1. 简介
Beautiful Soup(美丽汤)是一个Python第三方库,用于从HTML和XML文件中提取数据。它与您最喜欢的解析器一起使用,提供了导航,搜索和修改解析树的惯用方式,点击此处进入官网。最新版本Beautiful Soup 4 简称bs4。优势:相比于ET库, 功能更全,可以选择解析器来解析文档,既支持html, 也支持xml,容错度(简单理解为文档格式自动补全功能)也更高,API也很好用。
2. 安装
2.1 库本身的安装
命令安装格式如下:
pip install --user -i http://pypi.douban.com/simple --trusted-host pypi.douban.com beautifulsoup4
使用Pycharm图形化界面安装如下:
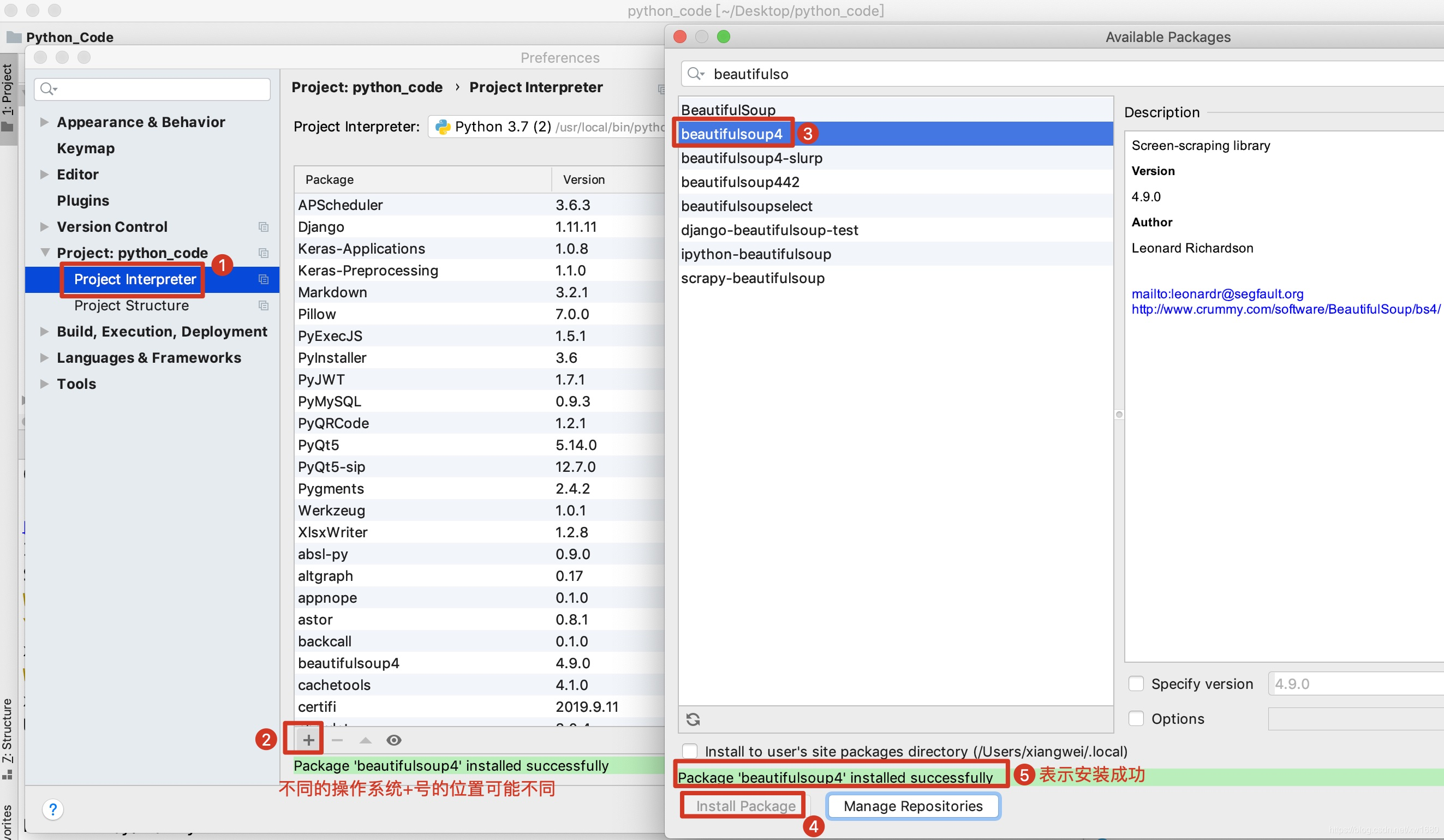
2.2 解析器的安装
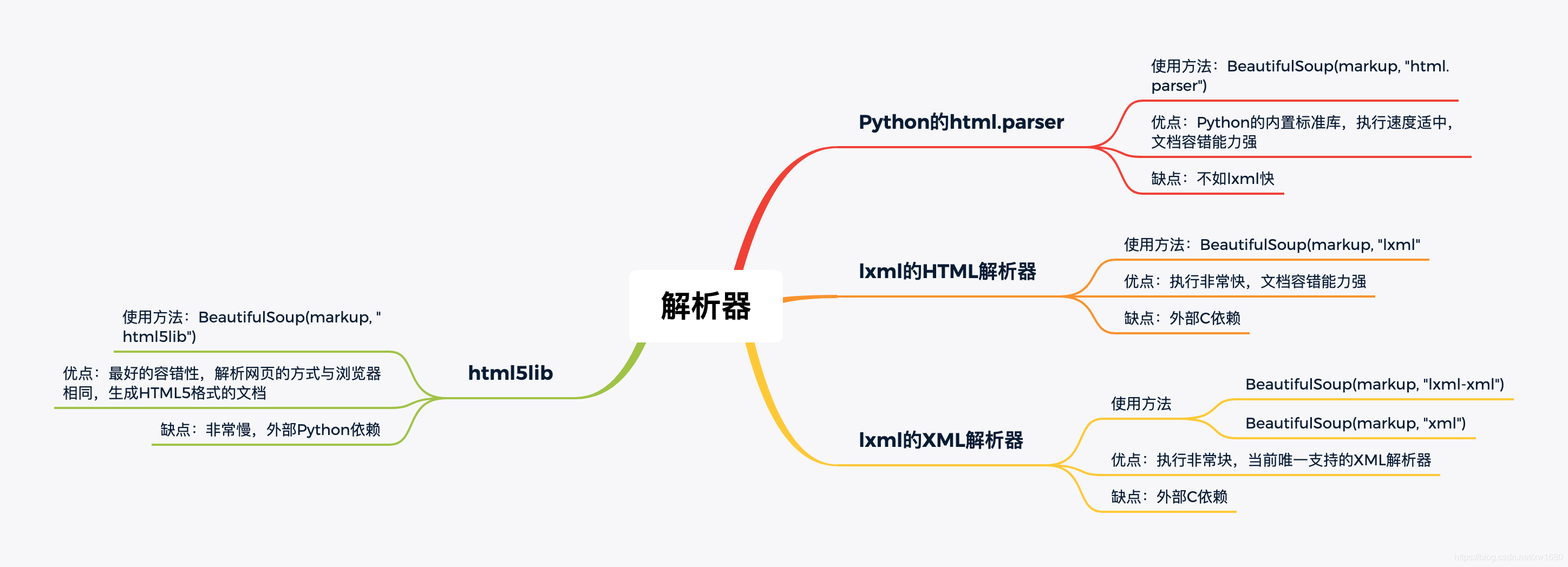
把指定内容,转换成可解析的对象,不同的解析器,解析的结果不同,容错能力不同,解析效率不同。如图所示:
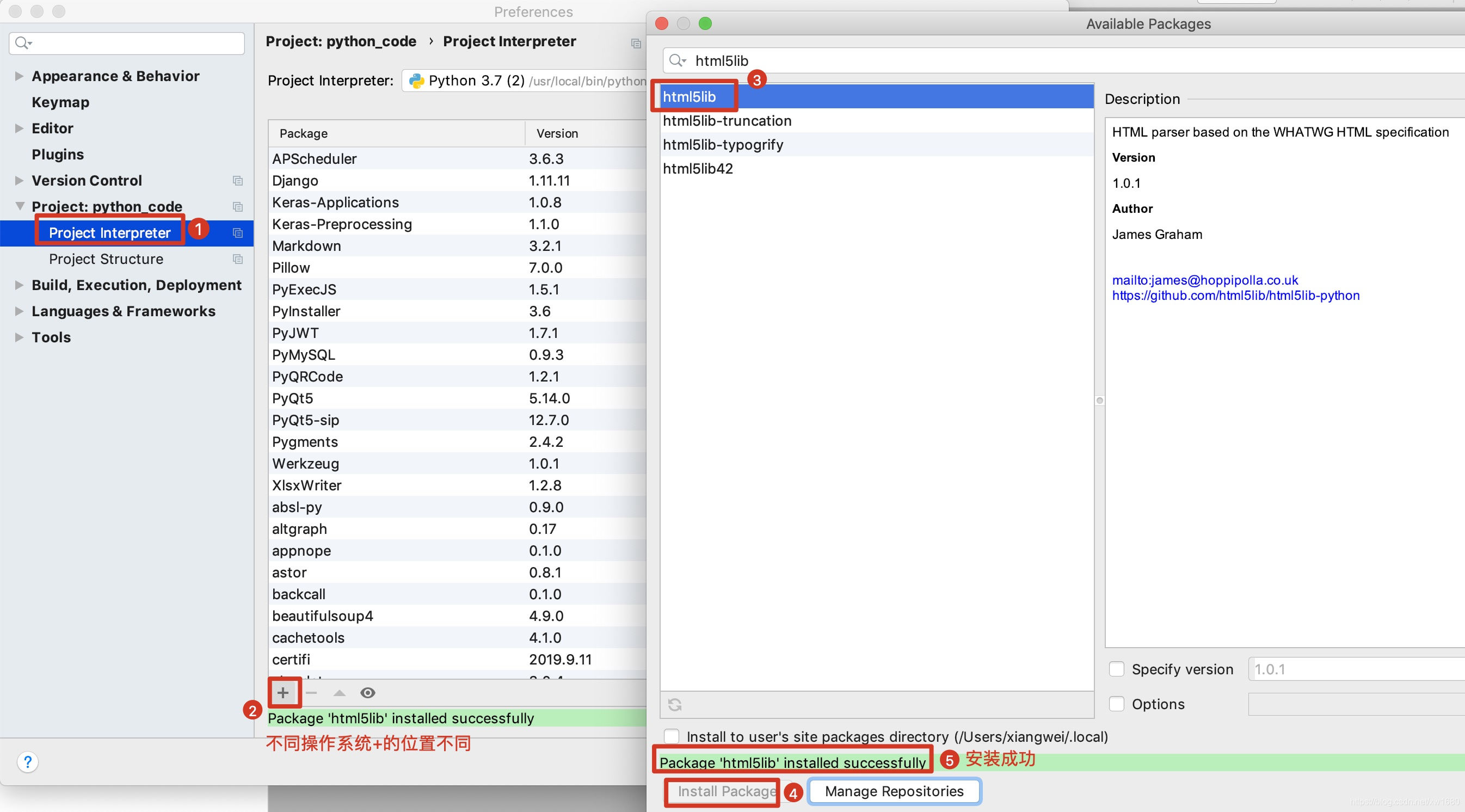
html5lib解析器安装图示如下:
lxml解析器安装图示如下:
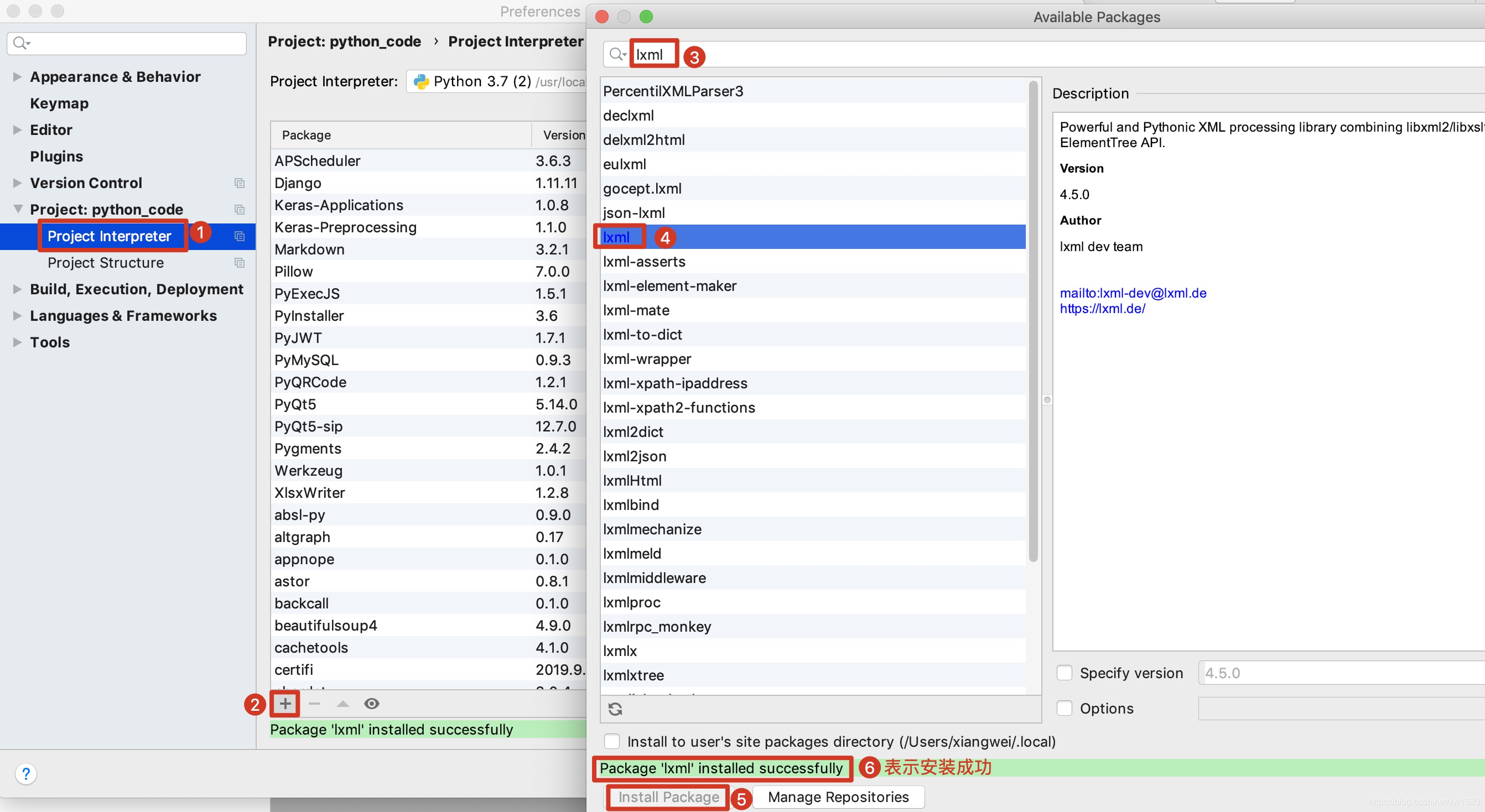
如果可以,我建议读者安装并使用lxml以提高速度。基本示例代码如下:
from bs4 import BeautifulSoup
str1 = """
<a>Amo好帅~</a>
"""
# 1.使用python内置解析器
soup1 = BeautifulSoup(str1, "html.parser")
print(soup1)
print("*" * 30)
# 2.使用lxml解析
soup2 = BeautifulSoup(str1, "lxml")
print(soup2)
print("*" * 30)
# 3.lxml-xml解析xml
# soup3 = BeautifulSoup(str1, "lxml-xml")
soup3 = BeautifulSoup(str1, "xml") # "lxml-xml"和"xml"这两种写法都是可以的
print(soup3)
print("*" * 30)
# 4.使用html5lib解析器
soup4 = BeautifulSoup(str1, "html5lib")
print(soup4)
上述代码执行结果如下:

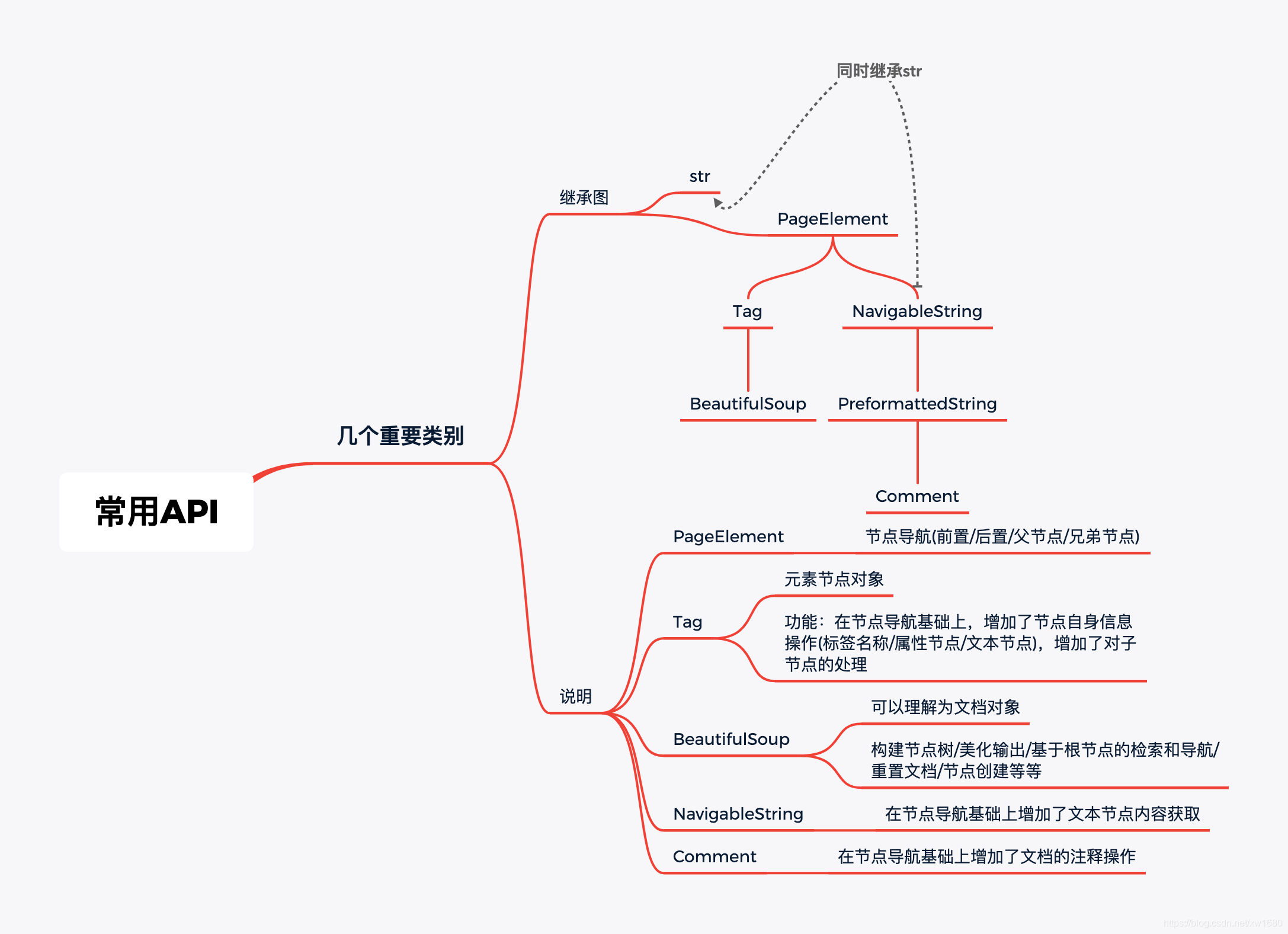
3. 常用API
bs4重要的几个类别如图所示:
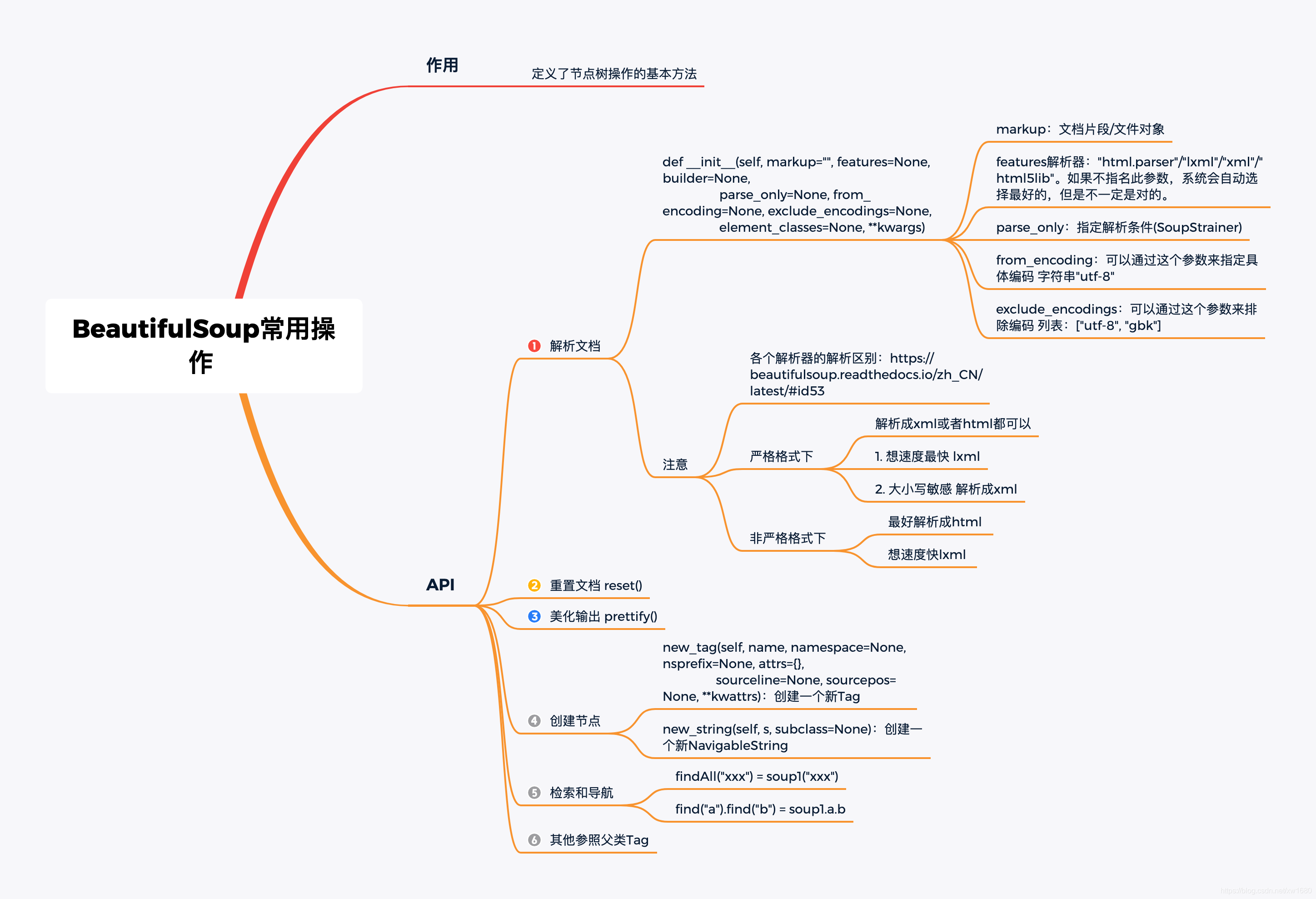
3.1 BeautifulSoup常用操作
