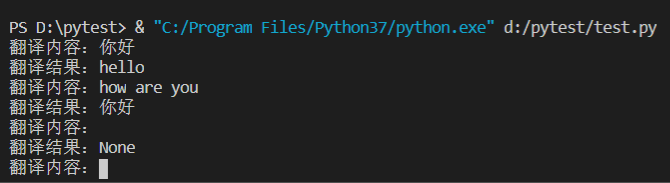
翻译效果图:
源代码:
import urllib.request #导入模块
import urllib.parse
import json
def translate(text):
# 参数检验
if not text: #无内容输入
return 'None'
# 请求网址
url = "https://fanyi.youdao.com/translate"
# 表单数据
params = {
'i':text,
'doctype':'json', #数据类型,指定为 JSON
'from':'AUTO',
'to':'AUTO'
}
data = urllib.parse.urlencode(params).encode('utf-8')
# 请求头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,data=data,headers=headers)
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 解析数据
content = json.loads(response.read().decode('utf-8'))
if content['errorCode'] == 0: # 一切正常
result_tup = (item['tgt'] for item in content['translateResult'][0])
result = ''.join(result_tup)
else: # 发生错误
result = 'Error'
# 返回结果
return result
if __name__ == "__main__":
while True :
text = input('翻译内容:')
result = translate(text)
print("翻译结果:%s" % result)
讲解:
一、urllib 的 request 模块 和 parse 模块
1、 request 模块(请求处理模块)
① urlopen 方法(发送请求,获得响应)
urllib.request.urlopen(req)
req 参数在下一个方法会讲到的
函数整体的返回值
response = urllib.request.urlopen(req)
② Request 方法(构造请求对象)
urllib.request.Request((url=url,data=data,headers=headers)
url 参数(str):请求网址
url = https://fanyi.youdao.com/translate
data 参数(bytes):表单数据,默认为 None(后面会讲到)
data = urllib.parse.urlencode(params).encode('utf-8')
headers 参数(dict):请求头部(一定要用大括号)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
在 Network 中第一个文件的 Headers 的最下面显示

函数整体的返回值
req = urllib.request.Request((url=url,data=data,headers=headers)
2、 parse 模块(URL 处理模块)
就如上面的 data 参数用到的就是此模块的 urlencode 方法
data = urllib.parse.urlencode(params).encode('utf-8')
作用是将 dict 类型数据转化为 str 类型数据(并将 str 类型数据转化成 bytes 类型数据)
二、JSON 对象
先说明一下,JSON 是一种轻量级的数据格式(或者说像XML一样是一种标准)
代码开头导入了 josn 库,目的是为了用它的 loads 函数
json.loads(response.read().decode('utf-8'))
作用是将已编码的 JSON 字符串解码为 Python 对象
read():返回响应体(bytes 类型),通常需要使用 decode('utf-8') 将其转化为 str 类型
函数整体的返回值
content = json.loads(response.read().decode('utf-8'))
三、解析数据
if content['errorCode'] == 0: # 一切正常
result_tup = (item['tgt'] for item in content['translateResult'][0])
result = ''.join(result_tup)
else: # 发生错误
result = 'Error'
上面所述内容是基于有道翻译反爬虫机制而编写的
具体详解我也不是很清楚
四、关于 main 函数
if __name__ == '__main__' 的意思是:当 .py文件被 直接运行 时,if __name__ == '__main__'之下的代码块将被运行;当 .py文件以模块形式被 导入 时,if __name__ == '__main__'之下的代码块不被运行
但由于本源代码没有发挥出它的作用,所以写这个函数只是为了规范(好看 )
参考博客:
爬虫系列(三) urllib的基本使用
爬虫系列(四) 用urllib实现英语翻译
Python中if _ name _ == “_ main _” ,init 和self 的解析