最近刚开始学习爬虫,第一个项目肯定是劳模有道翻译。
首先肯定是爬取时遇到的errorCode=50 问题,这个很明显就是有道的反爬虫阻碍我们,按照网上删除translate_o的_o是一个解决方法,但是输出时候很明显缺少数据:

这是我通过抓包得到的数据,smartResult的dict类型显然丢失,这肯定也是电脑对面兄弟搞的鬼:

于是进行下列尝试,首先分析报头:

client一组不重要,看自己需求进行重构,个人觉得Accept-Encoding是可以删除,我们爬虫不需要进行这种编码,我们只要内容,就没必要自己给自己添麻烦了,User-Agent保留,其他不变。
然后是Cookies,我通过几次抓包对比,发现__rl_test_cookies是一直在改变的,其他不变,开始寻找,Cookies的构造函数,chrome神器启动,最后找到了它所在的js代码http://shared.ydstatic.com/js/rlog/v1.js这个是他的源码,用站长工具格式化,得到源码,如下:
function t() {
var a = (new Date).getTime(),
c = [];
return b.cookie = "___rl__test__cookies=" + a,
G = r("OUTFOX_SEARCH_USER_ID_NCOO"),
-1 == G && r("___rl__test__cookies") == a && (G = 2147483647 * Math.random(), q("OUTFOX_SEARCH_USER_ID_NCOO", G)),
F = r("P_INFO"),
F = -1 == F ? "NULL": F.substr(0, F.indexOf("|")),
c = ["_ncoo=" + G, "_nssn=" + F, "_nver=" + z, "_ntms=" + a],
L.autouid && c.push("_rl_nuid=" + __rl_nuid),
c.join("&")
}很显然了,a就是当前时间,那么就可以构造我们python里面的cookie了。
剩下也不需要改动,尝试运行之后,依然是errorcode=50,那可能发送data也有问题。
继续分析form data,下面是抓包重构之后的内容:
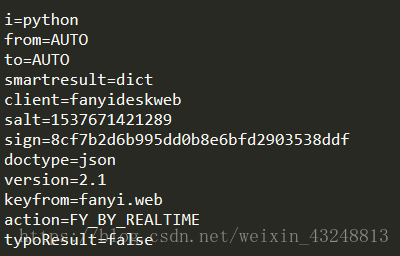
salt:加密用到的盐。
sign:签名字符串。
i:需要进行翻译的字符串。
这三个重要,进入有道翻译的源代码,http://shared.ydstatic.com/fanyi/newweb/v1.0.12/scripts/newweb/fanyi.min.js这里存在着构造salt和sign的函数:
function(e, t) {
var n = e("./jquery-1.7");
e("./utils");
e("./md5");
var r = function(e) {
var t = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10));
return {
salt: t,
sign: n.md5("fanyideskweb" + e + t + "6x(ZHw]mwzX#u0V7@yfwK")
}
};改变一下我们的爬虫:
import urllib.request
import urllib.parse
import json
import time
import random
import hashlib
def translate(content):
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
# 定义变量
client = 'fanyideskweb'
ctime = int(time.time() * 1000)
salt = str(ctime + random.randint(1, 10))
# 这是秘钥
key = '6x(ZHw]mwzX#u0V7@yfwK'
sign = hashlib.md5((client + content + salt + key).encode('utf-8')).hexdigest()
# 表单数据
data = {
"i": content,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": sign,
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false",
}
data = urllib.parse.urlencode(data).encode('utf-8')
# 请求头
head = {
"Host": "fanyi.youdao.com",
"Connection": "keep-alive",
# 这个不要添加到报头,否则一直是errorcode=50
# "Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "[email protected]; OUTFOX_SEARCH_USER_ID_NCOO=2142036110.3722978; hibext_instdsigdipv2=1; JSESSIONID=aaaeQfHw-JfDDaRb0deyw; ___rl__test__cookies="+str(ctime),
"Origin": "http://fanyi.youdao.com",
"X-Requested-With": "XMLHttpRequest",
"Referer": "http://fanyi.youdao.com/",
}
request = urllib.request.Request(url, data, headers=head)
response = urllib.request.urlopen(request)
response = response.read().decode("utf8")
# print(response)
target = json.loads(response)
result = target['translateResult'][0][0]['tgt']
for translate in target['smartResult']['entries']:
print(translate)
return result
if __name__ == '__main__':
content = input('请输入需要翻译的内容:')
print(translate(content))
到这里就完成了:


但是这个代码的速度有点慢,我之后会试着去改进一下。
感谢这位博主https://blog.csdn.net/shadkit/article/details/79174948给我的提醒
一开始删除_o 给出的消息不全是我爬虫自己的问题呢