此类作用: 定义了节点树操作的基本方法。具体用法如下图所示:
示例代码如下:
from bs4 import BeautifulSoup
str1 = """
<div><a>a1<b>b1</b></a><a>a2</a></div>
"""
soup1 = BeautifulSoup(str1, features="lxml")
print(soup1)
print(type(soup1)) # <class 'bs4.BeautifulSoup'>
# aa: 标签名 第二个参数: 命名空间 "amo":命名空间别名 最后一个参数:属性
print(soup1.new_tag("aa", "https://blog.csdn.net/xw1680", "amo", {"age": 18}))
print(soup1.new_string("hello")) # 创建文本节点
print(type(soup1.new_string("hello"))) # 查看类型:<class 'bs4.element.NavigableString'>
print(soup1.prettify()) # 美化输出
# 检索所有的a标签
print(soup1.find("a").find("b")) # <b>b1</b>
print(soup1.a.b) # <b>b1</b>
print(soup1("a")) # [<a>a1<b>b1</b></a>, <a>a2</a>]
print(soup1.findAll("a")) # [<a>a1<b>b1</b></a>, <a>a2</a>]
soup1.reset() # 重置文档
3.2 Tag常用操作
查看及修改标签名,示例代码如下:
from bs4 import BeautifulSoup
str1 = """
<div id='main'><a>a1<b>b1</b></a><a>a2</a></div>
"""
soup1 = BeautifulSoup(str1, features="lxml")
print(soup1)
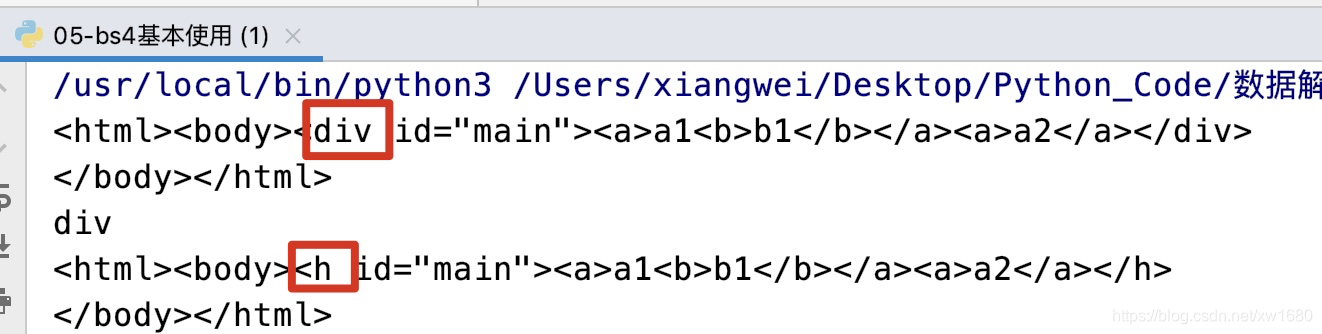
print(soup1.find("div").name) # 返回标签名: div
# 注意标签名是可以修改的
soup1.find("div").name = "h"
print(soup1)
上述代码执行结果如下:
属性相关操作,示例代码如下:
扫描二维码关注公众号,回复:
11168902 查看本文章

from bs4 import BeautifulSoup
str1 = """
<div id='main' class='main xxx'><a>a1<b>b1</b></a><a>a2</a></div>
"""
