RDD(弹性分布式数据集)
RDD(Resilient Distributed Dataset)叫做分布式数据集,是 Spark 中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD 具有数据流模型的特点:
自动容错、位置感知性调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓
存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
可以从三个方面来理解:
1、数据集 DataSet:故名思议,RDD 是数据集合的抽象,是复杂物理介质上存在数据的一种逻辑视图。
从外部来看,RDD 的确可以被看待成经过封装,带扩展特性(如容错性)的数据集合。
2、分布式 Distributed:RDD 的数据可能在物理上存储在多个节点的磁盘或内存中,也就是所谓的多级存储。
3、弹性 Resilient:虽然 RDD 内部存储的数据是只读的,但是,我们可以去修改(例如通过 repartition 转换操作)并行计算计算单元的划分结构,也就是分区的数量。
你将 RDD 理解为一个大的集合,将所有数据都加载到内存中,方便进行多次重用。
第一,它是分布式的,可以分布在多台机器上,进行计算。
第二,它是弹性的,我认为它的弹性体
现在每个 RDD 都可以保存内存中,如果某个阶段的 RDD 丢失,不需要从头计算,只需要提取上一个 RDD,再做相应的计算就可以了
优点:
-编译时类型安全
编译时就能检查出类型错误
-面向对象的编程风格
直接通过类名点的方式来操作数据
缺点:
-序列化和反序列化的性能开销
无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化.
-GC的性能开销
频繁的创建和销毁对象, 势必会增加GC
DataFrame
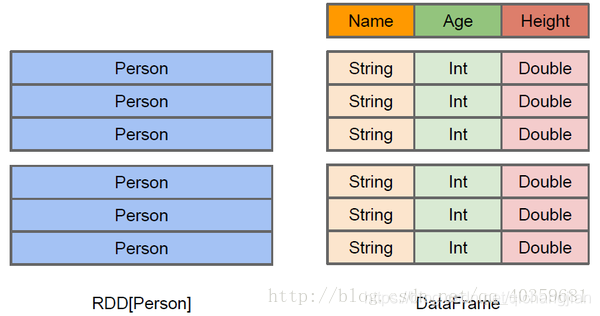
上图直观地体现了DataFrame和RDD的区别。
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解 Person类的内部结构。
而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。这样看起来就像一张表了,DataFrame还配套了新的操作数据的方法,DataFrame API(如df.select())和SQL(select id, name from xx_table where …)
DataFrame引入了schema和off-heap
schema : RDD每一行的数据, 结构都是一样的,这个结构就存储在schema中。 Spark通过schema就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了。
off-heap : 意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时,就直接操作off-heap内存。由于Spark理解schema,所以知道该如何操作。
off-heap就像地盘,schema就像地图,Spark有地图又有自己地盘了,就可以自己说了算了,不再受JVM的限制,也就不再收GC的困扰了。
通过schema和off-heap,DataFrame解决了RDD的缺点,但是却丢了RDD的优点。DataFrame不是类型安全的,API也不是面向对象风格的。
DataSet
DataSet是分布式的数据集合。DataSet是在Spark1.6中添加的新的接口。它集中了RDD的优点(强类型和可以用强大lambda函数)以及Spark SQL优化的执行引擎。DataSet可以通过JVM的对象进行构建,可以用函数式的转换(map/flatmap/filter)进行多种操作
DataSet(dataset中每行数据是个Object)包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集