- Spark SQL 目录
- DataFrame
- DataSet
- RDD
- DataFrame,DataSet与RDD之间转换
- DataFrame,DataSet与RDD之间的关系
- DataFrame,DataSet与RDD之间共性与区别
1.Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用。
2.Spark SQL 与 Hive SQL 比较
Hive SQL是转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduc的程序的复杂性,MapReduce这种计算模型执行效率比较慢。
Spark SQL是转换成RDD,然后提交到集群执行,执行效率非常快!
3.DataFrame
DataFrame是一个分布式数据容器,除了数据以外,还记录数据的结构信息。DataFrame为数据提供了Schema的视图。我们可以把它当做数据库中的一张表来对待,DataFrame是懒执行的,性能上比RDD要高。
4.DataSet
Dataset是具有强类型的数据集合,需要提供对应的类型信息。
5.RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
RDD后面会单独拿出来谈一谈。
6.DataFrame,DataSet与RDD之间转换
- RDD转DataSet
SparkSQL能够自动将包含有case类的RDD转换成DataFrame,case类定义了table的结构,case类属性通过反射变成了表的列名。
// 样例类
case class Person(name: String, age: BigInt)
// 创建配置对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkSQL").setMaster("local[*]")
// 创建上下文对象
val sparkSession: SparkSession = SparkSession
.builder()
.config(sparkConf)
.getOrCreate()
// 增加隐式转换规则
import sparkSession.implicits._
val rdd: RDD[(String, Int)] = sparkSession.sparkContext.makeRDD(Array(("zhaoliu", 20)))
// RDD转换DataSet
val person: Dataset[Person] = rdd.map(x => Person(x._1, x._2)).toDS()
- DataSet转换成RDD
// 样例类
case class Person(name: String, age: BigInt)
// 创建DataSet
val dataSet: Dataset[Person] = Seq(Person("zhansan", 32)).toDS()
// DataSet转换成RDD
dataSet.rdd
- DataFrame转DataSet
// 样例类
case class Person(name: String, age: BigInt)
// 获取数据,将数据转换成DataFrame
val dateFrame: DataFrame = sparkSession.read.json("input/user.json")
// DataFrame 转换成 DataSet
val dataSet: Dataset[Person] = dateFrame.as[Person]
- DataSet转DataFrame
// 样例类
case class Person(name: String, age: BigInt)
// 获取数据,将数据转换成DataFrame
val dateFrame: DataFrame = sparkSession.read.json("input/user.json")
// DataFrame 转换成 DataSet
val dataSet: Dataset[Person] = dateFrame.as[Person]
// DataSet 转换成 DataFrame
val df: Dataset[Person] = dataSet.asDF
7.DataFrame,DataSet与RDD之间的关系
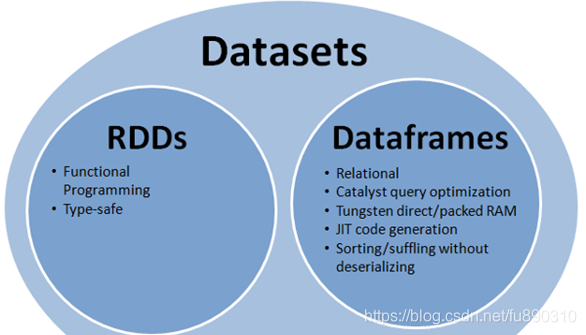
在SparkSQL中Spark为我们提供了两个新的抽象,分别是DataFrame和DataSet。
他们和RDD有什么区别呢?首先从版本的产生上来看:
RDD (Spark1.0) —> Dataframe(Spark1.3) —> Dataset(Spark1.6)
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同是的他们的执行效率和执行方式。
在后期的Spark版本中,DataSet会逐步取代RDD和DataFrame成为唯一的API接口。
8.DataFrame,DataSet与RDD之间共性与区别
- 共性
- RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
- 三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算。
- 三者都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出。
- 三者都有partition的概念
- 三者有许多共同的函数,如filter,排序等
- 在对DataFrame和Dataset进行操作许多操作都需要这个包进行支持
import spark.implicits._ - DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型
dataFrame.map{
case Row(col1:String,col2:Int)=>
println(col1);println(col2)
col1
case _=>
""
}
// 样例类,定义字段名和类型
case class Coltest(col1:String,col2:Int)extends Serializable
dataSet.map{
case Coltest(col1:String,col2:Int)=>
println(col1);println(col2)
col1
case _=>
""
}
- 区别
-
RDD:
1)RDD一般和spark mlib同时使用
2)RDD不支持sparksql操作 -
DataFrame:
1)与RDD和Dataset不同,DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值,如:
dataFrame.foreach{
line =>
val col1=line.getAs[String]("col1")
val col2=line.getAs[String]("col2")
}
2)DataFrame与Dataset一般不与spark mlib同时使用
3)DataFrame与Dataset均支持sparksql的操作,比如select,groupby之类,还能注册临时表/视窗,进行sql语句操作,如:
// 创建视图
dataFrame.createOrReplaceTempView("tmp")
spark.sql("select ROW,DATE from tmp where DATE is not null order by DATE").show
4)DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
// 保存
val saveOptions = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://hadoop102:9000/test")
dataFrame.write.format("com.atguigu.spark.csv").mode(SaveMode.Overwrite).options(saveOptions).save()
// 读取
val options = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://hadoop102:9000/test")
val dataFrame= spark.read.options(options).format("com.atguigu.spark.csv").load()
利用这样的保存方式,可以方便的获得字段名和列的对应,而且分隔符(delimiter)可以自由指定。
3. Dataset:
1)Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同。
2)DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段。而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息
// 样例类:定义字段名和类型
case class Coltest(col1:String,col2:Int)extends Serializable
/**
rdd
("a", 1)
("b", 1)
("a", 1)
**/
val dataSet: Dataset[Coltest]=rdd.map{line=>
Coltest(line._1,line._2)
}.toDS
dataSet.map{
line=>
println(line.col1)
println(line.col2)
}
可以看出,Dataset在需要访问列中的某个字段时是非常方便的,然而,如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题
