前言
数据分析不只是对数值型数据的分析,对文本数据的分析也是十分常见的。大家常看到的新闻类APP,如:今日头条,UC头条等,通常都已按新闻类型分好类别,读者可根据自己的喜好查看相应的新闻内容。本案例从数据预处理,数据可视化,文本向量化以及建立模型实现了新闻分类全过程。
1概述
1.1案例背景
新闻分类是文本分类中常见的应用场量。在传统分类模式下,往往是通过人工对新闻内容进行核对,从而将新闻划分到合适的类别中。这种方式会消耗大量的人力资源,并且效率不高。
1.2任务与实现
我们的任务在于,根据新闻文本中的内容,进行文本预处理,建模等操作,从而可以自动将新闻划分到最可能的类别中,节省人力资源。 具体实现内容包括:
◆能够对文本数据进行预处理。【文本清洗, 分词,去除停用词,文本向量化等操作。】
◆能够通过Python统计词频,生成词云图。【描述性统计分析】
◆能够通过方差分析,进行特征选择。【验证性统计分析】
◆能够根据文本内容,对文本数据进行分类。【统计建模】
1.3任务扩展
新闻分类是文本分类的常见场景,本案例的实现也可以应用到其他根据文本内容来实现分类的场景,例如,垃圾邮件过滤,情感分析等。
1.4数据集描述
数据集为2016年1月1日~ 2018年10月9日期间新闻联播的数据,包括:
| 列名 | 说明 |
| date | 新闻日期 |
| tag | 新闻类别 |
| headline | 新闻标题 |
| content | 新闻内容 |
2.加载数据
2.1准备工作
