值函数近似
前几篇博客讲了如何进行值函数估计,估计完之后这些结果怎么保持呢,状态动作空间很小的就存在表中,用的时候查表获取v(s)和Q(s, a),但当状态空间是高维连续时,需要储存的东西就太多了,这个表就不行了,这时我们会采用函数近似(function approximation)的方式对值函数进行参数化近似:
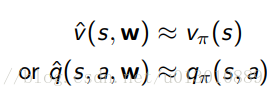
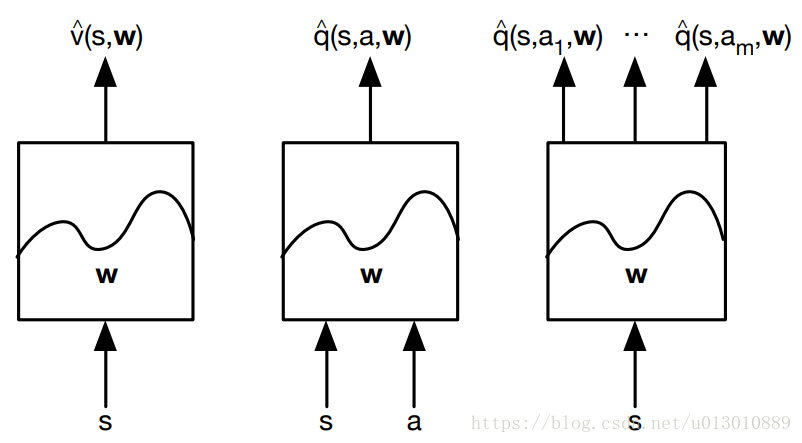
一般的函数近似有
- Linear combinations of features(可微,参数是特征的权重)
- Neural network(可微,参数是每层的连接权重)
- Decision tree(参数是叶子节点的取值,和树节点分裂的阈值)
- Nearest neighbour
- Fourier / wavelet bases
一般要求:参数个数要小于状态(或状态-行为)的个数
表格型强化学习和函数逼近方法的强化学习值函数更新时的异同点:
1. 表格型强化学习进行值函数更新时,只有当前状态
处的值函数在改变,其他地方的值函数不发生改变。
2. 值函数逼近方法进行值函数更新时,因此更新的是参数
,而估计的值函数为
,所以当参数
发生改变时,任意状态处的值函数都会发生改变。
参数化近似方法的参数学习
我们用特征向量来表示一个状态s,让它作为输入。 “查表”方法是一个特殊的线性价值函数近似方法:每一个状态看成一个特征,个体具体处在某一个状态时,该状态特征取1,其余取0。类似于one-hot向量一样。所以我们可以用线性组合来近似价值函数。


事实上,上面的公式都是无法直接在强化学习中使用的。因为在这里我们都是假设已经知道了真实值vπ(S)。然而在强化学习中,我们是不知道真实值的。也就是强化学习没有监督数据。
因此,我们的做法其实是用估计值代替真实值vπ(S): 注意MC是无偏的趋近于局部最优,而TD是有偏的趋近于全局最优

收敛性
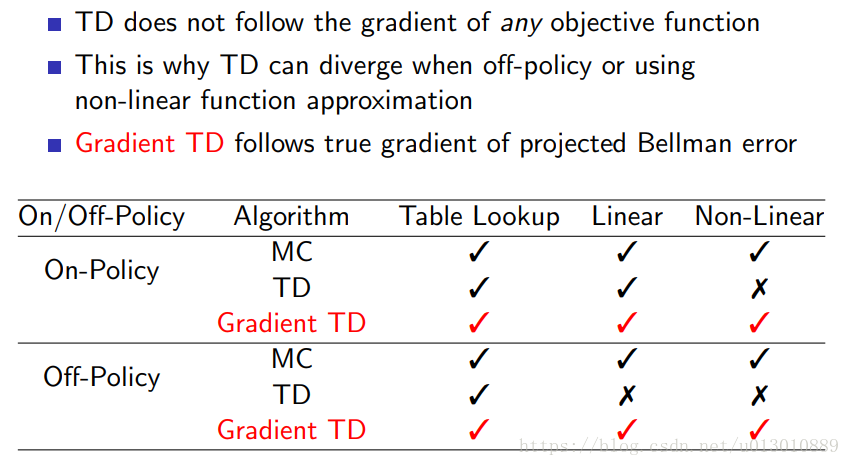
DQN

-强化学习(六):价值函数的逼近(近似)
- 深度增强学习David Silver(六)——Value Function Approximation
- 强化学习入门 第五讲 值函数逼近