论文:Safe Reinforcement Learning with Linear Function Approximation
下载地址:http://proceedings.mlr.press/v139/amani21a/amani21a.pdf
会议/年份:PMLR / 2021
Word版本下载地址(辛辛苦苦打出来的):https://download.csdn.net/download/baishuiniyaonulia/85863332
本文翻译属于半人工,有错漏请谅解。
文章目录
摘要、1、2、3
基于线性函数近似的安全强化学习 Safe RL with Linear Function Approximation 翻译 1 —— https://blog.csdn.net/baishuiniyaonulia/article/details/125504660
4. 扩展到随机化的策略选择 Extension to randomized policy selection
第 2 节中介绍的 SLUCB-QVI 只能输出确定性策略。 在本节中,我们表明我们的结果可以扩展到随机策略选择的设置,这在实践中可能是可取的。 随机策略 π : S × [ H ] → Δ A \pi :\mathcal{S}\times [H]\to { {\Delta }_{\mathcal{A}}} π:S×[H]→ΔA 将状态和时间步映射到动作上的分布,使得 a ∼ π ( s , h ) a\sim \pi (s,h) a∼π(s,h) 是策略 π 建议智能体在处于状态 s ∈ S s\in \mathcal{S} s∈S 时在时间步 h ∈ [ H ] h\in [H] h∈[H] 执行的动作。 在每个情节 k 和时间步 h ∈ [ H ] h\in [H] h∈[H] 中,当处于状态 s h k s_{h}^{k} shk 时,智能体必须从 a 中提取其动作 a h k a_{h}^{k} ahk 安全策略 π k ( s h k , h ) { {\pi }_{k}}\left( s_{h}^{k},h \right) πk(shk,h) 使得 E a h k ∼ π k ( s h k , h ) c h ( s h k , a h k ) ≤ τ { {\mathbb{E}}_{a_{h}^{k}\sim{ {\pi }_{k}}\left( s_{h}^{k},h \right)}}{ {c}_{h}}\left( s_{h}^{k},a_{h}^{k} \right)\le \tau Eahk∼πk(shk,h)ch(shk,ahk)≤τ概率很高。 我们相应地定义了一组未知的安全策略 Π ~ safe : = { π : π ( s , h ) ∈ Γ h safe ( s ) , ∀ ( s , h ) ∈ S × [ H ] } { {\tilde{\Pi }}^{\text{safe }}}:=\left\{ \pi :\pi (s,h)\in \Gamma _{h}^{\text{safe }}(s),\forall (s,h)\in \mathcal{S}\times [H] \right\} Π~safe :={ π:π(s,h)∈Γhsafe (s),∀(s,h)∈S×[H]}
其中 Γ h safe ( s ) : = { θ ∈ Δ A : E a ∼ θ c h ( s , a ) ≤ τ } \Gamma _{h}^{\text{safe}}(s):=\left\{ \theta \in { {\Delta }_{\mathcal{A}}}:{ {\mathbb{E }}_{a\sim\theta }}{ {c}_{h}}(s,a)\le \tau \right\} Γhsafe(s):={ θ∈ΔA:Ea∼θch(s,a)≤τ}。因此,在第 k 回合的时间步 h ∈ [ H ] h\in [H] h∈[H] 观察状态 s h k s_{h}^{k} shk 之后,智能体的策略选择必须属于 Γ h safe ( s h k ) \Gamma _{h}^{\text {safe}}(s_{h}^{k}) Γhsafe(shk) 概率很高。在这个公式中,策略 π 的(动作)价值函数定义中的期望值超过了环境和策略 π 的随机性。我们用 V ~ h π \tilde{V}_{h}^{\pi } V~hπ 和 Q ~ h π \tilde{Q}_{h}^{\pi } Q~hπ 来表示它们,以区别于 V ~ h π \tilde{V}_{h }^{\pi } V~hπ 和 Q ~ h π \tilde{Q}_{h}^{\pi } Q~hπ 在 (2) 和 (3) 中定义,用于确定性策略 π。