使用anaconda3环境下的jupyter notebook,需要安装jieba,wordcloud库。
2.2加载数据并预览
3 数据预处理
3.1 文本数据
3 .1. 1 结构化数据与非结构化数据
结构化数据,是可以表示成多行多列的形式,并且,每行( 列) 都有着具体的含义。非结构化数据,无法合理地表示为多行多列的形式,即使那样表示,每行(列)也没有具体的含义。
3 .1 . 2 文本数据预处理
文本数据,是一种非结构化数据,与我们之前分析的结构化数据有所不同。因此,其预处理的步骤与方式也会与结构化数据有所差异。文本数据预处理主要包含:
◆缺失值处理
◆重复值处理
◆文本内容洁洗
◆分词
◆停用词处理
3.2 缺失值处理
content字段存在缺失值,根据实际情况选择用headline字段对应值填充并检查填充后结果。
3.3重复值处理

查找重复值并删除。
3.4文本内容清洗
文本中存在对分析作用不大的标点符号与特殊字符,使用re库中正则匹配方法去除:
3.5分词
分词是将连续的文本,分割成语意合理的若干词汇序列,中文分词需要用jieba库中的方法实现分词功能
这里使用jieba.cut()返回生成器,占用内存较少。随机选择5行数据预览。
3.6停用词处理
停用词,指的是在我们语句中大量出现,但却对语义分析没有帮助的词。对于这样的词汇,我们通常可以将其删除,这样的好处在于:
可以降低存储空间消耗、可以减少计算时间消耗。
对于哪些词属于停用词,已经有统计好的停用词列表,我们直接使用就好。
定义函数remove_stopword():遍历文本数据词汇,保留不存在于停用词表的词汇。
