在强化学习(五):Sarsa算法与Q-Learning的学习中,我们都是假设状态是有限的,而且数量也不多,就像例程中都是使用格子世界,每个格子代表一个状态。
但是,现在让我们来假设我们在下围棋,每下一个子就是一种状态,那么这些状态就非常多了,如果在程序中要用一个表格来表示状态与状态对应的值函数的话,那么内存就远远不够用了。
另外,当状态不是离散的时候,就无法用表格来表示了。所以,我们需要另外的方法来表示状态与状态对应的值函数。这就引出了今天要讲的内容:价值函数的逼近(近似)。
价值函数的逼近
价值函数的逼近其实就是用一个函数来估计值函数(estimate value function with function approximation)。这个函数的输入就是状态s,输出就是状态s对应的值。
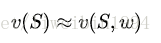
w表示引入的参数。
近似函数具体可以使用线性组合,神经网络以及其他方法。有了近似函数,不仅可以解决上面的两个问题,同时也是做了一种归纳,可以概括出没有遇到过的状态。
具体来说,根据输入和输出的不同,有三种不同的近似方法:
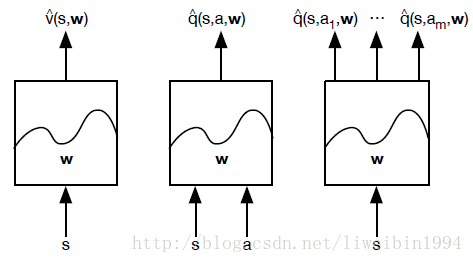
接下来,你能想到的问题就是:s和a的形式是什么,一个向量吗?如果是监督学习来学习出参数w,那么我们需要label,也就是真正的v值,但是我们如何得到真正的v值呢?
Gradient Descent
在解释上面的问题之前,我们先来看看什么是梯度,梯度下降能够用来干嘛。显然,我们想要得到w,一般就是利用神经网络或者线性回归,而这两个都需要依赖梯度下降来更新参数。
对一个函数
的梯度:
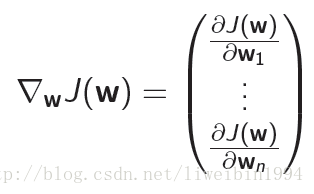
我们的目标就是调整参数朝着负梯度的方向,找到
的局部最小值。所以我们的目标如下图所示:

上图其实就是典型的利用梯度下降寻找最小值的过程。
feature vector
如何定义特征向量,也就是如何用一个特征向量来表示一个状态s,让它可以作为输入。

“查表”方法是一个特殊的线性价值函数近似方法:每一个状态看成一个特征,个体具体处在某一个状态时,该状态特征取1,其余取0。类似于one-hot向量一样。所以我们可以用线性组合来近似价值函数。

事实上,上面的公式都是无法直接在强化学习中使用的。因为在这里我们都是假设已经知道了真实值
。然而在强化学习中,我们是不知道真实值的。也就是强化学习没有监督数据。
因此,我们的做法其实是:

如上图所示,我们用估计值代替真实值 。
Batch Methods

假设有一个价值函数的近似。以及一段时期的经历D。如上图所示,D是使用TD learning或者其他方法估计到的v值。我们现在就是想要找到一组参数w来近似这组数据D。
具体的做法如下:

批处理方法应用于DQN
DQN算法的特点如下:
1. 依据Ɛ-greedy执行策略产生t时刻的行为;
2. 将大量经历数据(例如百万级的)以 (s_t, a_t, r_{t+1}, s_{t+1}) 存储在内存里,作为D大块;
3. 从D大块中随机抽取小块(例如64个样本数据)数据 (s, a, r, s’) ;
4. 维护两个神经网络DQN1,DQN2,一个网络固定参数专门用来产生目标值,目标值相当于标签数据。另一个网络专门用来评估策略,更新参数。
5. 优化关于Q网络和Q目标值之间的最小平方差:
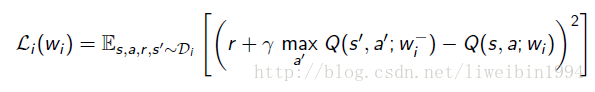
- 用随机梯度下降的方式更新参数。
首先,随机采样打破了状态之间的联系;第二个神经网络会暂时冻结参数,我们从冻结参数的网络而不是从正在更新参数的网络中获取目标值,这样增加了算法的稳定性。经过一次批计算后,把冻结参数的网络换成更新的参数再次冻结产生新一次迭代时要用的目标值。
Deep Q-Learning Network
所以DQN的算法伪代码如下:

DQN的本质是Q-Learning算法。我们知道Q-Learning算法中,状态和动作都是有限的,但是在现实世界中,可能是连续的状态或者连续的动作空间,那么这时候就无法用离散的形式保存Q(s,a)的值了,于是DQN就是用来解决这个问题的。
参考:
David Silver 强化学习公开课
https://zhuanlan.zhihu.com/p/28223841