令 π ∗ { {\pi }_{*}} π∗ 为最优安全策略,使得 V ~ h π ∗ ( s ) : = V ~ h ∗ ( s ) = sup π ∈ Π ~ safe V ~ h π ( s ) \tilde{V}_{h}^{ { {\pi }_{*}}}(s):=\tilde {V}_{h}^{*}(s)=\underset{\pi \in { { {\tilde{\Pi }}}^{\text{safe }}}}{\mathop{\sup } }\,\tilde{V}_{h}^{\pi }(s) V~hπ∗(s):=V~h∗(s)=π∈Π~safe supV~hπ(s) 对于所有 ( s , h ) ∈ S × [ H ] (s,h)\in \mathcal{S}\times [H] (s,h)∈S×[H]。因此,对于所有 ( a , s , h ) ∈ A × S × [ H ] (a,s,h)\in \mathcal{A}\times \mathcal{S}\times [H] (a,s,h)∈A×S×[H],安全策略的贝尔曼方程 π ∈ Π ~ safe \pi \in { {\tilde{ \Pi }}^{\text{safe }}} π∈Π~safe 和最优安全策略是
Q ~ h π ( s , a ) = r h ( s , a ) + [ P h V ~ h + 1 π ] ( s , a ) , V ~ h π ( s ) = E a ∼ π ( s , h ) [ Q ~ h π ( s , a ) ] , \begin{aligned} & \tilde{Q}_{h}^{\pi }(s,a)={ {r}_{h}}(s,a)+\left[ { {\mathbb{P}}_{h}}\tilde{V}_{h+1}^{\pi } \right](s,a), \\ & \quad \tilde{V}_{h}^{\pi }(s)={ {\mathbb{E}}_{a\sim\pi (s,h)}}\left[ \tilde{Q}_{h}^{\pi }(s,a) \right], \\ \end{aligned} Q~hπ(s,a)=rh(s,a)+[PhV~h+1π](s,a),V~hπ(s)=Ea∼π(s,h)[Q~hπ(s,a)], Q ~ h ∗ ( s , a ) = r h ( s , a ) + [ P h V ~ h + 1 ∗ ] ( s , a ) , V ~ h ∗ ( s ) = max θ ∈ Γ h safe ( s ) E a ∈ θ [ Q ~ h ∗ ( s , a ) ] , \begin{aligned} & \tilde{Q}_{h}^{*}(s,a)={ {r}_{h}}(s,a)+\left[ { {\mathbb{P}}_{h}}\tilde{V}_{h+1}^{*} \right](s,a), \\ & \tilde{V}_{h}^{*}(s)={ {\max }_{\theta \in \Gamma _{h}^{\text{safe }(s)}}}{ {\mathbb{E}}_{a\in \theta }}\left[ \tilde{Q}_{h}^{*}(s,a) \right], \\ \end{aligned} Q~h∗(s,a)=rh(s,a)+[PhV~h+1∗](s,a),V~h∗(s)=maxθ∈Γhsafe (s)Ea∈θ[Q~h∗(s,a)],
其中 V ~ H + 1 π ( s ) = V ~ H + 1 ∗ ( s ) = 0 \tilde{V}_{H+1}^{\pi }(s)=\tilde{V}_{H+1}^{*}(s)=0 V~H+1π(s)=V~H+1∗(s)=0,定义了累积后悔 如 R K : = ∑ k = 1 K V ~ 1 ∗ ( s 1 k ) − V ~ 1 π k ( s 1 k ) { {R}_{K}}:=\sum\limits_{k=1}^{K}{\tilde{V}_{1}^{*}}(s_{1}^{k})-\tilde{V}_{1}^{ { {\pi }_{k}}}(s_{1}^{k}) RK:=k=1∑KV~1∗(s1k)−V~1πk(s1k)。 (11) 中的安全约束定义使我们摆脱了对集合 D ( s ) : = { ϕ ( s , a ) : a ∈ A } \mathcal{D}(s):=\{\phi (s,a):a\in \mathcal{A}\} D(s):={ ϕ(s,a):a∈A} 的星凸假设 (假设 5),这是确定性策略选择方法所必需的。 我们建议对 SLUCB-QVI 进行修改,以适应这种新的配方,称为随机 SLUCB-QVI (RSLUCB-QVI)。 这种新算法还实现了与 SLUCB-QVI 相同阶次的亚线性后悔,即 O ~ ( κ d 3 H 3 T ) \widetilde{\mathcal{O}}\left( \kappa \sqrt{ { {d}^{3}} { {H}^{3}}T} \right) O (κd3H3T).