4数据可视化分析
4.1类别数量分布
统计新闻联播中每种类别的数量
4.2年份数量分布
按年、月、日统计新闻数量
4.3词汇统计
4.3.1统计在所有新闻中出现频数最多的N个词汇

4.3.2可视化
出现最多的15个词汇的频数、频率做条形图
4.3.3频数分布统计
绘制所有词汇频数分布直方图
4.4生成词云图
可以利用python中的wordcloud库生成词云图

5文本向量化
对文本数据进行建模,有两个问题需要解决:
◆模型进行的是数学运算, 因此需要数值类型的数据, 而文本不是数值类型数据。
◆模型需要结构化数据, 而文本是非结构化数据。
将文本转换为数值特征向量的过程,称为文本向量化。将文本向量化可以分为如下步骤:
◆对文本分词, 拆分成更容处理的单词。
◆将单词转换为数值类型, 即使用合适的数值来表示每个单词。
同样,需要注意的是,文本是非结构化数据,在向量化过程中,需要将其转换为结构化数据。
5 .1 词袋模型
词袋模型,直观上理解,就是一个装满单词的袋子。实际上,词袋模型是一种能够将文本向量化的方式。在词袋模型中,每个文档为一个样本,每个不重复的单词为一个特征,单词在文档中出现的次数作为特征值。例如,给定如下的文档集:
如果转换为词袋模型, 则结果为:
这样,我们就成功对文档实现了向量化的作,同时,运词袋模型,我们也将文本数据转换为结构化数据。
