博主本人整理资料不易,如果文章对大家有用的话,恳请大家能够动动小手帮忙点个赞,如果能点个关注的话那就更好了…
文章目录
请说一说数据库索引
- 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
- 索引的一个主要目的就是加快检索表中数据的方法,亦能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构。
请说一说数据库事务
- 数据库事务(Database Transaction),是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功,要么全部失败的单元,可以简化错误恢复并是应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性。事务是数据库运行中的逻辑工作单位,由DBMS中的事务管理子系统负责事务的处理。
请说一说数据库事务隔离
- 同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡取钱,在A取钱的过程结束前,B不能向这张卡转账。
请说一说等值联接(inner join)和左联接(left join)
- 左联接返回包括左表中的所有记录和右表中联接字段相等的记录
- 右联接返回包括右表中的所有记录和左表中联结字段相等的记录
- 等值联接只返回两个表中联接字段相等的行
请说一说数据库事务的一致性
事务是由一系列对系统中数据进行访问与更新的操作所组成的一个程序执行逻辑单元。事务是DBMS中最基础的单位,事务不可分割。
事务具有四个特性,分别是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Duration),简称ACID。
- (1)原子性
原子性是指事务所包含的所有操作要么全部成功,要么全部失败的回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。 - (2)一致性
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转账几次,事务结束后两个用户的钱加起来应该还得是5000,这就是事务的一致性。 - (3)隔离性
隔离性是当多个用户并发访问数据库时,比如操作同一张表,数据库为每个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。这指的是在开发环境中,当不同事务操作相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。
不同的隔离级别:- Read Uncommitted(读取未提交):最低的隔离级别,什么都不需要做,一个事务可以读到另一个事务提交的结果。所有的并发事务问题都会发生。
- Read Committed(读取提交内容):只有在事务提交后,其更新结果才会被其他事务看见。可以解决脏读问题。
- Repeated Read(可重复读):在一个事务中,对于同一份数据的读取结果总是相同的,无论是否有其他事务对这份数据进行操作,以及这个事务是否提交。可以解决脏读、不可重复读。
- Serialization(可串行化):事务串行化执行,隔离级别最高,牺牲了系统的并发性。可以解决并发事务的所有问题。
- (4)持久性
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户操作完成,当我们程序执行完成直到看到提示后,就可以认定事务已经正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
请说说索引是什么,多加索引一定会好吗
- 索引:
数据库索引是为了增加查询速度而对表字段附加的一种标识,是对数据库表中一列或多列的值进行排序的一种结构。
数据库在执行一条sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件的就加入搜索结果集合。如果我们对某一字段增加索引,查询时就会先去索引列表中一次定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。 - 优点:
(1)通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
(2)可以大大加快数据库的检索速度,这也是创建索引的最主要的原因。
(3)可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
(4)在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
(5)通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。 - 缺点:
(1)创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
(2)索引需要占物理空间,除了数据表中占数据空间之外,每一个索引还要占一定的物理空间,如果建立聚镞索引,那么需要的空间就会更大。
(3)当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。 - 添加索引的规则
(1)在查询中很少使用的列或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维和速度和增大了空间需求。
(2)只有很少数据值的列也不应该增加索引。这是因为,由于这些列的很少,例如人事表的性别列,在查询的结果中,结果集的数据占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
(3)定义为text、image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
(4)当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
请说一说数据库的三大范式
- 第一范式:当关系模式R的所有属性都不能再分解为更基本的数据单位时,称R是满足第一范式,即属性不可分。
- 第二范式:如果关系模式R满足第一范式,并且R的所有非主键属性完全依赖于R的每一个候选关键属性,称R满足第二范式。
- 第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,即非主属性不传递依赖于键码(简而言之,第三范式就是属性不依赖于其它非主属性)。
请说一说mysql的四种隔离状态
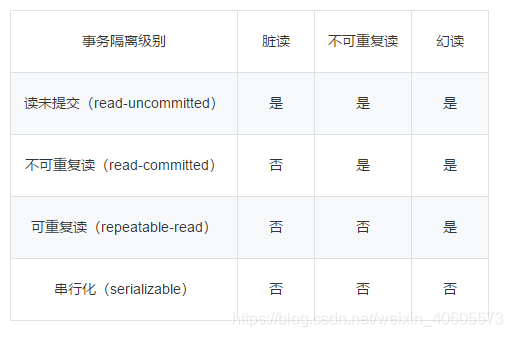
请你介绍一下mysql的MVCC机制
- MVCC是一种多版本并发控制机制,是Mysql的InnoDB存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。MVCC是通过保存数据在某个时间点的快照来实现该机制,其在每行记录后面保存两个隐藏的列,分别保存这个行的创建版本号和删除版本号,然后InnoDB的MVCC使用到的快照存储在Undo日志中,该日志通过回滚指针把一个数据行所有快照连接起来。
请问SQL优化方法有哪些
- 通过建立索引对查询进行优化
- 对查询进行优化,应尽量避免全表扫描
ER图
- 实体联系图(Entity-Relationship,E-R),有三个组成部分:实体、属性、联系。用来进行关系型数据库系统的概念设计。
- 实体:用矩形表示,矩形框内写明实体名。
- 属性:用椭圆形表示,并用无向边将其与相应的实体连接起来。
- 联系:用菱形表示,菱形框内写明联系名。
- ER模型转换为关系模式的原则:
- 一对一:遇到一对一关系的话,在两个实体任选一个添加另一个实体的主键即可。
- 一对多:遇到一对多关系的话,在多端添加另一端的主键。
- 多对多:遇到多对多关系的话,我们需要将联系转换为实体,然后在该实体上加上另外两个实体的主键,作为联系实体的主键,然后再加上联系自身带的属性即可。
