closure) ∑+ = ∑ ∪ ∑2 ∪ ∑3 ∪ … ,长度正数的符号串构成的集合
字母表∑的克林闭包(Kleene closure) ∑*= ∑0 ∪ ∑+ = ∑0 ∪ ∑ ∪ ∑2 ∪ ∑3 ∪ … ,任意符号串(长度可以为零)构成的集合
2.2 文法的定义
文法的形式化定义
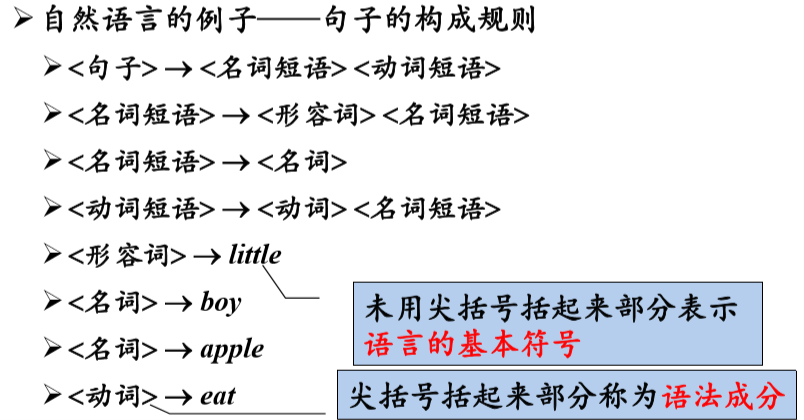
G = (VT , VN , P , S )
VT:终结符集合
终结符(terminal symbol)是文法所定义的语言的基本 符号,有时也称为token,例: VT= { apple, boy, eat, little }
VN:非终结符集合
非终结符(nonterminal) 是用来表示语法成分的符号, 有时也称为“语法变量” ,例: VN= { <句子>, <名词短语>, <动词短语>, <名 词>, … }
P :产生式集合
产生式( production)描述了将终结符和非终结符组合成串的方法 产生式的一般形式: α→β(α定义为β)
α∈(VT∪VN)+,且α中至少包含一个VN中的元素:称为产生式的头 (head)或左部(left side)
β∈(VT∪VN)* :称为产生式的体(body)或右部(right side)
S :开始符号
S∈VN。开始符号(start symbol)表示的是该文法中最大的语法成分,例:S = <句子>

产生式的简写
对一组有相同左部的α产生式,可以简记为:α→β1 | β2 | … | βn (α定义为β1,或者β2,…,或者βn )
符号约定
- 下述符号是终结符
➢(a) 字母表中排在前面的小写字母,如 a 、 b 、 c
➢(b) 运算符,如+、*等
➢© 标点符号,如括号、逗号等
➢(d) 数字0、1、. . . 、9
➢(e) 粗体字符串,如id、if等 - 下述符号是非终结符
➢(a) 字母表中排在前面的大写字母,如A 、 B 、 C
➢(b) 字母S。通常表示开始符号
➢© 小写、斜体的名字,如 expr、stmt等
➢(d) 代表程序构造的大写字母。如E(表达式) 、 T(项) 和F(因子) - 字母表中排在后面的大写字母(如X、Y、Z) 表示文法符号(即终结符或非终结符)
- 字母表中排在后面的小写字母(主要是u、v、. . . 、z) 表示终结符号串(包括空串)
- 小写希腊字母,如α、β、γ,表示文法符号串(包括空串)
- 除非特别说明,第一个产生式的左部就是开始符号
2.3 语言的定义