这里需要留意的是,默认情况下,CountVectorizer 只会对字符长度不小于2 的单词进行处理,如果单词长度小于2 ( 单词仅有一个字符) ,则会忽略该单词,例如,上例中的单词“ a ” ,并没有作为特征进行向量化。经过训练后,countvectorizer 就可以对未知文档( 训练集外的文档) 进行向量化。当然,向量化的特征仅为训练集中出现的单词特征,如果未知文档中的单词不在训练集中,则在词袋模型中无法体现。

从结果可知,像第2 个文档中,"pain’ 等词汇,在训练集中是没有出现的,而文本向量化是根据训练集中出现的单词作为特征,因此,这些词汇在转换的结果中无法体现。
5.2 TF-IDF
通过CountVectorizer 类,我们能够将文档向量化处理。在向量化过程中,我们使每个文档中单词的频数作为对应待征的取值。这是合理的,因为,单词出现的次数越多,我们就认为该单词理应比出现次数少的单词更加重要。然而,这是相对的,有些单词,我们不能仅以当前文档中的频数来进行衡量,还要考虑其在语料库中,在其他文档中出现的次数。因为有些单词,确实是非常常见的,其在语料库所有的文档中,可能都会频繁出现,对于这样的单词,我们就应该降低其重要性。例如,在新闻联播中,”中国“、”发展“等单词,在语料库中出现的频率非常高,即使这些词在某篇文档中频繁出现,也不能说明这些词对当前文档是非常重要的,因为这些词并不含有特别有意义的信息。
TF-IDF 可以用来调整单词在文档中的权重,其由两部分组成:
◆ TF (Term-Frequency) 词频, 指一个单词在文档中出现的次数。
◆ IDF (lnverse Document-Frequency)逆文档频率。
计算方式为:
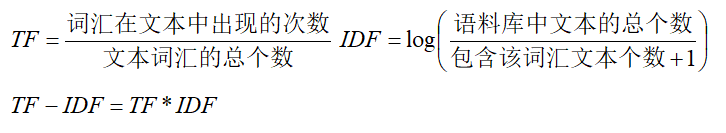