虽然与 SLUCB-QVI(参见(1))中考虑的安全约束相比,RSLUCB-QVI 尊重了更温和的安全约束定义(参见(11)),但它仍然比其他现有算法通过随机策略选择解决 CMDP 具有显着优势 (Efroni 等人,2020;Turchetta 等人,2020;Garcelon 等人,2020;Zheng 和 Ratliff,2020;Ding 等人,2020a;Qiu 等人,2020;Ding 等人,2020b;Xu 等人,2020 年;Kalagarla 等人,2020 年)。 首先,这些算法中考虑的安全约束是由低于某个阈值的时间范围内的累积预期成本定义的,而 RSLUCB-QVI 保证在执行动作的每个时间步(而不是时间范围内)产生的预期成本 小于阈值。 其次,即使对于安全约束的这种更宽松的定义,这些算法在约束满足方面所能保证的最好的方法是约束违反次数的亚线性界限,而 RSLUCB-QVI 确保没有约束违反。
4.1. 随机SLUCB-QVI Randomized SLUCB-QVI
我们现在描述算法 2 中总结的 RSLUCB-QVI。令 ϕ θ ( s ) : = E a ∼ θ ϕ ( s , a ) {
{\phi }^{\theta }}(s):={
{\mathbb{E}}_{a\sim\theta }}\phi (s ,a) ϕθ(s):=Ea∼θϕ(s,a)。 在每个情节 k ∈ [ K ] k\in [K] k∈[K] 中,在第一个循环中,智能体计算所有 $s 的真实未知集 Γ h safe ( s ) \Gamma _{h}^{\text{safe}}(s) Γhsafe(s) 的估计集 s ∈ S s\in \mathcal{S} s∈S 如下:
Γ h k ( s ) : = { θ ∈ Δ A : E a ∼ θ [ ⟨ Φ 0 ( s , ϕ ( s , a ) ) , ϕ ~ ( s , a 0 ( s ) ) ⟩ ∥ ϕ ( s , a 0 ( s ) ) ∥ 2 τ h ( s ) ] + max ν ∈ C h k ( s ) ⟨ Φ 0 ⊥ ( s , E a ∼ θ [ ϕ ( s , a ) ] ) , ν ⟩ ≤ τ } \Gamma _{h}^{k}(s):=\left\{ \theta \in {
{\Delta }_{\mathcal{A}}}:{
{\mathbb{E}}_{a\sim\theta }}\left[ \frac{\left\langle {
{\Phi }_{0}}(s,\phi (s,a)),\widetilde{\phi }\left( s,{
{a}_{0}}(s) \right) \right\rangle }{
{
{\left\| \phi \left( s,{
{a}_{0}}(s) \right) \right\|}_{2}}}{
{\tau }_{h}}(s) \right] \right.\left. +\underset{\nu \in \mathcal{C}_{h}^{k}(s)}{\mathop{\max }}\,\left\langle \Phi _{0}^{\bot }\left( s,{
{\mathbb{E}}_{a\sim\theta }}[\phi (s,a)] \right),\nu \right\rangle \le \tau \right\} Γhk(s):=⎩⎨⎧θ∈ΔA:Ea∼θ⎣⎡∥ϕ(s,a0(s))∥2⟨Φ0(s,ϕ(s,a)),ϕ
(s,a0(s))⟩τh(s)⎦⎤+ν∈Chk(s)max⟨Φ0⊥(s,Ea∼θ[ϕ(s,a)]),ν⟩≤τ}
= { θ ∈ Δ A : ⟨ Φ 0 ( s , ϕ θ ( s ) ) , ϕ ~ ( s , a 0 ( s ) ) ⟩ ∥ ϕ ( s , a 0 ( s ) ) ∥ 2 τ h ( s ) + ⟨ γ h , s k , Φ 0 ⊥ ( s , ϕ θ ( s ) ) ⟩ + β ∥ Φ 0 ⊥ ( s , ϕ θ ( s ) ) ∥ ( A h , s k ) − 1 ≤ τ } =\left\{ \theta \in { {\Delta }_{\mathcal{A}}}:\frac{\left\langle { {\Phi }_{0}}\left( s,{ {\phi }^{\theta }}(s) \right),\tilde{\phi }\left( s,{ {a}_{0}}(s) \right) \right\rangle }{ { {\left\| \phi \left( s,{ {a}_{0}}(s) \right) \right\|}_{2}}}{ {\tau }_{h}}(s)+\left\langle \gamma _{h,s}^{k},\Phi _{0}^{\bot }\left( s,{ {\phi }^{\theta }}(s) \right) \right\rangle +\beta { {\left\| \Phi _{0}^{\bot }\left( s,{ {\phi }^{\theta }}(s) \right) \right\|}_{ { {\left( \mathbf{A}_{h,s}^{k} \right)}^{-1}}}}\le \tau \right\} =⎩⎨⎧θ∈ΔA:∥ϕ(s,a0(s))∥2⟨Φ0(s,ϕθ(s)),ϕ~(s,a0(s))⟩τh(s)+⟨γh,sk,Φ0⊥(s,ϕθ(s))⟩+β∥∥Φ0⊥(s,ϕθ(s))∥∥(Ah,sk)−1≤τ⎭⎬⎫