# 1.使用lxml解析器
soup1 = BeautifulSoup(str1, features="lxml")
# 判断div中是否有id属性
print(soup1.find("div").has_attr("id")) # True
# 判断div中是否有class属性
print(soup1.find("div").has_attr("class")) # True
# 一般来说一个标签对应id的值在整个页面是唯一的 而class的值可以是多个 所以解析为列表
# {'id': 'main', 'class': ['main', 'xxx']}
print(soup1.find("div").attrs) # 获取属性
# 注意如果被解析为xml 结果为: {'id': 'main', 'class': 'main xxx'}
# 获取key对应的属性值
print(soup1.find("div").attrs["id"]) # main
# 注意:get方法如果找不到key会返回None 而使用[]的方式找不到key报错
print(soup1.find("div").get("class")) # ['main', 'xxx']
# 增加修改
soup1.find("div").attrs["id"] = "box"
print(soup1)
soup1.find("div").attrs["style"] = "font-size:18px;"
# 删除属性
del soup1.find("div").attrs["id"]
print(soup1)
上述代码执行结果如下:

文本相关操作,示例代码如下:
from bs4 import BeautifulSoup
str1 = """
<div id='main' class='main xxx'><a> a1 <b>b1</b></a><a>a2</a></div>
<h1><a><span>amo</span></a></h1>
"""
# 1.使用lxml解析器
soup1 = BeautifulSoup(str1, features="lxml")
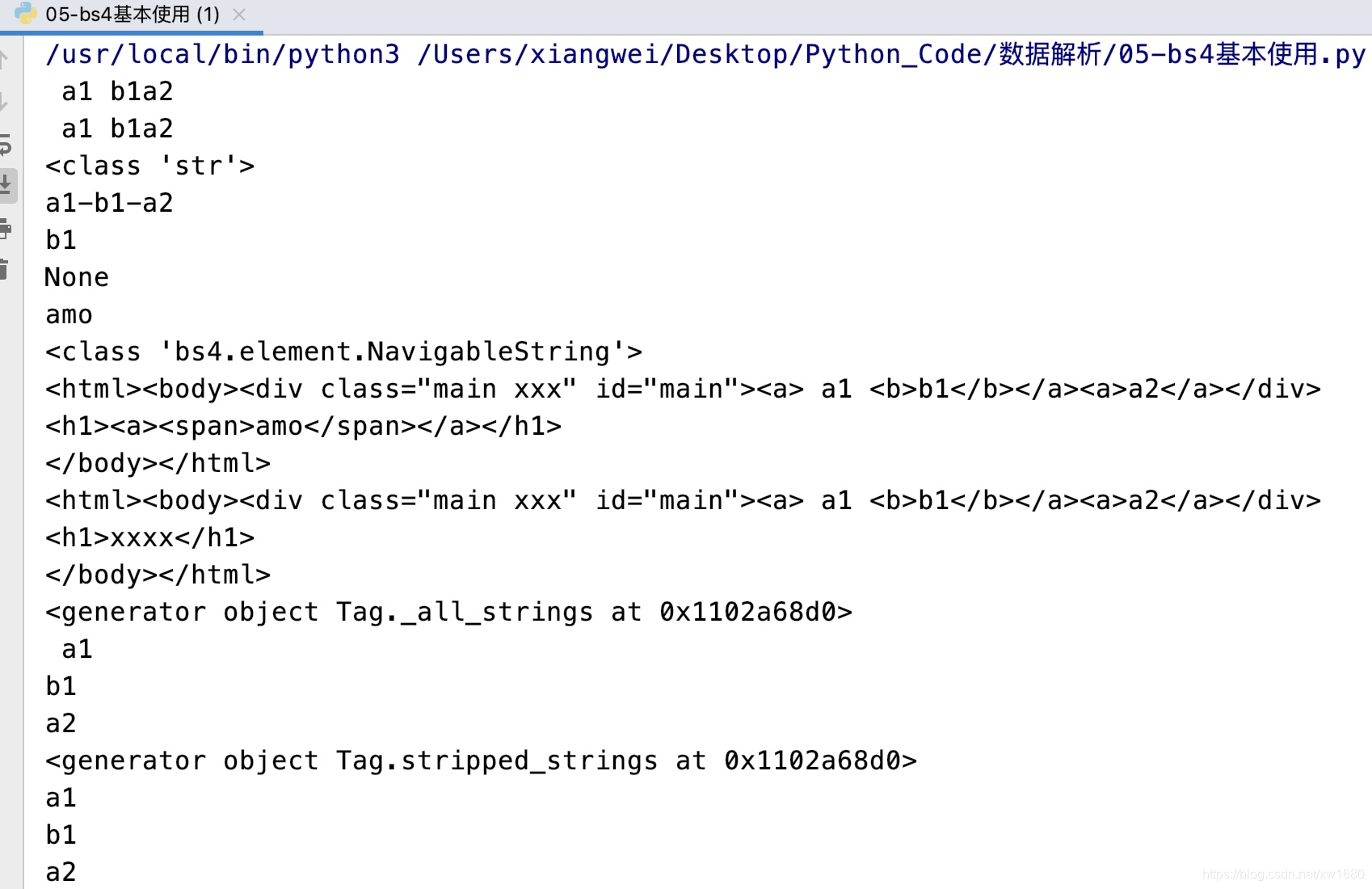
# .text: 获取所有文本内容拼接后的字符串
print(soup1.find("div").text) # a1 b1a2
print(soup1.find("div").get_text()) # a1 b1a2
print(type(soup1.find("div").text)) # <class 'str'>
# separator:指名分隔符 strip:默认为False 指是否压缩两侧空白
print(soup1.find("div").get_text(separator="-", strip=True)) # a1-b1-a2