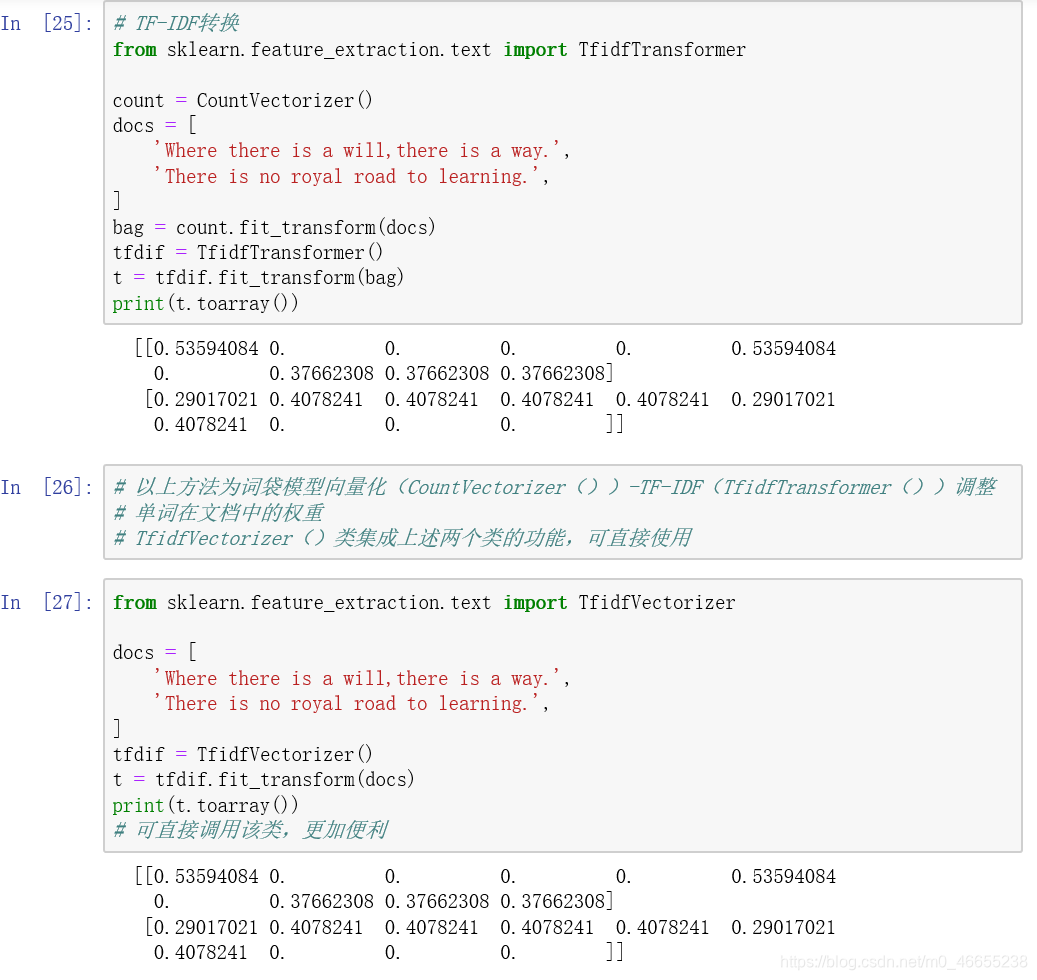
使用TfidfTransformer进行TF-IDF转化,此外,scikit-learn 同时提供了一个类TfidfVectorizer, 其可以直接将文档转换为TF-IDF值,也就是说,该类相当于集成了CountVectorizer 与TfidfTransformer两个类的功能,十分便利。
6建立模型
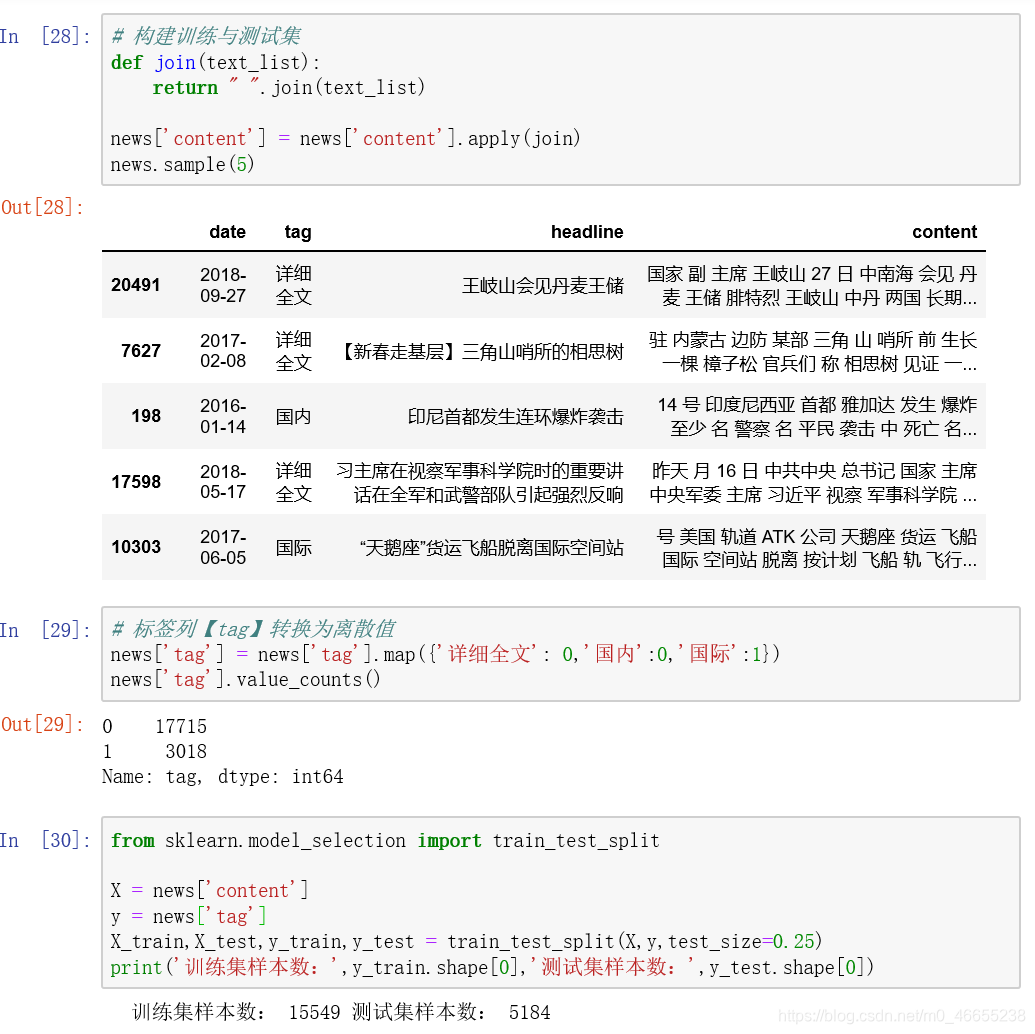
6.1 构建训练集与测试集
我们需要将每条新闻的词汇进行整理。目前,我们文本内容已经完成了分词处理,但词汇是以列表类型呈现的,为了方便后续的向量化操作( 文本向量化需要传递空格分开的字符串数组类型) ,我们将每条新闻的词汇组合在一起,成为字符串类型,使用空格分隔。将标签列(tag列)转换为离散值,之后对样本数据进行切分,构建训练集与测试集。
6.2特征选择
6.2.1特征维度-方差分析
大家需要注意,到目前为止,数据集X还是文本类型,我们需要对其进行向量化操作。这里,我们使用TfidfVectorizer类,在训练集上进行训练,然后分别对训练集与测试集实施转换。
使用词袋模型向量化后,会产生过多的特征,这些特征会对存储与计算造成巨大的压力,同时,并非所有的特征都对建模有帮助,基于以上原因,我们在将数据送入模型之前,先进行特征选择。这里,我们使用方差分析(ANOVA) 来进行特征选择,选择与目标分类变量最相关的20000 个特征。方差分析用来分析两个或多个样本( 来自不同总体) 的均值是否相等,进而可以用来检验分类变量与连续变量之间是否相关。