请注意,由于 MDP 的线性结构,我们可以再次通过线性形式 ⟨ w ~ h ∗ , ϕ ( s , a ) ⟩ \left\langle \mathbf{\tilde{w}}_{h}^{*},\phi (s,a) \right\rangle ⟨w~h∗,ϕ(s,a)⟩参数化 Q ~ h ∗ ( s , a ) \tilde{Q}_{h}^{*}(s,a) Q~h∗(s,a) , 其中 w ~ h ∗ : = θ h ∗ + ∫ S V ~ h + 1 ∗ ( s ′ ) d μ ( s ′ ) \mathbf{\tilde{w}}_{h}^{*}:=\theta _{ h}^{*}+\int_{\mathcal{S}}{\tilde{V}_{h+1}^{*}}({s}')d\mu ({s}') w~h∗:=θh∗+∫SV~h+1∗(s′)dμ(s′)。 在下一步中,对于所有 ( s , a ) ∈ S × A (s,a)\in \mathcal{S}\times \mathcal{A} (s,a)∈S×A,智能体计算 Q ~ h k ( s , a ) = ⟨ w ~ h k , ϕ ( s , a ) ⟩ + κ h ( s ) β ∥ ϕ ( s , a ) ∥ ( A h k ) − 1 \tilde{Q}_{h}^{k}(s,a)=\left\langle \mathbf{\tilde{w}}_{h}^{k},\phi (s,a) \right\rangle +{ {\kappa }_{h}}(s)\beta { {\left\| \phi (s,a) \right\|}_{ { {\left( \mathbf{A}_{h}^{k} \right)}^{-1}}}} Q~hk(s,a)=⟨w~hk,ϕ(s,a)⟩+κh(s)β∥ϕ(s,a)∥(Ahk)−1
其中 w ~ h ∗ : = ( A h k ) − 1 w i d e t i l d e b h k \mathbf{\tilde{w}}_{h}^{*}:={ {\left( \mathbf{A}_{h}^{k} \right)}^{-1}}\ widetilde{\mathbf{b}}_{h}^{k} w~h∗:=(Ahk)−1 widetildebhk 是由 Gram 矩阵 $ 计算的 w ~ h ∗ \mathbf{\tilde{w}}_{h}^{*} w~h∗ 的正则化最小二乘估计量\mathbf{A}_{h}^{k}$ 和 b ~ h k : = ∑ j = 1 k − 1 ϕ h j [ r h j + min { max θ ∈ Γ h + 1 k ( s h + 1 j ) E a ∼ θ [ Q ~ h + 1 k ( s h + 1 j , a ) ] , H } ] \widetilde{\mathbf{b}}_{h}^{k}:=\sum\limits_{j=1}^{k-1} {\phi _{h}^{j}}\left[ r_{h}^{j}+\min \left\{ { {\max }_{\theta \in \Gamma _{h+1}^ {k}\left( s_{h+1}^{j} \right)}}{ {\mathbb{E}}_{a\sim\theta }}\left[ \tilde{Q}_{h+ 1}^{k}\left( s_{h+1}^{j},a \right) \right],H \right\} \right] b hk:=j=1∑k−1ϕhj[rhj+min{ maxθ∈Γh+1k(sh+1j)Ea∼θ[Q~h+1k(sh+1j,a)],H}]。在第一个循环中的这些计算之后,智能体从分布 Γ h k ( s h k ) \Gamma _{h}^{k}\left( s_{h}^{k} \right) Γhk(shk) 中绘制动作 a h k a_{h}^{k} ahk在第二个循环中。