基于值函数逼近的强化学习方法-TD Q-learning非线性逼近原理见【强化学习笔记】6.1 基于值函数逼近的强化学习方法
针对一个迷宫问题,设计TD Q-learning非线性逼近算法(异策略)。
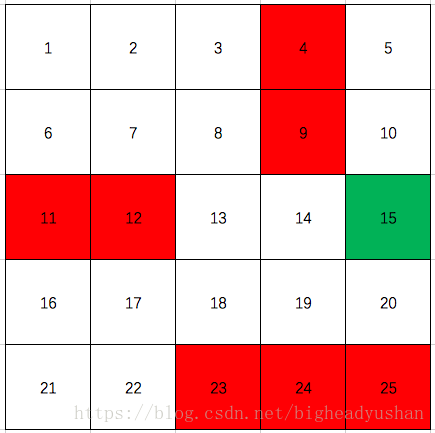
迷宫图示见下图,其中红色部分为障碍物,绿色部分为出口:
使用的模型是:非线性模型(两层神经网络)
输入是状态的特征,这里是25维的one-hot编码
输出是动作对应的4维数组
使用tensorflow进行SDG训练。
(踩过的坑:输入输出设计,权重初始化,调参,收敛性不好等)
(可以改进的地方:目标函数,输入和输出设计,改进模型参数提高训练效率,自适应调整迭代参数,解决值函数不稳定问题等)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#import gym
import random
import numpy as np
import tensorflow as tf
class GriDMdp:
def __init__(s):
s.gamma = 0.9
s.alpha = 0.8
s.epsilon = 0.1
s.states = range(1,26)
s.actions = ['n', 'e', 's', 'w']
s.terminate_states = {15:1.0, 4:-1.0, 9:-1.0, \
11:-1.0, 12:-1.0, 23:-1.0, 24:-1.0, 25:-1.0}
s.trans = {}
for state in s.states:
if not state in s.terminate_states:
s.trans[state] = {}
s.trans[1]['e'] = 2
s.trans[1]['s'] = 6
s.trans[2]['e'] = 3
s.trans[2]['w'] = 1
s.trans[2]['s'] = 7
s.trans[3]['e'] = 4
s.trans[3]['w'] = 2
s.trans[3]['s'] = 8
s.trans[5]['w'] = 4
s.trans[5]['s'] = 10
s.trans[6]['e'] = 7
s.trans[6]['s'] = 11
s.trans[6]['n'] = 1
s.trans[7]['e'] = 8
s.trans[7]['w'] = 6
s.trans[7]['s'] = 12
s.trans[7]['n'] = 2
s.trans[8]['e'] = 9
s.trans[8]['w'] = 7
s.trans[8]['s'] = 13
s.trans[8]['n'] = 3
s.trans[10]['w'] = 9
s.trans[10]['s'] = 15
s.trans[13]['e'] = 14
s.trans[13]['w'] = 12
s.trans[13]['s'] = 18
s.trans[13]['n'] = 8
s.trans[14]['e'] = 15
s.trans[14]['w'] = 13
s.trans[14]['s'] = 19
s.trans[14]['n'] = 9
s.trans[16]['e'] = 17
s.trans[16]['s'] = 21
s.trans[16]['n'] = 11
s.trans[17]['e'] = 18
s.trans[17]['w'] = 16
s.trans[17]['s'] = 22
s.trans[17]['n'] = 12
s.trans[18]['e'] = 19
s.trans[18]['w'] = 17
s.trans[18]['s'] = 23
s.trans[18]['n'] = 13
s.trans[19]['e'] = 20
s.trans[19]['w'] = 18
s.trans[19]['s'] = 24
s.trans[19]['n'] = 14
s.trans[20]['w'] = 19
s.trans[20]['s'] = 25
s.trans[20]['n'] = 15
s.trans[21]['e'] = 22
s.trans[21]['n'] = 16
s.trans[22]['e'] = 23
s.trans[22]['w'] = 21
s.trans[22]['n'] = 17
s.rewards = {}
for state in s.states:
s.rewards[state] = {}
for action in s.actions:
s.rewards[state][action] = 0
if state in s.trans and action in s.trans[state]:
next_state = s.trans[state][action]
if next_state in s.terminate_states:
s.rewards[state][action] = s.terminate_states[next_state]
s.pi = {}
for state in s.trans:
s.pi[state] = random.choice(s.trans[state].keys())
s.last_pi = s.pi.copy()
s.v = {}
for state in s.states:
s.v[state] = 0.0
def get_random_action(s, state):
s.pi[state] = random.choice(s.trans[state].keys())
return s.pi[state]
def transform(s, state, action):
next_state = state
state_reward = 0
is_terminate = True
return_info = {}
if state in s.terminate_states:
return next_state, state_reward, is_terminate, return_info
if state in s.trans:
if action in s.trans[state]:
next_state = s.trans[state][action]
if state in s.rewards:
if action in s.rewards[state]:
state_reward = s.rewards[state][action]
if not next_state in s.terminate_states:
is_terminate = False
return next_state, state_reward, is_terminate, return_info
def print_states(s):
for state in s.states:
if state in s.terminate_states:
print "*",
else:
print round(s.v[state], 2),
if state % 5 == 0:
print "|"
def get_features(s, state):
featrues = [0.0] * 25
featrues[state - 1] = 1.0
return featrues
def td_Qlearning_sigmoid_approximation(grid_mdp):
'''action_strategy is greey'''
#construct model
x_ph = tf.placeholder(tf.float32, shape=[None, 25], name="input_name")
y_ph = tf.placeholder(tf.float32, shape=[None, 4], name="output_name")
w1 = tf.Variable(tf.random_uniform([25,10], -1, 1))
w2 = tf.Variable(tf.random_uniform([10,4], -1, 1))
#w1 = tf.Variable(tf.zeros([25, 10]))
#w2 = tf.Variable(tf.zeros([10, 4]))
b1 = tf.Variable(tf.zeros([10]))
b2 = tf.Variable(tf.zeros([4]))