# .string: 如果只有一个文本子节点 返回该值
print(soup1.find("b").string) # b1
# .string: 如果没有子节点,或者多于一个 返回None
print(soup1.find("div").string) # None
# 如果(递归)只有一个元素节点,返回该元素节点的string
# h1-->a-->span: amo
print(soup1.find("h1").string) # amo
print(type(soup1.find("h1").string)) # <class 'bs4.element.NavigableString'>
print(soup1)
# 所有子节点清空,只留一个文本节点
# tag.string = "new_value"
soup1.find("h1").string = "xxxx"
print(soup1)
# 获取标签内所有文本组成的生成器
# <generator object Tag._all_strings at 0x11b6ac8d0>
print(soup1.find("div").strings)
for s in soup1.find("div").strings:
print(s)
# 获取标签内所有文本(压缩文本两侧空白字符后)组成的生成器
# <generator object Tag.stripped_strings at 0x11b6ac8d0>
print(soup1.find("div").stripped_strings)
for s in soup1.find("div").stripped_strings:
print(s)
上述代码执行结果如下:
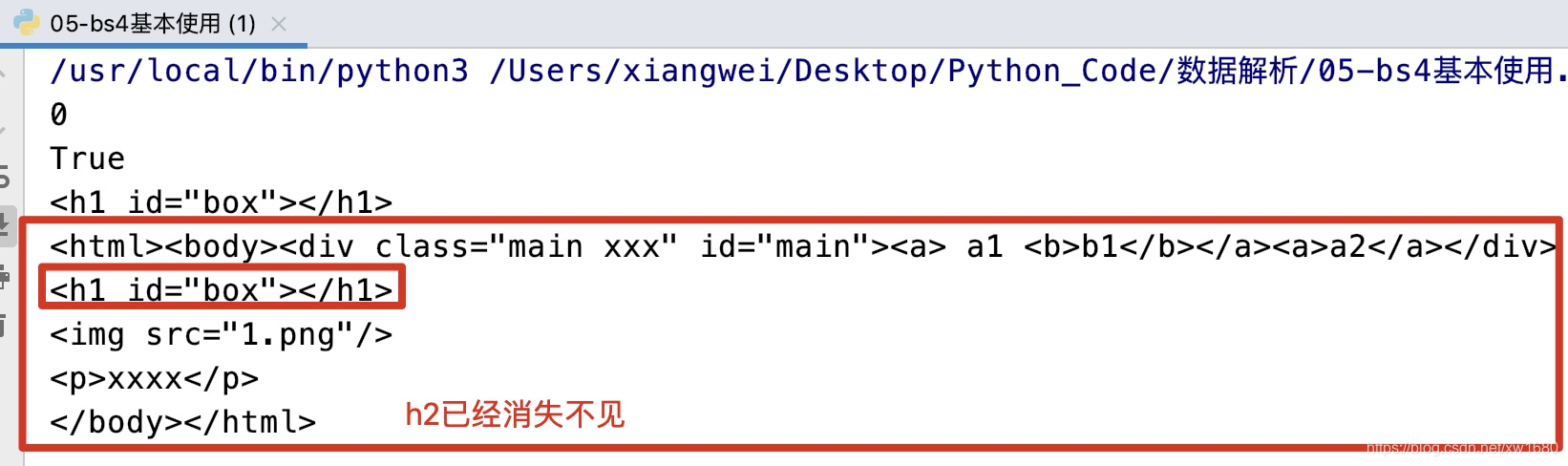
清空/删除/判定/索引等操作,示例代码如下:
from bs4 import BeautifulSoup
str1 = """
<div id='main' class='main xxx'><a> a1 <b>b1</b></a><a>a2</a></div>
<h1 id="box"><a><span>amo</span></a></h1>
<img src="1.png"/>
<h2 id="box"><p>xxxx</p></h2>
"""
# 1.使用lxml解析器
soup1 = BeautifulSoup(str1, features="lxml")
div = soup1.div
a = soup1.a
# 索引
print(div.index(a)) # 0
# 判定是否是一个空节点 自关闭
print(soup1.find("img").is_empty_element) # True
# 清空:不清空属性
soup1.find("h1").clear()