定义 V ~ h k ( s ) : = min { max θ ∈ Γ h k ( s ) E a ∼ θ [ Q ~ h k ( s , a ) ] , H } \tilde{V}_{h}^{k}(s):=\min \left\{ { {\max }_{\theta \in \Gamma _{h}^{k}(s) }}{ {\mathbb{E}}_{a\sim\theta }}\left[ \tilde{Q}_{h}^{k}(s,a) \right],H \right\} V~hk(s):=min{ maxθ∈Γhk(s)Ea∼θ[Q~hk(s,a)],H} , 和 E 3 : = { ∣ ⟨ w ~ h k , ϕ ( s , a ) ⟩ − Q ~ h π ( s , a ) − [ P h V ~ h + 1 π − V ~ h + 1 k ] ( s , a ) ∣ ≤ β ∥ ϕ ( s , a ) ∥ ( A h k ) − 1 , ∀ ( a , s , h , k ) ∈ A × S × [ H ] × [ K ] } { {\mathcal{E}}_{3}}:=\left\{ \left| \left\langle \mathbf{\tilde{w}}_{h}^{k},\phi (s,a) \right\rangle -\tilde{Q}_{h}^{\pi } \right. \right.\left. (s,a)-\left[ { {\mathbb{P}}_{h}}\tilde{V}_{h+1}^{\pi }-\tilde{V}_{h+1}^{k} \right](s,a) \right|\left. \le \beta { {\left\| \phi (s,a) \right\|}_{ { {\left( \mathbf{A}_{h}^{k} \right)}^{-1}}}},\forall (a,s,h,k)\in \mathcal{A}\times \mathcal{S}\times [H]\times [K] \right\} E3:={ ∣∣∣⟨w~hk,ϕ(s,a)⟩−Q~hπ(s,a)−[PhV~h+1π−V~h+1k](s,a)∣∣∣≤β∥ϕ(s,a)∥(Ahk)−1,∀(a,s,h,k)∈A×S×[H]×[K]}。
可以很容易地证明,定理 2 中所述的结果适用于专注于随机策略的设置,即在假设 1、2、3 和 4 下,并且根据定理 1 中 β 的定义,概率至少为 1 − 2 δ 1- 2\delta 1−2δ,事件 E ~ : = E 1 ⋂ E 3 \widetilde{\mathcal{E}}:={ {\mathcal{E}}_{1}}\bigcap { {\mathcal{E}}_{3}} E :=E1⋂E3 成立。 因此,作为命题 1 的直接结论,保证以 E 1 { {\mathcal{E}}_{1}} E1 为条件, Γ h k ( s ) \Gamma _{h}^{k}(s) Γhk(s) 内的所有策略是安全的,即 Γ h k ( s ) ⊂ Γ h safe ( s ) \Gamma _{h}^{k}(s)\subset \Gamma _{h}^{\text{safe}}(s) Γhk(s)⊂Γhsafe(s)。 现在,在下面的引理中,我们量化了 κ h ( s ) { {\kappa }_{h}}(s) κh(s)。
引理 2 (面对 RSLUCB-QVI 安全约束的乐观态度) Lemma 2 (Optimism in the face of safety constraint in RSLUCB-QVI)
令 κ h ( s ) : = 2 H τ − τ h ( s ) + 1 { {\kappa }_{h}}(s):=\frac{2H}{\tau -{ {\tau }_{h}}(s)}+1 κh(s):=τ−τh(s)2H+1 和假设 1,2,3 ,4 保持。 然后,以事件 E ~ \widetilde{\mathcal{E}} E 为条件,它认为 V ~ h ∗ ( s ) ≤ V ~ h k ( s ) , ∀ ( s , h , k ) ∈ S × [ H ] × [ K ] \tilde{V}_{h}^{*}(s)\le \tilde{V}_{h}^{ k}(s),\forall (s,h,k)\in \mathcal{S}\times [H]\times [K] V~h∗(s)≤V~hk(s),∀(s,h,k)∈S×[H]×[K]。
证明包含在附录 B.1 中。 使用引理 2,我们证明 Q ~ h ∗ ( s , a ) ≤ Q ~ h k ( s , a ) \tilde{Q}_{h}^{*}(s,a)\le \tilde{Q}_{h}^{k}(s,a) Q~h∗(s,a)≤Q~hk(s,a), f o r a l l ( a , s , h , k ) ∈ A × S × [ H ] × [ K ] \ forall (a,s,h,k)\in \mathcal{A}\times \mathcal{S}\times [H]\times [K] forall(a,s,h,k)∈A×S×[H]×[K]。 这突出了 RSLUCB-QVI 的 UCB 特性,使我们能够利用不安全的 LSVI-UCB (Jin et al., 2020) 的标准分析来建立后悔界。
定理 3 (RSLUCB-QVI 的遗憾) Theorem 3 (Regret of RSLUCB-QVI)
在假设 1、2、3 和 4 下,存在一个绝对常数 c β > 0 {