hidden = tf.sigmoid(tf.matmul(x_ph, w1) + b1)
y = tf.sigmoid(tf.matmul(hidden, w2) + b2)
loss = tf.reduce_mean(tf.square(y - y_ph))
optimizer = tf.train.GradientDescentOptimizer(0.1)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
feed_data_dic = {}
action_dic = {'e':0,'w':1,'s':2,'n':3}
total_loss = 0.0
for iter_idx in range(1,20000):
#print "-----------------------"
list_num = 0
one_sample_list = []
state = random.choice(grid_mdp.states)
while(state in grid_mdp.terminate_states):
state = random.choice(grid_mdp.states)
sample_end = False
while sample_end != True:
list_num += 1.0
# choose epsilon_greey strategy
action_list = grid_mdp.trans[state].keys()
len_action = len(action_list)
action_prob = [grid_mdp.epsilon / float(len_action)] * len_action
input_features = grid_mdp.get_features(state)
pred_state_action_value = sess.run(y, feed_dict = {x_ph: [input_features]})
max_idx = 0
max_val = float("-inf")
max_aidx = 0
for aidx in range(len_action):
act_idx = action_dic[action_list[aidx]]
tmp_value = pred_state_action_value[0, act_idx]
if tmp_value > max_val:
max_val = tmp_value
max_idx = aidx
max_aidx = act_idx
action_prob[max_idx] += (1.0 - grid_mdp.epsilon)
# action-strategy choose epsilon_greey strategy
action = np.random.choice(action_list, p=action_prob)
next_state, state_reward, is_terminate, return_info = grid_mdp.transform(state, action)
#print state,action, next_state, state_reward, is_terminate
# target-strategy choose greey strategy
real_y = pred_state_action_value
if next_state in grid_mdp.trans:
next_action_list = grid_mdp.trans[next_state].keys()
len_next_action = len(next_action_list)
next_action_prob = [grid_mdp.epsilon / float(len_next_action)] * len_next_action
next_input_features = grid_mdp.get_features(next_state)
next_pred_state_action_value = sess.run(y, feed_dict = {x_ph: [next_input_features]})
next_max_idx = 0
next_max_val = float("-inf")
next_max_aidx = 0
for next_aidx in range(len_next_action):
next_act_idx = action_dic[next_action_list[next_aidx]]
next_tmp_value = next_pred_state_action_value[0, next_act_idx]
if next_tmp_value > next_max_val:
next_max_val = next_tmp_value
next_max_idx = next_aidx
next_max_aidx = next_act_idx
next_action_idx = next_max_aidx
#print next_pred_state_action_value, next_action_idx
difference = state_reward + grid_mdp.gamma * next_pred_state_action_value[0, next_action_idx] - pred_state_action_value[0, max_aidx]
real_y[0, max_aidx] += grid_mdp.alpha * difference
else:
difference = state_reward - pred_state_action_value[0, max_aidx]
real_y[0, max_aidx] += grid_mdp.alpha * difference
# train
feed_data = {x_ph: [np.array(input_features)], y_ph: real_y}
#feed_data_dic[iter_idx % 101] = feed_data
#random_idx = 1
#if len(feed_data_dic) > 2:
# random_idx = random.randint(1, len(feed_data_dic) - 1)
#feed_data = feed_data_dic[random_idx]
sess.run(train, feed_dict = feed_data)
total_loss += sess.run(loss, feed_data)
state = next_state
sample_end = is_terminate
if iter_idx % 100 == 0:
print "-"*18 + str(iter_idx) + "-"*18
iter_para = 0.01
#iter_para = 0.01/(float(iter_idx/100)**0.5)
print "total_loss: ", total_loss / list_num, "iter_para: ", iter_para, "cpacity:"
total_loss = 0.0
#optimizer = tf.train.GradientDescentOptimizer(iter_para)
for state in grid_mdp.trans:
input_features = grid_mdp.get_features(state)
pred_state_action_value = sess.run(y, feed_dict = {x_ph: [input_features]})
max_idx = np.argwhere(pred_state_action_value[0,] == pred_state_action_value[0,].max())[0,0]
for action in action_dic:
if action_dic[action] == max_idx:
print state, action, pred_state_action_value
sess.close()
grid_mdp = GriDMdp()
td_Qlearning_sigmoid_approximation(grid_mdp)
欢迎关注微信公众号:AITBOOK

