import requests
from bs4 import BeautifulSoup
url = 'http://python123.io/ws/demo.html'
r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
1.Beautiful Soup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息阻止单元, 分别用<>和</>标明开头和结尾 |
| Name | 标签的名字, <p>…</p>的名字是’p’, 格式:<tag>.name |
| Attributes | 标签的属性, 字典形式组织, 格式: <tag>.attrs |
| NavigableString | 标签内非属性字符串, <>…</>中字符串, 格式: <tag>.string |
| Comment | 标签内字符串的注释部分, 一种特殊的Comment类型 |
# Tag
# 获取网页的标题
print(soup.title)
# <title>This is a python demo page</title>
# 获取html的a标签的内容
# 默认获取第一个标签
print(soup.a)
# Name
# 获取标签的名字
print('标签名字:', soup.a.name)
# Attributes
# 获取属性信息
tag = soup.a
print(tag.attrs)
# NavigableString
# 获取a标签的字符串信息
print(soup.a.string)
# Comment
new_soup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>", "html.parser")
print(new_soup.b.string)
# This is a comment
print(type(new_soup.b.string))
# <class 'bs4.element.Comment'>
print(new_soup.p.string)
# This is not a comment
print(type(new_soup.p.string))
# <class 'bs4.element.NavigableString'>
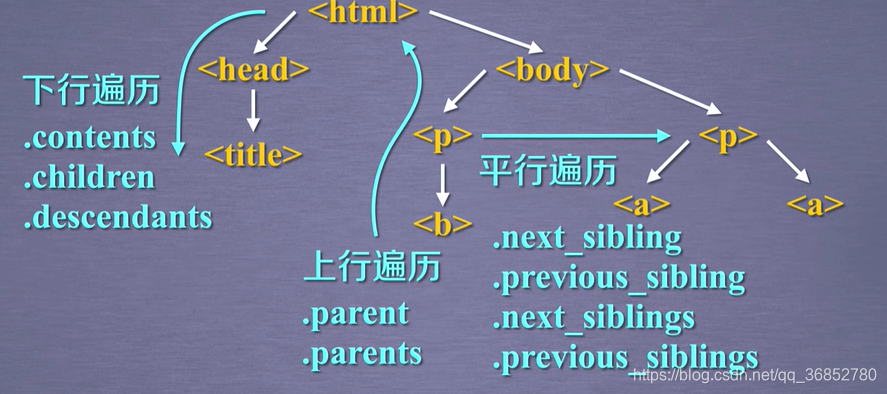
2.标签数的下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表, 将<tag>所有儿子节点存入列表 |
| .children | 子节点的迭代类型, 与.contents类似, 用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型, 包含所有子孙节点, 用于循环遍历 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
# 获取body标签下的所有节点并存入列表中
print(soup.body.contents)
print(type(soup.body.contents))
# <class 'list'>
# 遍历儿子节点
for child in soup.body.children:
print(child)
# 遍历子孙节点
for desc in soup.body.descendants:
print(desc)
3.标签树的上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型, 用于循环遍历先辈节点 |
# 标签数的上行遍历
# 遍历a标签的所有父节点
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
# title的父标签
print(soup.title.parent)
4.标签树的平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型, 返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型, 返回按照HTML文本顺序的前续所有平行节点标签 |
# 遍历后续节点
for sibling in soup.a.next_siblings:
print(sibling)
# 遍历前续节点
for sibling in soup.a.previous_siblings:
print(sibling)
总结:
5.bs4库的prettify()方法
对HTML文本或 部分标签内容进行格式化(每个标签后面都会加上换行)
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
print(soup.prettify())
print(soup.a.prettify())
6.查找方法
find_all(name, attrs, recursive, string, **kwargs) :
返回一个列表类型, 存储查找的结果.
- name: 对标签名称的检索字符串
- attrs : 对标签属性值的检索字符串, 可标注属性检索
- recursive : 是否对子孙全部检索, 默认True
- string : <>…</>中字符串区域的检索字符串
import requests
import re
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
soup = BeautifulSoup(r.text, "html.parser")
# 查找所有a标签
print(soup.find_all('a'))
print(type(soup.find_all('a')))
# <class 'bs4.element.ResultSet'>
for tag in soup.find_all('a'):
print(tag.string)
# 显示a 和 b 标签
print(soup.find_all(['a', 'b']))
# 显示soup的所有标签信息
for tag in soup.find_all(True):
print(tag.name)
# 使用正则表达式来查找含有b的标签
for tag in soup.find_all(re.compile('b')):
print(tag.name)
# 查找p标签含有course的内容
print(soup.find_all('p', 'course'))
# 查找id属性为link1的内容
print(soup.find_all(id='link1'))
# 查找id属性为link的内容 没有则返回[]
print(soup.find_all(id='link'))
# 使用re模块来查找id属性包含link的内容
print(soup.find_all(id=re.compile('link')))
# 设置recursive参数为False, 这时从soup的子节点进行检索, 而不会去检索子孙节点的内容
print(soup.find_all('a', recursive=False))
# 检索字符串是否存在
print(soup.find_all(string="Basic Python"))
# 检索字符串是否含有python, 通过re
print(soup.find_all(string=re.compile('Python')))
Tip :
<tag>(…)等价于<tag>.find_all(…)
soup(…) 等价于soup.find_all(…)
扩展方法
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果, 字符串类型, 同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索, 返回列表类型, 同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果, 字符串类型, 同.find()参数 |
| <>.find_next_siblings() | 在后序平行节点中搜索, 返回列表类型, 同.find_all()参数 |
| <>.find_next_sibling() | 在后序平行节点中返回一个结果, 字符串类型, 同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索, 返回列表类型, 同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果, 字符串类型, 同.find()参数 |
爬虫案例