6.3分类模型评估
混淆矩阵:可以来评估模型分类的正确性。该矩阵是一个方阵, 矩阵的数值来表示分类器预测的结果, 包括真正例(True Positive ) 假正例(FaIsePositive) 真负例(True Negative )假负例(False Negative)
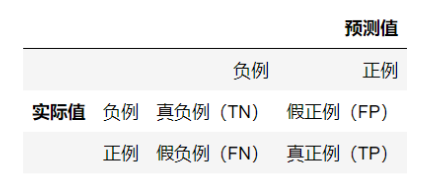
分类模型的评估标准一般最常见使用的是准确率,即预测结果正确的百分比。准确率是相对所有分类结果;精确率、召回率、F1-score是相对于某一个分类的预测评估标准。
准确率(Accuracy):预测结果正确的百分比 —— (TP+TN)/(TP+TN+FP+FN)
精确率(Precision):预测结果为正例样本中真实为正例的比例(查的准)—— TP/(TP+FP)
召回率(Recall):真实为正例的样本中预测结果为正例的比例(查的全)—— TP/(TP+FN)
综合指标(F1-score):综合评估准确率与召回率,反映了模型的稳健型 —— 2PrecisionRecall/(Precision+Recall)
可调用如下方法做出评估:
· sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
· y-true : 真实目标值
· y-pred : 估计器预测的目标值
· target-names : 目标类别名称
