学习一项技术,首先要明确技术要解决什么问题,以及产生什么价值。
爬虫是python老生常谈的一个方向。通过脚本自动获取互联网信息数据。然后让信息数据产生价值。
无论是我们用的谷歌,百度这类搜索引擎,还是天眼查,返利网这类网站,或者那些让人头疼的抢票,秒杀脚本都是爬虫技术的体现。
爬虫的本质就是要模拟人的操作,发起请求,获取正确的服务器返回的数据。所以网络这一块需要相对熟悉,尤其是http协议。在此基础上就可以正式开始脱发之旅。
迈出吃牢饭的第一步:cc攻击
由于爬虫的核心是发送模拟请求,其实就是基于TCP的一条http格式的字符串。
但这个复杂的字符串不需要我们自己拼接,我们可以借助一些轮子进行实现。一个是python内置的urllib,当然也可以使用更高级的、经过封装之后的轮子requests。也可以抛弃urllib,直接只学习requests也行。
Requests Python编写,基于urllib,自称HTTP for Humans(让HTTP服务人类)
特性:
支持HTTP连接保持和连接池,
支持使用cookie保持会话,
支持自动确定响应内容的编码,
支持国际化的URL和POST数据自动编码。
使用更简洁方便,比urllib更加pythoner
开源地址:https://github.com/kennethreitz/requests
中文文档API:http://docs.python-requests.org/zh_CN/latest/index.html
关于requests需要学习的知识点:
- 发送请求
- 添加参数
- 设置请求头
- 设置代理ip(或者使用第三方服务)
- 网络异常处理
- Json数据如何处理
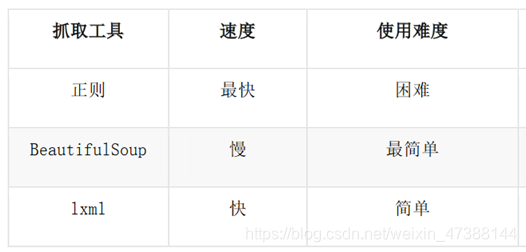
没有技术含量的体力活——xpath,css,re
如果模拟请求成功,获得了需要的数据,接下来就开始进行数据提取,这一块没什么难度,纯体力活。
返回的数据一般分为三种格式,json,html,js。
- json的话,有很多解析库,直接转为字典处理就行。
- html的话,xpath,css,re都可以。
- js的话,那就re,但有时候,返回的js经过re的处理,可以转为html或者json。
(1)xpath的话,使用lxml。
文档中英:https://lxml.de/tutorial.html
https://www.cnblogs.com/my_captain/p/7490292.html
lxml 是一种解析xml/html的类库,可以通过一些表达式,自由取出节点的属性以及内部值。
xpath 是一门在 xml/html文档中查找信息的表达式。是通过沿着路径 (path) 或者步 (steps) 来选取需要的信息。
关于xpath需要学习的知识点:
- 如何初始化,构造dom
- 如何定位节点,获取属性和文本
(2)css选择器的话,使用beautifulsoup。
官方文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
Beautiful Soup 是一个HTML/XML的解析器,主要用于解析和提取HTML/XML 数据。
它基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup用来解析HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持lxml 的XML解析器。
css选择器使用css对HTML页面中的元素实现特定的提取。
关于css需要学习的知识点:
- 如何初始化,构造dom
- 如何定位节点,获取属性和文本
(3)re的话,是python内置的直接import re就行。
re也称为正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
关于re需要学习的知识点:
- 一般匹配字符,预定义匹配字符,数量匹配字符,边界匹配字符
- match,search,findall,sub,split五个函数
- 正则表达式修饰符
- 贪婪模式与非贪婪模式(.*? / .?)
抢别人的饭碗——Selenium自动化测试工具
Selenium 中文文档:https://python-selenium-zh.readthedocs.io/zh_CN/latest/
Selenium是一个Web的自动化测试工具,类型像我们玩游戏用的按键精灵,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
但是被用歪了,现在一般作为破解反爬的一种手段,一般用于解决动态页面或者js加密的爬虫问题。
不然的话用Python 解决这个问题就只能:
1.直接从JavaScript 代码里采集内容(费时费力)
2.用Python 的第三方库运行JavaScript,直接采集你在浏览器里看到的页面。
3.破解js,终极脱发奥义——js逆向。
关于selenium需要学习的知识点:
- 配置环境
- 定位元素,获取属性与文本
- 动作链:点击,移动,拖拽,按键
- 下拉框,弹窗,iframe,标签操作
- 显示等待与隐式等待
- 提高效率,设置UA与代理
Web也就那样了——APP爬虫
越来越多的公司为了能耗尽你的时间,都转向移动端,web端只留给你一个app二维码。
常见的抓包工具:Fiddler,Wireshark,Charies。
主要目的就是为了获取app的请求,进行分析。毕竟app没有像浏览器一样,有自带的网络分析调试工具。
app也可以使用一些自动化测试工具,利用ui代理,来变相解决反爬实现一些数据获取工作。常见的有两种一个是appnium,另一个是airtest。
这里聊一聊airtest。
想开发网页爬虫,发现被反爬了?想对 App 抓包,发现数据被加密了?不要担心,使用 Airtest 开发 App 爬虫,只要人眼能看到,你就能抓到,最快只需要2分钟,兼容 Unity3D、Cocos2dx-*、Android 原生 App、iOS App、Windows Mobile……。
Airtest是网易出品的一款基于图像识别和poco控件识别的一款UI自动化测试工具。Airtest的框架是网易团队自己开发的一个图像识别框架,这个框架的祖宗就是一种新颖的图形脚本语言Sikuli。Sikuli这个框架的原理是这样的,计算机用户不需要一行行的去写代码,而是用屏幕截屏的方式,用截出来的图形摆列组合成神器的程序,这是Airtest的一部分。
另外,Airtest也基于poco这个UI控件搜索框架,这个框架也是网易自家的跨平台U测试框架,原理类似于appium,通过控件的名称,id之类的来定位目标控件,然后调用函数方法,例如click(),swip()之类的方法来对目标控件进行点击或者是操作。
爬虫开发本着天下工具为我所用,能让我获取数据的工具都能用来开发爬虫这一信念,决定使用Airtest来开发手机App爬虫。
官方文档 : http://airtest.netease.com/docs/docs_AirtestIDE-zh_CN/
这类工具只要学会如何配置环境,以及如何操作操作即可,app版的selenium。
后边还有进阶篇,喜欢的小伙伴可以三连一下~~