print(soup1.find("h1")) # <h1 id="box"></h1>
soup1.find("h2").decompose() # 把自己全部给干掉了
print(soup1)
上述代码执行结果如下:
节点获取,子/后代节点,示例代码如下:
from bs4 import BeautifulSoup
str1 = """
<div id='main' class='main xxx'><a> a1 <b>b1</b></a><a>a2</a></div>
<h1 id="box"><a><span>amo</span></a></h1>
<img src="1.png"/>
<h2 id="box"><p>xxxx</p></h2>
"""
# 1.使用lxml解析器
soup1 = BeautifulSoup(str1, features="lxml")
print(soup1.contents)
print("-" * 50)
print(soup1.children) # 类似于contents 一个可迭代对象
for item in soup1.children:
print(item)
print("-" * 50)
# 子孙节点 一个生成器对象:<generator object Tag.descendants at 0x11a634550>
print(soup1.descendants)
# find:
# recursive:是否递归遍历所有子孙节点,默认True
# name:查找所有名字为name的tag 字符串
print(soup1.find(name="p")) # 字符串 "p" <p>xxxx</p>
print(soup1.find(name=["p", "span"])) # 列表 先找到谁就返回谁 因为find结果只有一个 <span>amo</span>
print(soup1.find_all(name=["p", "span"])) # [<span>amo</span>, <p>xxxx</p>]
print(soup1.find(name=True)) # 匹配所有标签 name后面还可以跟函数名
print(soup1.find(name="p", recursive=False)) # None
# 按属性名和值查找
print(soup1.find(attrs={"id": "box"}))
# 用于搜素字符串 会找到.string方法与text参数值相符的tag
print(soup1.find(text="xxxx"))
print(soup1.find_all("a", limit=2)) # 从解析的字符串中可以看到a有三个 但是只返回2个