有了文法(语言规则),如何判定一个词串是否是满足文法的句子?
1、推导和规约
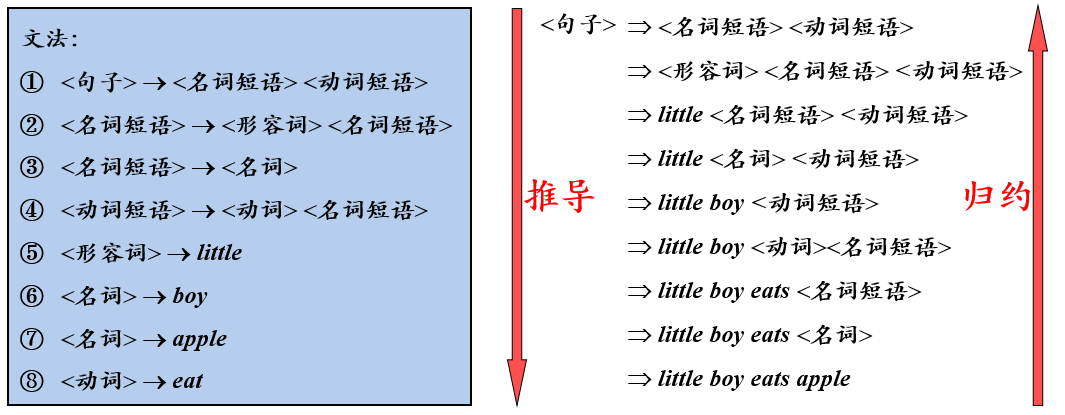
给定文法G=(VT , VN , P , S ),如果 α→β ∈ P,那么 可以将符号串γαδ中的α替换为β,也就是说,将γαδ 重写(rewrite)为γβδ,记作 γαδ =>γβδ。此时,称文法 中的符号串 γαδ 直接推导(directly derive)出 γβδ
简而言之,就是用产生式的右部替换产生式的左部
α =>0 α
=>+ 表示“经过正数步推导”
=>* 表示“经过若干(可以是0)步推导”
有了文法(语言规则),如何判定某一词串是否是该语言的句子?
- 句子的推导(派生)-从生成语言的角度
- 句子的归约 -从识别语言的角度
2、句型和句子
如果 S=>* α,α∈(VT∪VN),则称α是G的一个句型
一个句型中既可以包含终结符,又可以包含非终结符,也可能是空串
如果 S=>* w,w ∈VT,则称w是G的一个句子,句子是不包含非终结符的句型

3、语言的形式化定义
由文法G的开始符号S推导出的所有句子构成的集合称为文法G生成的语言,记为L(G )。 即L(G )= {w | S =>* w,w∈ VT* }

4、语言上的运算

2.4 文法的分类
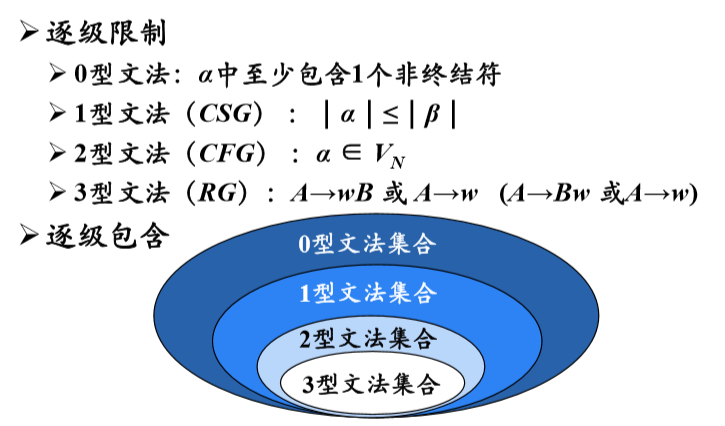
1、0型文法
无限制文法(Unrestricted Grammar) /短语结构文法
∀α → β∈P, α中至少包含1个非终结符
0型语言:由0型文法G生成的语言L(G )
2、1型文法
上下文有关文法
∀α → β∈P,|α|≤|β|
产生式的一般形式: α1Aα2 → α1βα2 ( β≠ε )
上下文有关语言(1型语言):由上下文有关文法 (1型文法) G生成的语言L(G ),不包含ε-产生式
3、2型文法
上下文无关文法
∀α → β∈P,α ∈ VN
产生式的一般形式:A→β
例:
S → L | LT
T → L | D | TL | TD
L → a | b | c | d |…| z
D → 0 | 1 | 2 | 3 |…| 9
上下文无关语言(2型语言):由上下文无关文法 (2型文法) G生成的语言L(G )
4、3型文法
正则文法
- 右线性(Right Linear)文法: A→wB 或 A→w
- 左线性(Left Linear) 文法: A→Bw 或 A→w
- 左线性文法和右线性文法都称为正则文法
正则语言(3型语言): 由正则文法 (3型文法) G生成的语言L(G )
正则文法能描述程序设计语言的多数单词
5、四种文法之间的关系
2.5 CFG的语法分析树
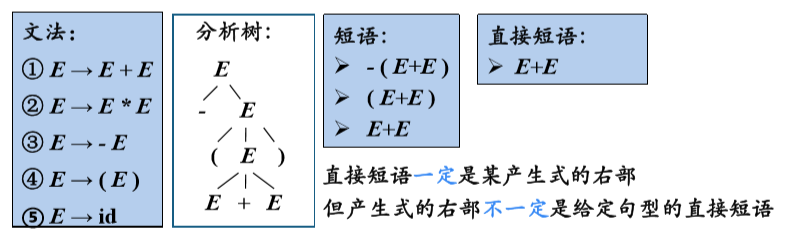
1、CFG 的分析树