{c}_{\beta }}>0 cβ>0 使得对于任何固定的 δ ∈ ( 0 , 1 / 3 ) \delta \in (0,1/3) δ∈(0,1/3),并且 定理 1 中 β 的定义,如果我们设 κ h ( s ) : = 2 H τ − τ h ( s ) + 1 {
{\kappa }_{h}}(s):=\frac{2H}{\tau -{
{\tau }_{h}}(s)} +1 κh(s):=τ−τh(s)2H+1,

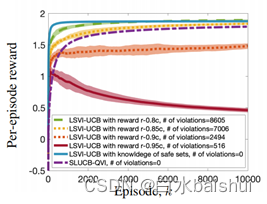
图 1. SLUCB-QVI 与不安全的最先进技术的比较验证:1) 当 LSVI-UCB (Jin et al., 2020) 知道 γ h ∗ \gamma _{h}^{*} γh∗ ,它按预期优于 SLUCB-QVI(不知道 γ h ∗ \gamma _{h}^{*} γh∗); 2)当 LSVI-UCB 不知道 γ h ∗ \gamma _{h}^{*} γh∗(如 SLUCB-QVI 的情况)并且其目标是最大化 r − λ ′ c r-{\lambda }'c r−λ′c 而不是 r ,较大的 λ ′ {\lambda }' λ′ 导致每回合奖励和约束违规次数较小,而 SLUCB-QVI 的约束违规次数为零。
然后以至少 1 − 3 δ 1-3\delta 1−3δ 的概率,它认为 R K ≤ 2 H T log ( d T δ ) + 2 ( 1 + κ ) β 2 d H T log ( 1 + K d λ ) { {R}_{K}}\le 2H\sqrt{T\log \left( \frac{dT}{\delta } \right)} +2(1+\kappa )\beta\sqrt{2dHT\log \left( 1+\frac{K}{d\lambda } \right)} RK≤2HTlog(δdT)+2(1+κ)β2dHTlog(1+dλK),其中 κ : = max ( s , h ) ∈ S × [ H ] κ h ( s ) \kappa :={ {\max } _{(s,h)\in \mathcal{S}\times [H]}}{ {\kappa }_{h}}(s) κ:=max(s,h)∈S×[H]κh(s)。证明见附录 B.2。
5. 实验 Experiments
在本节中,我们提出数值模拟来补充和证实我们的理论发现。 我们评估 SLUCB-QVI 在合成环境中的性能,并在 OpenAI Gym 的 Frozen Lake 环境中实施 RSLUCB-QVI(Brockman 等人,2016 年)。
5.1. 合成环境中的SLUCB-QVI SLUCB-QVI on synthetic environments
图 1 中显示的结果描述了 20 次实现的平均值,为此我们选择了 δ = 0.01 , σ = 0.01 , λ = 1 , d = 5 , τ = 0.5 , H = 3 \delta =0.01,\sigma =0.01,\lambda =1,d=5,\tau =0.5,H=3 δ=0.01,σ=0.01,λ=1,d=5,τ=0.5,H=3 和 $K= 10000 美元。 参数 { θ h ∗ } h ∈ [ H ] { {\left\{ \theta _{h}^{*} \right\}}_{h\in [H]}} { θh∗}h∈[H] 和 { γ h ∗ } h ∈ [ H ] { {\left\{ \gamma _{h}^ {*} \right\}}_{h\in [H]}} { γh∗}h∈[H] 来自 N ( 0 , I d ) \mathcal{N}\left( 0,{ {I}_{d}} \right) N(0,Id)。 为了调优参数 { μ h ∗ ( . ) } h ∈ [ H ] { {\left\{ \mu _{h}^{*}(.) \right\}}_{h\in [H]}} { μh∗(.)}h∈[H] 和特征图 ϕ \phi ϕ 这样 它们与假设 1 兼容,我们认为特征空间 { ϕ ( s , a ) : ( s , a ) ∈ S × A } \{\phi (s,a):(s,a)\in \mathcal{S}\times \mathcal{A}\} { ϕ(s,a):(s,a)∈S×A} 是一个子集 d 维单纯形和 e i ⊤ μ h ∗ ( . ) \mathbf{e}_{i}^{\top }\mu _{h}^{*}(.) ei⊤μh∗(.) 是对 S \mathcal{S} S 的任意概率测度 所有 i ∈ [ d ] i\in [d] i∈[d]。 这保证了假设 1 成立。