# 如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作tag的属性来搜索
# 如果要按class属性搜索,因为class是python的保留字,需要写做class_
print(soup1.find(id="box")) # <h1 id="box"><a><span>amo</span></a></h1>
# <div class="main xxx" id="main"><a> a1 <b>b1</b></a><a>a2</a></div>
print(soup1.find(class_="main xxx"))
上述代码执行结果如下:

使用css选择器进行子节点检索,常用的css选择器如下:
| 选择器 | 示例 |
|---|---|
| 通配符选择器 | *:选择所有的节点 |
| 标签选择器 | tag_name:选择特定标签名称的节点 |
| 类选择器 | .class:选择具有特定class的节点 |
| id选择器 | #id:选择具有特定id属性值的节点 |
| 属性选择器 | [attr]:选取拥有attr属性的节点 |
| 属性选择器 | [attr=“val”]:选取attr属性值等于val的节点 |
| 属性选择器 | [attr^=“val”]:选取attr属性值以val开头的节点 |
| 属性选择器 | [attr$=“val”]:选取attr属性值以val结尾的节点 |
| 属性选择器 | [attr*=“val”]:选取attr属性值包含val的节点 |
| 属性选择器 | [attr~=“val”]:选取attr属性包含多个空格分隔的属性,其中一个等于val的节点 |
| 关系选择器 | 选择器1 选择器2:选取选择器1后代节点中的选择器2 |
| 关系选择器 | 选择器1>选择器2:选取选择器1子节点中的选择器2 |
| 关系选择器 | 选择器1+选择器2:选取选择器1后面一个兄弟节点中的选择器2 |
| 关系选择器 | 选择器1~选择器2:选取选择器1后面n个兄弟节点中的选择器2 |
| 复合选择器 | 选择器1选择器2:选择同时满足两个选择器条件的节点(并且) |
| 群组选择器 | 选择器1,选择器2:选择满足两个选择器条件之1的节点(或者) |
简单示例代码如下:
from bs4 import BeautifulSoup
str1 = """
<div id="box"><p><span class="sp1">amo1</span></p><p>amo2</p></div>
"""
soup1 = BeautifulSoup(markup=str1, features="lxml")
# 选择具有id属性值的节点
# 返回结果:[<div id="box"><p><span class="sp1">amo1</span></p><p>amo2</p></div>]
print(soup1.select("#box"))