· return: 每个类别预测的精确率、召回率、F1-score
6.4逻辑回归
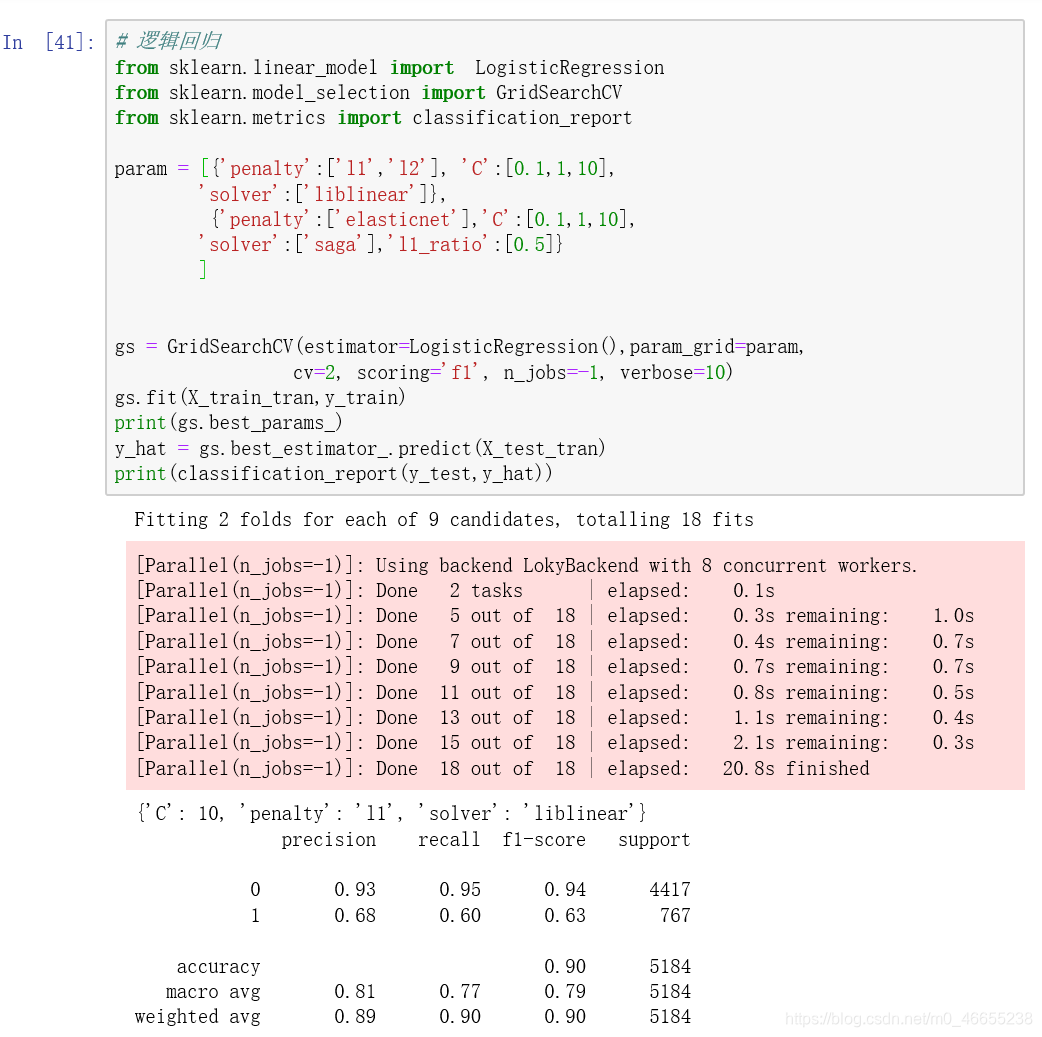
准确率(Accuracy): 0.90
精确率(Precision):0.68
召回率(Recall):0.60
综合指标(F1-score):0.63
6.5KNN
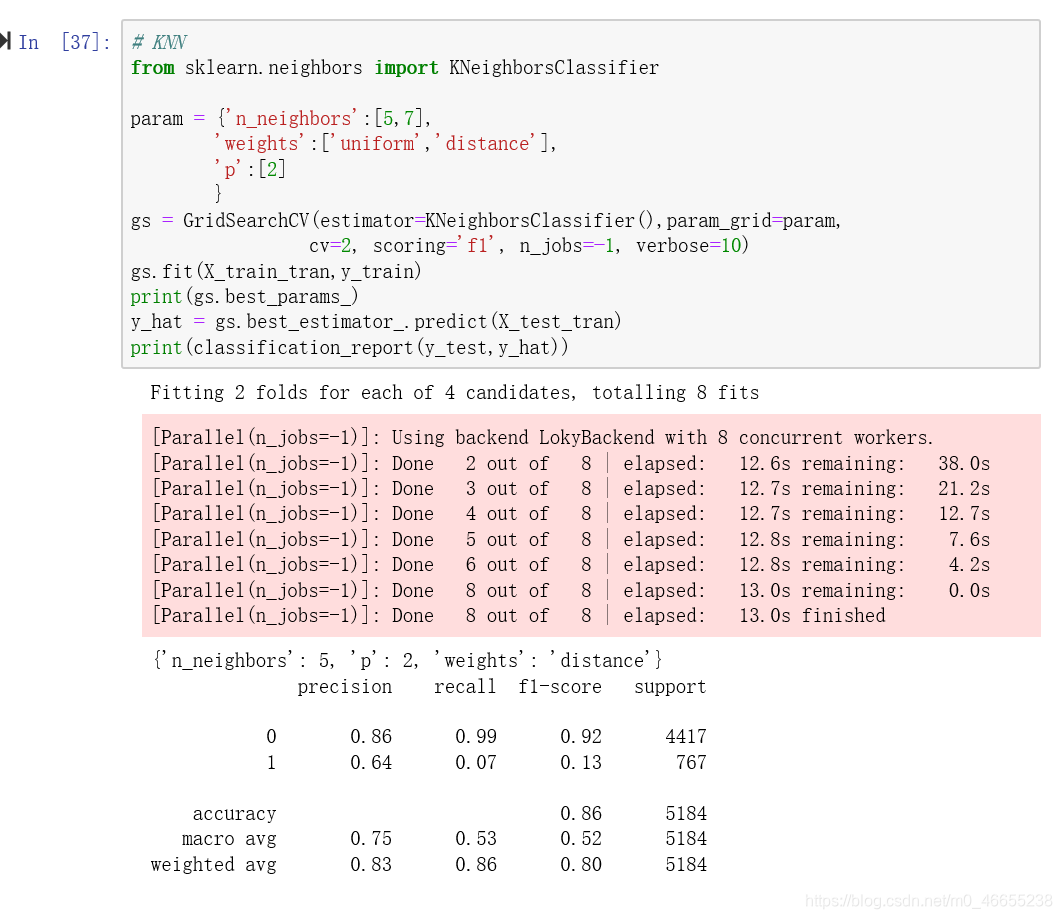
准确率(Accuracy): 0.86
精确率(Precision):0.64
召回率(Recall):0.07——过低,大量真实为类别1的未能准确预测为类别1
综合指标(F1-score):0.86
6.6决策树
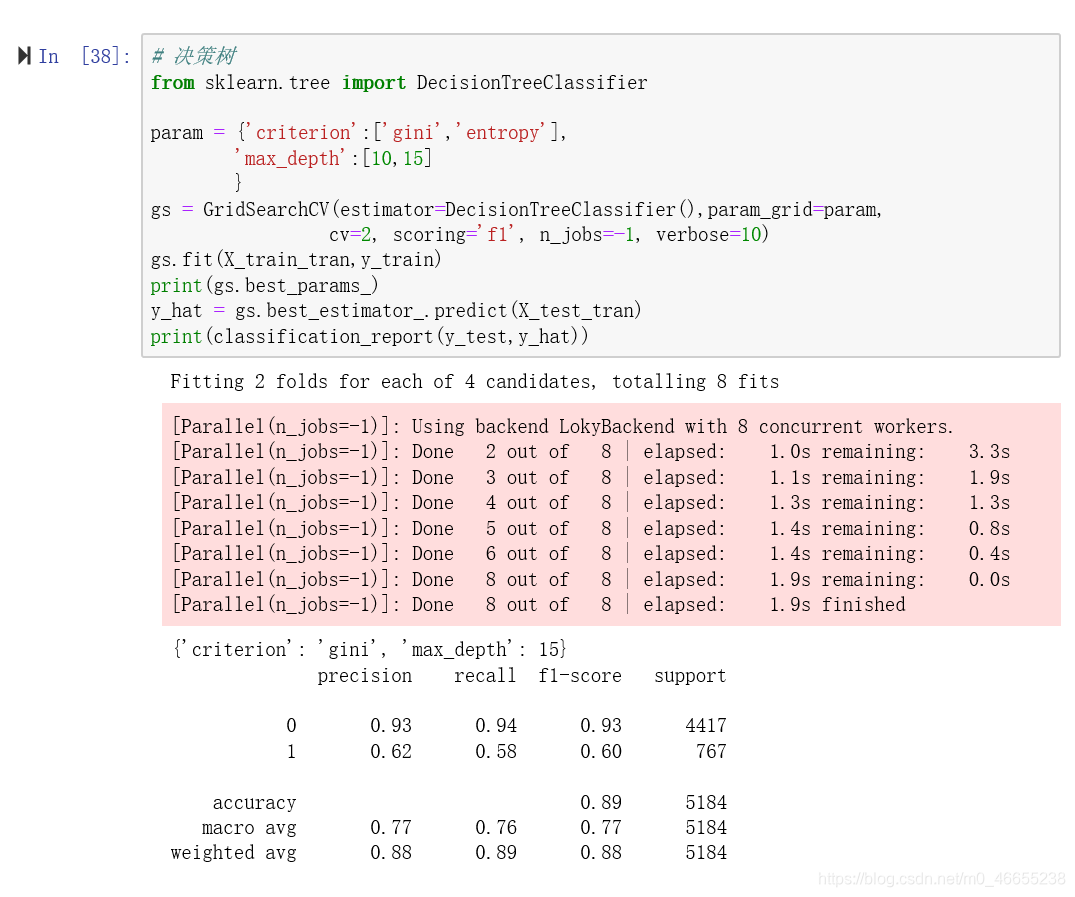
准确率(Accuracy): 0.89
精确率(Precision):0.62
召回率(Recall):0.58
综合指标(F1-score):0.89
6.7多层感知器
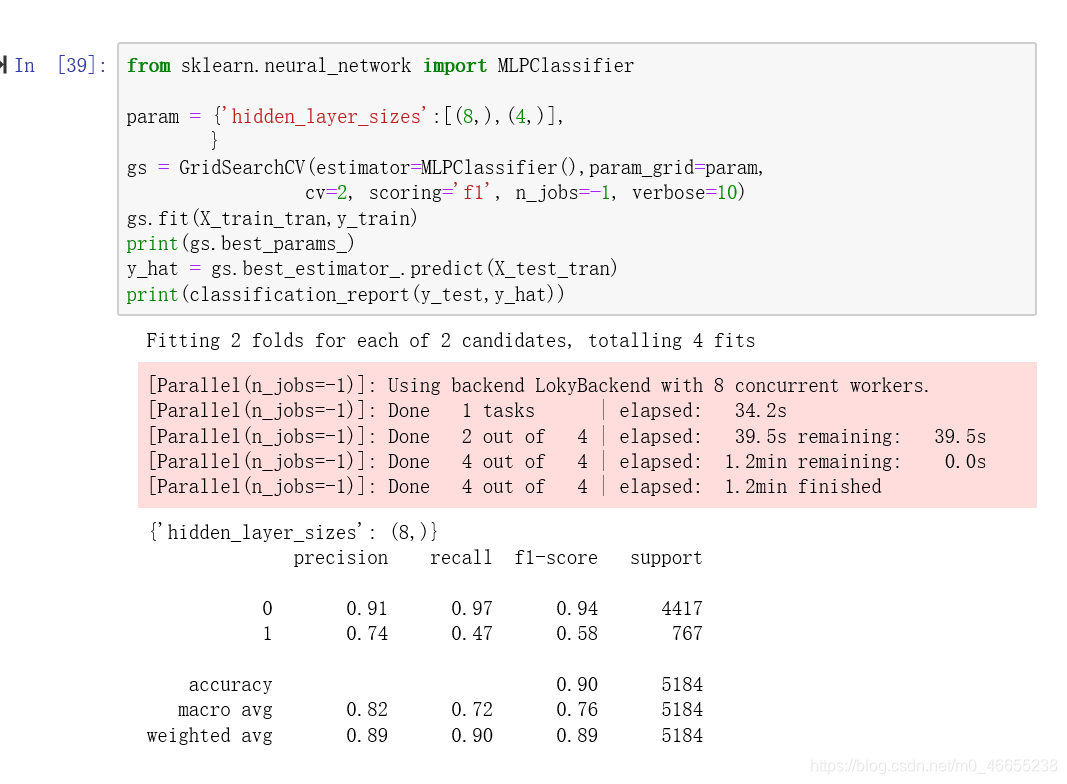
准确率(Accuracy): 0.90
精确率(Precision):0.74
召回率(Recall):0.47
综合指标(F1-score):0.90
6.8朴素贝叶斯

准确率(Accuracy): 0.91
精确率(Precision):0.65
召回率(Recall):0.82
综合指标(F1-score):0.91
各项指标来看,在本次案例中,朴素贝叶斯拟合效果较好。