在 SLUCB-QVI 的第一个循环(第 6 行)中计算安全集 A h k ( s ) \mathcal{A}_{h}^{k}(s) Ahk(s),然后选择最大化线性函数的动作(在特征映射 $ \phi $) 在特征空间 D h k ( s h k ) : = { ϕ ( s h k , a ) : a ∈ A h k ( s h k ) } \mathcal{D}_{h}^{k}\left( s_{h}^{k} \right):=\left\{ \phi \left( s_{h }^{k},a \right):a\in \mathcal{A}_{h}^{k}\left( s_{h}^{k} \right) \right\} Dhk(shk):={ ϕ(shk,a):a∈Ahk(shk)} 在第二个循环中 (第 10 行)。 不幸的是,即使特征空间 { ϕ ( s , a ) : ( s , a ) ∈ S × A } \{\phi (s,a):(s,a)\in \mathcal{S}\times \mathcal{A}\} { ϕ(s,a):(s,a)∈S×A} 是凸的,集合 D h k ( s h k ) \mathcal{D }_{h}^{k}\left( s_{h}^{k} \right) Dhk(shk) 可以具有难以最大化线性函数的形式。 在我们的实验中,我们定义映射 $\phi $ 使得集合 D ( s ) \mathcal{D}(s) D(s) 在 ϕ ( s , a 0 ( s ) ) \phi \left( s,{ {a}_{0}}(s ) \right) ϕ(s,a0(s)) 与 N = 100 N=100 N=100 (见定义 1),因此,我们可以证明 SLUCB-QVI 的第 10 行中的优化问题可以有效地解决(见附录 C 的证明)。
定义1 (有限星凸集) Definition 1 (Finite star convex set)
一个围绕 x 0 ∈ R d { {x}_{0}}\in { {\mathbb{R}}^{d}} x0∈Rd 的星形凸集 D \mathcal{D} D 是有限的,如果存在有限多个向量 { x i } i = 1 N \left \{ { {\mathbf{x}}_{i}} \right\}_{i=1}^{N} { xi}i=1N 使得 D = ⋃ i = 1 N [ x 0 , x i ] \mathcal{D}=\bigcup _{i=1}^{N }\left[ { {\mathbf{x}}_{0}},{ {\mathbf{x}}_{i}} \right] D=⋃i=1N[x0,xi],其中 [ x 0 , x i ] \left[ { {\mathbf{x}}_ {0}},{ {\mathbf{x}}_{i}} \right] [x0,xi] 是连接 x 0 { {\mathbf{x}}_{0}} x0 和 x 的 线 i { {\mathbf{x} 的线 }_{i}} x的线i。
图 1 描绘了 SLUCB-QVI 的平均每回合奖励,并将其与基线进行了比较,并强调了 SLUCB-QVI 在尊重所有时间步的安全约束方面的价值。具体来说,我们将 SLUCB-QVI 与 1) LSVI-UCB (Jin et al., 2020) 进行比较,因为它具有安全约束知识,即 γ h ∗ \gamma _{h}^{*} γh∗; 2) LSVI-UCB,当它不知道 γ h ∗ \gamma _{h}^{*} γh∗(如 SLUCB-QVI 的情况)并且其目标是最大化函数 r − λ ′ c r-{\lambda }' c r−λ′c,约束被推入目标函数,对于 λ ′ = 0.8 , 0.85 , 0.9 {\lambda }'=0.8,0.85,0.9 λ′=0.8,0.85,0.9 和 0.95 的不同值。因此,通过低奖励不鼓励采取代价高昂的行动。该图验证了具有 γ h ∗ \gamma _{h}^{*} γh∗ 知识的 LSVI-UCB 在不了解 γ h ∗ \gamma _{h}^{*} γh∗ 的情况下按预期优于 SLUCB-QVI。此外,当 LSVI-UCB 试图最大化 r − λ ′ c r-{\lambda }'c r−λ′c(不知道 γ h ∗ \gamma _{h} ^{*} γh∗) 而 SLUCB-QVI 的约束违反次数为零。
5.2. 冰冻湖环境下的RSLUCB-QVI RSLUCB-QVI on Frozen Lake environment
我们评估了 RSLUCB-QVI 在 Frozen Lake 环境中的性能。 智能体寻求在 10 × 10 2D 地图中达到目标(图 2a),同时避免危险。
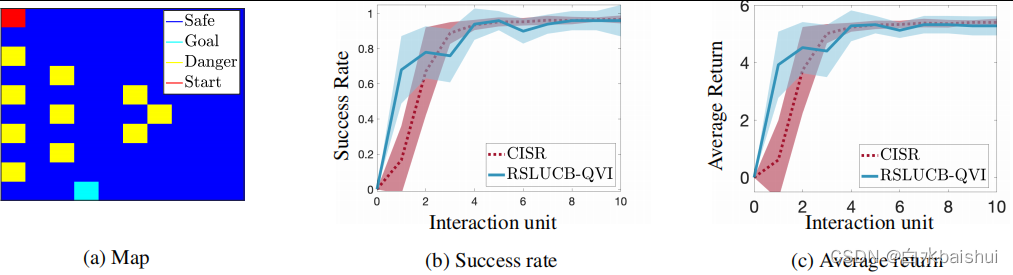
图 2.RSLUCB-QVI 和 CISR (Turchetta et al., 2020) 在 Frozen Lake 环境中的比较。