print(soup1.select(".sp1")) # [<span class="sp1">amo1</span>]
# <p><span class="sp1">amo1</span></p>
print(soup1.select_one("p"))
3.3 PageElement常用操作
节点公共操作,例如关系控制,替换节点,包装和拆解节点,提取节点,新增节点等。
- 如果只想操作文档中的部分节点, 而解析全部文档(非常耗时),解决方案:解析时, 通过SoupStrainer指定解析片段。示例代码如下:
运行结果如图所示:from bs4 import BeautifulSoup from bs4 import SoupStrainer content_str = """ <person> <name>amo</name> <pet> <dog master="amo"> <name>煤球</name> <age>2</age> <color>五彩斑斓黑</color> </dog> <cat master="amo"> <name>皮皮</name> <age>0.2</age> <color>黑白条纹</color> </cat> </pet> </person> """ # 1.创建解析条件对象 cat = SoupStrainer("cat") # 2.解析文档时 指明parse_only参数 soup = BeautifulSoup(markup=content_str, features="lxml", parse_only=cat) print(soup)
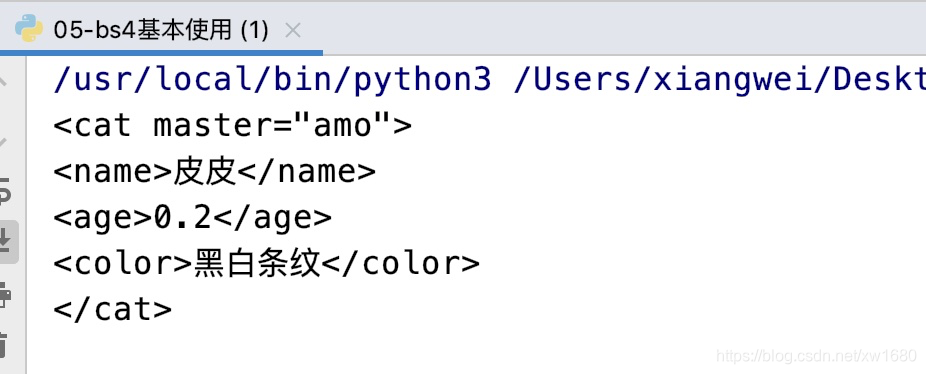
- 使用
replace_with替换节点,必须有父节点,不要使用父辈节点来替换自己,可以用来替换一个元素节点内的文本内容,示例代码如下:
运行结果如图所示:from bs4 import BeautifulSoup content_str = """ <person> <name>amo</name> <pet> <dog master="amo"> <name>煤球</name> <age>2</age> <color>五彩斑斓黑</color> </dog> <cat master="amo"> <name>皮皮</name> <age>0.2</age> <color>黑白条纹</color> </cat> </pet> </person> """ # 替换节点 <name>amo</name> ==> amo文本节点替换为xxx soup = BeautifulSoup(markup=content_str, features="lxml") soup.find(text="amo").replace_with(soup.new_string("aaa")) print(soup)
