# 决策树算法
1 决策树算法的引入
决策树算法:非参数(不限制接收数据的结构和类型)的监督模型,可决策分类与回归的问题.
1.1树的概念
树分为根节点,分支节点,叶子节点.
根节点:存储着所有样本数据
分支节点:决策树算法会利用当前节点中的样本来决策选择哪个特征做分支
叶子节点:最后不再分支的节点
分支节点与叶子节点都有其所属的类别标签,当类别标签是离散的(分类问题),节点的label标签为当前节点中样本所属label最多的作为当前节点的label.当类别标签是连续的(回归问题),节点的label标签为当前节点中所有样本label的均值.
对样本特征的几种编码思路
LabelEncoder编码:对样本中特征的取值的编码(如对年龄特征的取值为青年,中年,老年,编码为0,1,2)
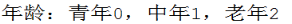
one-hot编码:也是对样本中的特征的取值编码
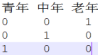
机器学习的处理问题流程:
1.数据角度—有标签数据(无监督,有监督)
2.业务角度—是否有预测—有预测—>监督学习—>根据预测值是否连续或离散—>分类或回归
—无预测—>非监督学习
1.2算法思路
利用树的结构,将数据集根据样本中的特征(属性)划分为树中的分支节点,并最终分到叶子节点
决策树算法的核心是要解决两个问题:
1.如何从数据集表中找到最佳节点和最佳分支
2.如何让决策树停止生长,防止过拟合
1.3构建决策树的三个步骤
1.特征选择:选取有较强分类能力的特征
通过信息熵增益/信息熵增益率/gini系数/分类错误率来判断特征的分类能力
2.决策树生成
典型算法:ID3,C4.5,他们生成决策树过程相似, ID3采用信息熵增益作为特征选择度量,C4.5采用信息熵增益比率,CART树采用gini系数
3.决策树剪枝
决策树产生了过拟合现象(模型对训练集效果很好,对位置数据效果很差)
注意:决策树构建直到没有特征可选或者信息增益很小时停止,这就导致了构建的决策树模型过于复杂.
发生过拟合是由于决策树太复杂,解决办法是控制模型的复杂度对于决策树来说就是简化模型:剪枝(又分为先剪枝与后剪枝)
2 特征分类的评价指标
2.1熵的概念
信息:信息就是对不确定性的消除(把信息理解为一种不确定性)
熵定义为信息(不确定性)的期望值
一个可以分类为n个label的数据集S,它的信息熵为随机得到的一个label包含的信息量(不确定性)的期望值.
不确定性公式:I(X)=-log( p )
信息熵公式:E(S)=
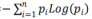
上述若对数的底数取值为2,就是我们平常所说的信息单位bit(比特)
pi为取得对应label的概率.
数据集的信息熵代表了这个数据集的混乱程度,信息熵越大,越混乱.
2.2信息熵的概念
若按照某种特定方式,例如按照某一属性的值对S进行划分,得到n个子集,新的子集们都有自己的信息熵(子集内部讨论),属性所有子集的(子集所占比例*子集的信息熵)的和与原S的熵的差值就是这个划分操作带来的信息熵增益.
总结:
变量的不确定性越大,熵也就越大.熵越小,信息的纯度越高.在构建我们的决策树的过程中,希望选择信息熵比较小的,因为信息熵小对应的信息纯度越高
基于信息熵和信息增益来建立决策树
如何根据熵建立一颗决策树?
选择熵比较小的特征或者属性作为分支节点
原因:因为熵小,信息纯度越高
2.3Gini系数
Gini系数是一种与信息熵类似的做特征选择的方式,可以用来表征数据集样本的不纯度.在CART(Classifier and Regression Tree)算法中利用Gini系数构造二叉分类回归树.
Gini系数的计算方式如下:
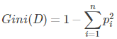
其中,D表示数据集全体样本,pi表示每种类别出现的概率,取个极端情况,如果数据集中所有的样本都为同一类,那么有p0=1,Gini(D)=0,显然此时数据的不纯度最低.
如果样本集合D根据某个特征A被分割为D1,D2两个部分,那么在特征A作为划分的条件下,集合D的Gini系数定义为:
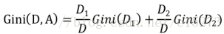
Gini(D,A)表示特征A不同分组的数据集D的不确定性,Gini指数越大,样本集合的不确定性也就越大,这一点与熵的概念比较类似.
Gini(D1)/Gini(D2)的解释:
特征A有两个取值,根据取值可以把数据集D分为两个子集D1,D2.在子集中讨论各自的Gini系数.
所以数据不纯度减小程度:
△Gini(A)=Gini(D)-Gini(D,A)
显然,在做特征选择的时候,我们选取△Gini(A)最大的那个
Gini系数相对于信息熵增益率的优势:
熵的计算用到了大量的对数运算,计算机中对数运算相对于基本运算需要的时间成本更多,这在模型较为复杂时会严重拖慢计算速度.所有采用Gini系数作为判断标准可以在保证准确率的同时加快计算速度.
3 ID3算法
信息增益概念的含义与本质
含义:划分训练数据集前后信息发生的变化
本质:衡量给定属性对训练数据集的划分能力.
我们使用信息增益来作为决策树分支的划分依据,它也是决策树分支上整个数据集信息熵与当前节点(划分节点)信息熵的差值,通常用Gain(A)表示
Gain(A)=H(总) -H(A)
H(总)=

