●结构图解

RDD[Person]以Person为类型参数,但Spark框架本身不了解 Person类的内部结构。
DataFrame提供了详细的结构信息schema,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。这样看起来就像一张表了
DataSet[Person]中不光有schema信息,还有类型信息
●数据图解
1.假设RDD中的两行数据长这样:
RDD[Person]

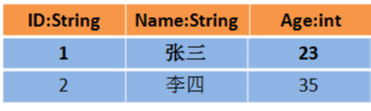
2.那么DataFrame中的数据长这样
DataFrame = DataSet[Row] = RDD[Person] - 泛型 + Schema + SQL操作 + 优化
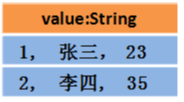
3.那么Dataset中的数据长这样(每行数据是个Object):
Dataset[Person] = DataFrame + 泛型

或者长这样:Dataset[Row]
总结
DataFrame = RDD - 泛型 + Schema + SQL + 优化
DataSet = DataFrame + 泛型
DataSet = RDD + Schema + SQL + 优化
DataFrame = DataSet[Row]