在每个时间步,智能体可以向四个方向移动,即 A = { a 1 : left, a 2 : right, a 3 : down, a 4 : up } \mathcal{A}=\{ { {a}_{1}}:\text{left, }{ {a}_{2}}:\text{right, }{ {a}_{3}}:\text{down, }{ {a}_{4}}:\text{up}\} A={ a1:left, a2:right, a3:down, a4:up}。它以 0.9 的概率沿所需方向移动,以 0.05 的概率沿任一正交方向移动。我们设 H = 1000 , K = 10 , d = ∣ S ∣ = 100 H=1000,K=10,d=|\mathcal{S}|=100 H=1000,K=10,d=∣S∣=100, AND μ ∗ ( s ) ∼ N ( 0 , I d ) { {\mu }^{*}}(s)\sim\mathcal{N}\left( 0,{ {I}_{d}} \right) μ∗(s)∼N(0,Id) for all s ∈ S = { s 1 , … , s 100 } s\in \mathcal{S}=\left\{ { {s}_{1}},\ldots ,{ {s}_{100}} \right\} s∈S={ s1,…,s100}。然后,我们通过求解一组线性方程来正确指定所有 ( s , a ) ∈ S × A (s,a)\in \mathcal{S}\times \mathcal{A} (s,a)∈S×A 的特征映射 ϕ ( s , a ) \phi (s,a) ϕ(s,a),使得转换尊重上述环境的细节。为了将避免危险的要求解释为形式 (11) 的约束,我们将 γ ∗ { {\gamma }^{*}} γ∗ 和 $\tau $ 调整如下:执行动作的成本 $a\in \状态 s ∈ S s\in \mathcal{S} s∈S 处的 mathcal{A}$ 是智能体移动到危险状态之一的概率。因此,安全策略确保移动到危险状态的概率的期望值是一个小值。为此,我们设置 γ ∗ = ∑ s ∈ Danger states μ ∗ ( s ) { {\gamma }^{*}}=\sum\limits_{s\in \text{ Danger states }}{ { {\mu }^{*}}}(s) γ∗=s∈ Danger states ∑μ∗(s) 和 τ = 0.1 \tau =0.1 τ=0.1。此外,对于每个状态 s ∈ S s\in \mathcal{S} s∈S,将一个安全动作,即导致具有小概率( τ = 0.1 \tau =0.1 τ=0.1)的危险状态之一的游戏给予智能体。我们求解一组线性方程来调整 θ ∗ { {\theta }^{*}} θ∗,使得在每个状态 s ∈ S s\in \mathcal{S} s∈S,通向最接近目标的状态的方向state 给 agent 奖励 1,而玩其他三个方向给它奖励 0.01。该模型说服智能体朝着目标前进。
在指定特征图 ϕ \phi ϕ 并调整所有参数后,我们为 10 个交互单元(episodes)(即 K = 10 K=10 K=10)实现了 RSLUCB-QVI,每个交互单元由 1000 个时间步(horizon)组成,即 $H= 1000 美元)。 在每个交互单元(情节)期间和每次移动之后,智能体可以最终处于以下三种状态之一:1)目标,导致交互单元成功终止; 2) 危险,导致交互单元出现故障并随之终止; 3)安全。 智能体达到目标会收到 6 的回报,否则会收到 0.01。
在图 2 中,我们报告了超过 20 个智能体的平均成功率和回报,我们为每个智能体实施了 10 次 RSLUCB-QVI,并将我们的结果与 (Turchetta et al., 2020) 提出的 CISR 的结果进行了比较,其中教师提供了帮助 智能体人通过干预来选择安全的行动。 虽然 RSLUCB-QVI 和 CISR 这两种方法的性能相当,但要考虑的重要一点是,CISR 中的每个交互单元(情节)由 10000 个时间步长组成,而在 RSLUCB-QVI 中这个数字是 1000 个。 值得注意的是,RSLUCB-QVI 的学习率比 CISR 快。 同样值得注意的是,我们在使用优化干预时将 RSLUCB-QVI 与 CISR 进行了比较,与其他类型的干预相比,它给出了最好的结果。
6. 结论 Conclusion
在本文中,我们开发了 SLUCB-QVI 和 RSLUCB-QVI,这两种安全 RL 算法在有限水平线性 MDP 的设置中。 对于这些算法,我们提供了次线性遗憾边界 O ~ ( κ d 3 H 3 T ) \widetilde{\mathcal{O}}\left( \kappa \sqrt{ { {d}^{3}}{ {H}^{3}}T} \right) O (κd3H3T),其中 H 是每集的持续时间,d 是特征映射的维度,κ 是表征安全约束的常数, T = K H T=KH T=KH 是动作戏的总数。 我们证明了它们很有可能永远不会违反未知的安全约束。 最后,我们分别在合成和 Frozen Lake 环境中实现了 SLUCB-QVI 和 RSLUCB-QVI,这证实了我们的算法具有与了解安全约束或利用现有技术的算法相当的性能 帮助代理人避免不安全行为的教师建议。