其中pi是类别标签i的概率,所以H(总)计算的是类别标签的不确定性的期望
H(A):以A为划分条件的所有子集信息熵之和.
信息增益:总体的信息熵-以某个特征作为划分标准的信息熵
假设在某个分支节点中:Gain(age)>Gian(income)>Gain(“sex”) --这里对所有特征的信息熵有一个排序的过程
那么在建立决策树选择特征age分支
ID3算法原理:
输入:数据集
输出:决策树
算法:
1.计算所有特征的信息增益,选择信息增益最大的特征作为划分节点
2.把划分节点从当前特征集合中去除
TA=T-{a}
3.在特征集合中重新选择信息增益最大的特征作为划分节点
4.直到所有的样本都划分为叶子节点
注意:计算信息增益的时候,将所有特征或属性的信息增益计算出来了,只需要排序和选择就可以了
4 C4.5
和ID3算法类似,只是在以下几个点做了改进
1.用信息增益率选择属性,避免了ID3偏向于选择取值多的属性 这一不足点
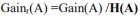
2.在树构造过程中进行了剪枝
3.能够完成连续属性的离散化处理
4.能够对不完整数据进行处理
4.1决策树对连续属性的处理

具体的划分规则:采用的是一种遍历的方式,找出所有已知连续值中最适合当前属性分裂的值作为二分类值.
CART树中也是用的这种方式处理连续属性
4.2决策树对离散属性的处理
决策树与CART分类回归树对于属性离散值的处理区别:与CART树都是二叉树不同,决策树是可以有多分叉的,所以对属性离散值不做处理.CART树对属性离散值的处理为双化策略,生成多颗CART树,选择效果最好的一颗.
5 CART分类回归树
5.1CART分类回归树简介
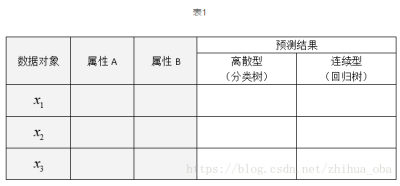
CART分类回归树是一种典型的二叉决策树,可以做分类或者回归.如果待预测结果是离散型数据,则CART生成分类决策树;如果待预测结果是连续性数据,则CART生成回归决策树.数据对象的属性特征为离散型或连续型,并不是区别分类树与回归树的标准.例如表1中,数据对象xi的属性A,B为离散型/连续型并不是区分分类树与回归树的标准.作为分类决策树时,待预测样本落至某一叶子节点,则输出该叶子节点中所有样本所属类别最多的那一类(即叶子节点中的样本可能不是属于同一类别,则多数为主);作为回归决策树时,待预测样本落至某一叶子节点,则输出该叶子节点中所有样本的均值.
5.2CART分类树—待预测结果为离散型数据
选择具有最大Gain_Gini的属性及其属性值,作为最优分裂属性以及最优分裂属性值.Gain_Gini值越大,说明二分之后的子样本集的”纯净度”越高,即说明选择该属性(值)作为分裂属性(值)的效果越好.
此处要选的有两个:最优分裂属性以及其对应的属性值
对于样本集S,GINI计算如下:
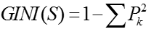
其中,样本集S中,Pk表示分类结果中第k个类别出现的频率
对于含有N个样本的样本集S,根据属性A的第i个属性值,将数据集S划分为两部分,则划分成两部分之后,Gain_Gini计算如下:
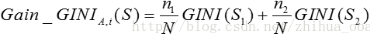
其中,n1,n2分别为样本S1,S2的样本个数
对于属性A,分别计算任意属性值将数据集划分成两部分(是二叉树,这也是为什么CART树对离散属性(非数值型 )采取双化的原因,而对于连续属性,采用遍历所有已知连续值找到最好的划分值)之后的Gain_Gini,选取其中的最小值,作为属性A得到的最优二分方案:
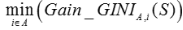
所以分类决策树对于选取最优分裂属性值的方式是遍历.(后面的回归决策树也是采用的这种方式)
对于样本集S,计算所有属性的最优二分方案,选取其中的最小值,作为样本集S的最优二分方案.
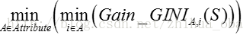
所得到的属性A及其第i属性值,即为样本集S的最优分裂属性以及最优分裂属性值
5.3CART回归树–待预测结果为连续型数据
区别于分类树,回归树的预测结果为连续型数据.同时,区别于分类树选取Gain_Gini为评价分裂属性的指标,回归树选取Gain_σ为评价分裂属性的指标.选择具有最小Gain_σ的属性及其属性值,作为最优分裂属性以及最优分裂属性值.Gain_σ值越小,说明二分之后的子样本集的”差异性”越小,说明选择该属性(值)作为分裂属性(值)的效果越好.
针对含有连续型预测结果的样本集S(理解成一个子节点),总方差计算如下:
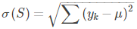
其中,μ表示样本集S(理解成一个子节点)中预测结果(预测结果就是当前子节点中所有样本实际值的均值),yk表示第k个样本预测结果
对于含有N个样本的样本集S,根据属性A的第i个属性值,将数据集S划分为两部分,则划分成两部分之后,Gain_σ计算如下:
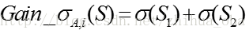
对于属性A,分别计算任意属性值将数据集划分成两部分之后Gain_σ,选取其中的最小值,作为属性A得到的最优二分方案:

对于数据集S,计算所有属性的最优二分方案,选取其中的最小值,作为样本集S的最优二分方案:
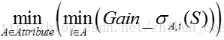
所得到的属性A及其第i属性值,即为样本集S的最优分裂属性以及最优分裂属性值.感觉CART分类树与回归树的区别就在分裂的评价指标,一个是Gain_Gini/Gain_σ
5.4CART回归树示例
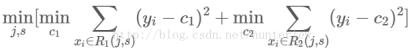
图1,图2其实描述是都是属性j的Gain_σ.区别在于图2计算的是将数据集S用最优分裂属性值s划分为R1(j,s),R2(j,s)两个子样本集之后计算的Gain_σ.所以图2是Gain_σ更为详细的定义.c1,c2分别为R1,R2子样本集中所有label的均值.
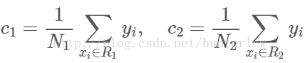
N1,N2为子样本集中样本的个数
具体示例:
训练数据如下表,属性x的取值范围[0.5,10.5],y的取值范围[5.0,10.0]学习这个回归问题的最小二叉回归树

求解训练数据的切分点s
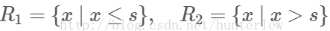
容易求得在R1,R2内部使得平方损失误差达到最小值的c1,c2为:

求训练数据的切分点,根据所给数据,考虑如下切分点:
1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5
对各切分点,不难求出相应的R1,R2,c1,c2及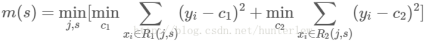
例如:当s=1.5时,R1={1},R2={2,3…10},c1=5.56,c2=7.50
现将s及m(s)的计算结果列表如下:
由上表知,当x=6.5的时候达到最小值,此时R1={1,2…6},R2={7,8,9,10},c1=6.24,c2=8.91,所以回归树T1(x)为:
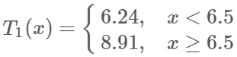
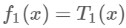
所以用的是均值作为预测结果
5.5 CART树与GBDT的区别
CART:树的根节点分成2支后,在分别在这2支上做分支,以此递推,最终生成一颗完整的决策树;后续再剪枝等;
GBDT:获得一颗二叉树后,利用残差,再在完整的数据集上生成一颗二叉树,最终将多颗二叉树加权累加组成一个最终的函数
下面将用上述数据集详解GBDT的过程:
用f1(x)拟合训练数据的残差见下表,表中r2i=yi-f1(xi),i=1,2…10 ,r2=∑r2i,表示为第二颗决策树要拟合的残差.
第二步求T2(x)方法与T1(x)一样,只是拟合的数据是上表的残差,可以得到:
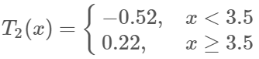
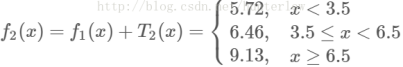
继续求得:
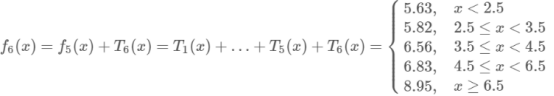
可以用拟合训练数据的平方损失等来作为结束条件.此时
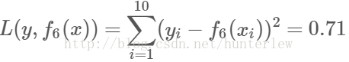
假设此时已经满足误差要求,那么f(x)=f6(x)即为所求回归树
6 sklearn库的应用
此处代码都是用的jupyter lab
这玩意代码上传属实麻烦.留意一下别人代码是怎么排版的