根节点的标号为文法开始符号
内部结点表示对一个产生式A→β的应用,该结点的标号是此产生式左部 A 。该结点的子结点的标号从左到右构成了产生式的右部 β
叶结点的标号既可以是非终结符,也可以是终结符。从左到右排列叶节点得到的符号串称为是这棵树的产出(yield)或边缘(frontier)
2、分析树是推导的图形化表示
给定一个推导 S => α1=> α2=>…=> αn ,对于推导过程中得到的每一个句型αi,都可以构造出一个边缘为αi的分析树
推导过程:E=>-E => - ( E ) => - ( E+E ) => - ( id+E ) => - ( id+id )

3、(句型的)短语
给定一个句型,其分析树中的每一棵子树的边缘称为该句型的一个短语(phrase)
如果子树只有父子两代结点,那么这棵子树的边缘称为该句型的一个直接短语(immediate phrase)
例:
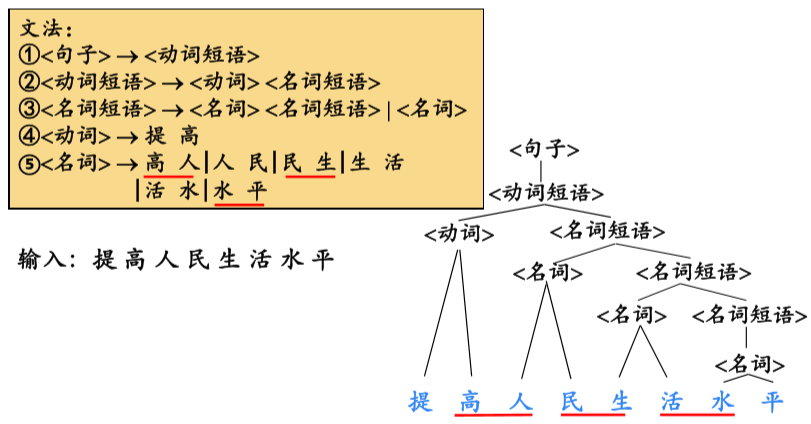
4、二义性文法
如果一个文法可以为某个句子生成多棵分析树,则称这个文法是二义性的
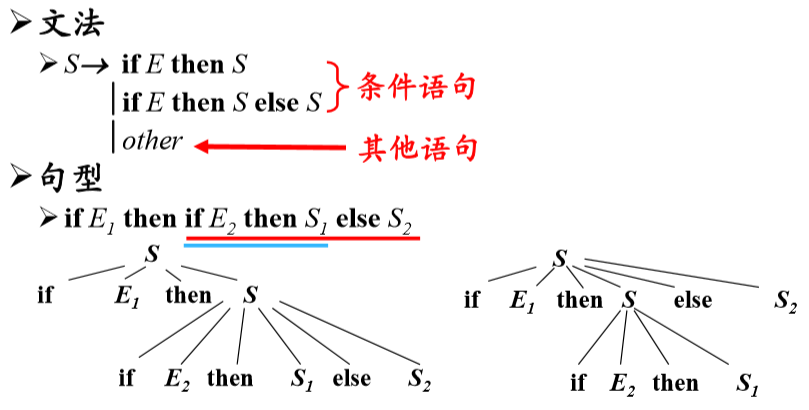
消歧规则:每个else和最近的尚未匹配的if匹配
二义性文法的判定:对于任意一个上下文无关文法,不存在一个算法,判定它是无二义性的;但能给出一组充分条件,满足这组充分条件的文法是无二义性的
- 满足,肯定无二义性
- 不满足,也未必就是有二义性的