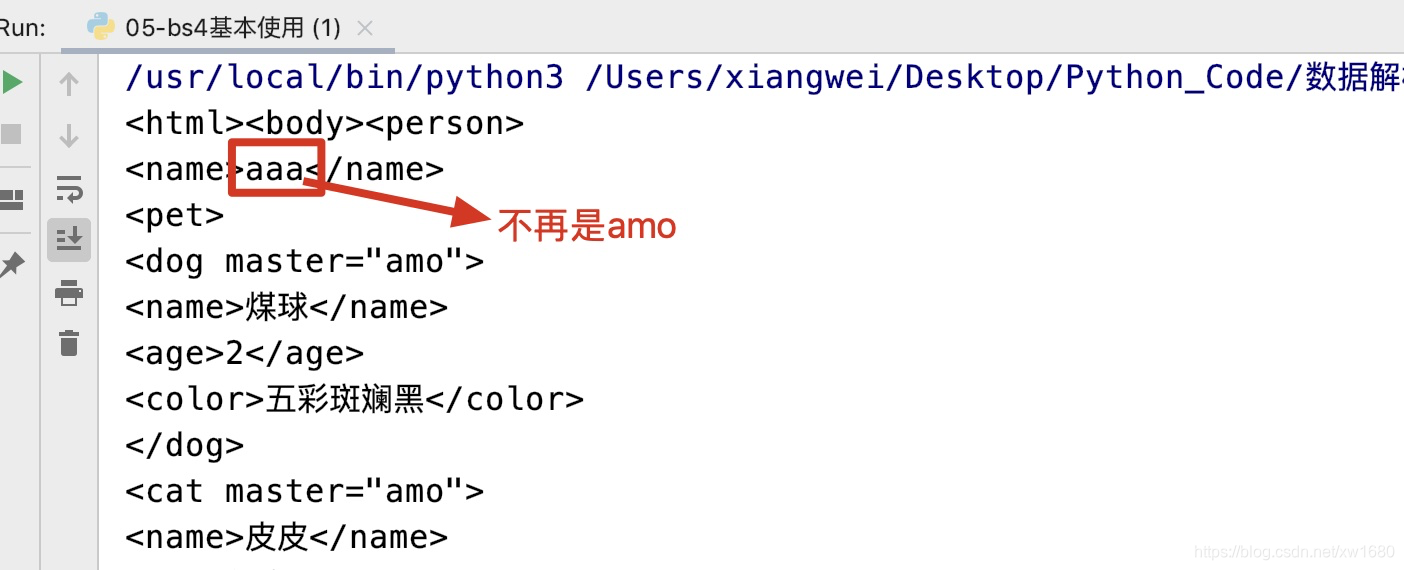
- 包装和拆解节点,示例代码如下:
运行结果如图所示:from bs4 import BeautifulSoup content_str = """ <person> <name>amo</name> <pet> <dog master="amo"> <name>煤球</name> <age>2</age> <color>五彩斑斓黑</color> </dog> <cat master="amo"> <name>皮皮</name> <age>0.2</age> <color>黑白条纹</color> </cat> </pet> </person> """ # 包装和拆解节点 soup = BeautifulSoup(markup=content_str, features="lxml") # 使用指定的tag包装自己 包装后的结果还放在self原本的位置 soup.find(text="amo").wrap(soup.find("age")) # 把自己的标签对抽离掉并返回 soup.find("cat").unwrap() print(soup)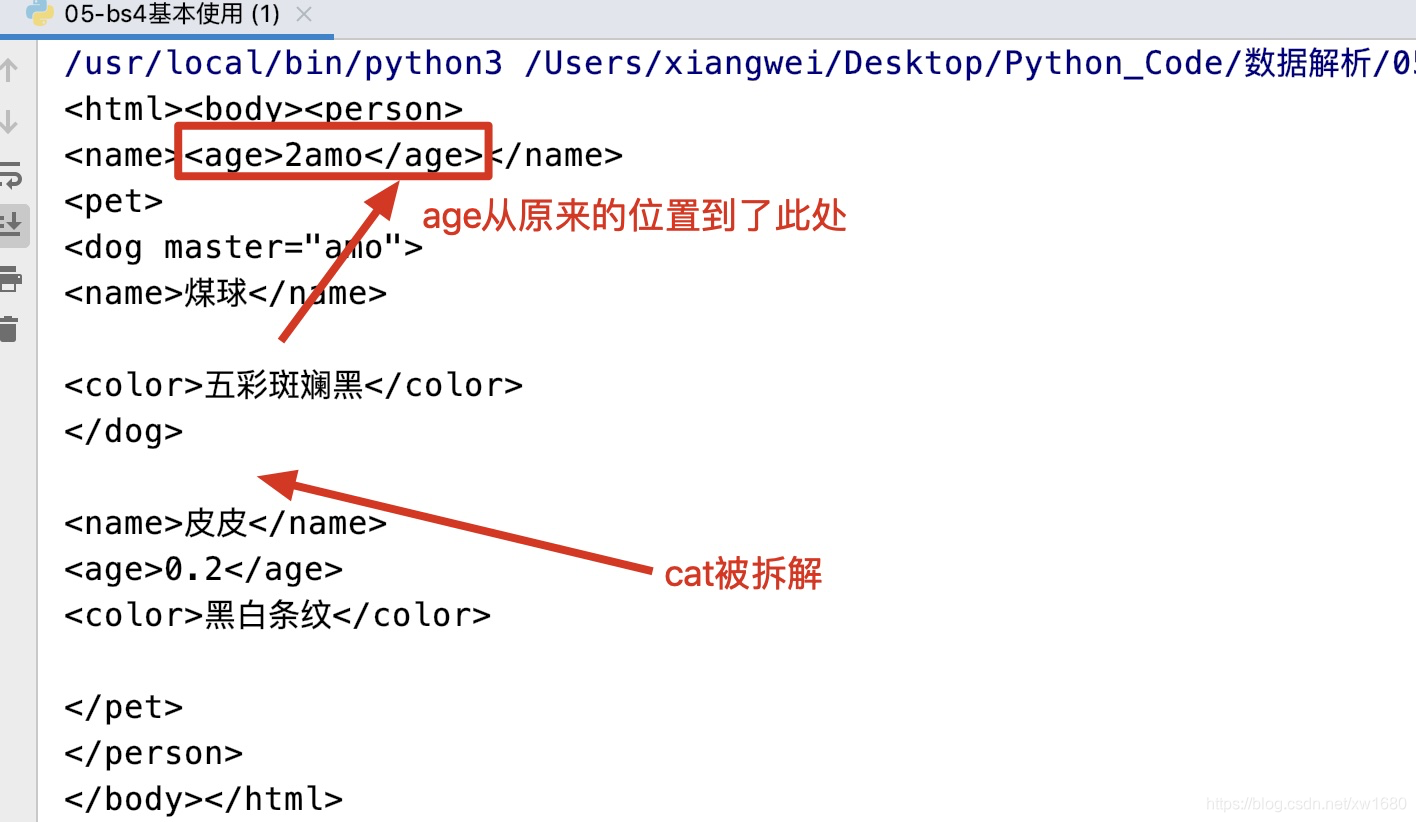
其他节点公共操作如图所示:

- 节点导航操作如下所示:
soup = BeautifulSoup(markup=content_str, features="lxml") soup.find_next() # 在子节点右侧查找 匹配一个 soup.find_all_next() # 在子节点右侧查找 匹配n个 soup.find_next_sibling() # 在节点右侧查找 兄弟关系 匹配一个 soup.find_next_siblings() # 在节点右侧查找 兄弟关系 匹配n个 soup.find_previous() # 在节点左侧查找 匹配一个 soup.find_all_previous() # 在节点左侧查找 匹配n个 soup.find_previous_sibling() # 在节点左侧查找 兄弟关系 匹配一个 soup.find_previous_siblings() # 在节点左侧查找 兄弟关系 匹配n个 soup.next # 右边一个节点 soup.next_siblings # 右边所有兄弟节点 soup.next_elements # 右边所有节点 soup.previous # 左边一个节点 soup.previous_siblings # 左边所有兄弟节点 soup.previous_elements # 左边所有节点 soup.find_parent() soup.find_parents() soup.parent() # 父节点 soup.parents # 祖先节点 # 通过 .标签名 可以访问到指定节点

