
DQL数据查询语言
查询不会对数据库中的数据进行修改.只是一种显示数据的方式
1.简单查询
1.1 查询表所有的行和列的数据
- 语法
select * from 表名;
- 具体操作
select * from student;
1.2 查询指定列
- 语法
select 字段名1,字段名2..... from 表名;
- 具体操作
select name, age from student;
2.别名 as
2.1 使用别名的好处
显示的时候使用新的名字,并不修改表的结构。
- 注:
- as可以省略不写,写空格即可
- 表使用别名的原因: 用于多表查询操作
2.2 语法
- 对列指定别名
select 字段名1 as 别名, 字段名2 as 别名 .... from 表名; - 对列和表同时指定别名
select 字段名1 as 别名, 字段名2 as 别名 .... from 表名 as 表别名; 2.3 具体操作
-- 使用别名
select name as 姓名, age as 年龄 from student; -- 表使用别名 select st.name as 姓名, age as 年龄 from student as st 3.清除重复值 distinct
3.1 查询指定列并且结果不出现重复数据。
select distinct 字段名 from 表名;
3.2 具体操作
-- 查询学生来自于哪些地方
select address from student;
-- 去掉重复的记录
select distinct address from student; 4.查询结果参与运算
4.1 语法
-- 某列数据和固定值运算
select 列名1 + 固定值 from 表名;
-- 某列数据和其他列数据产于运算 select 列名1 + 列名2 from 表名; 4.2 需求
准备数据:添加数学,英语成绩列,给每条记录添加对应的数学和英语成绩
查询的时候将数学和英语的成绩相加
4.3 实现
select * from student;
-- 给所有的数学加5分
select math+5 from student; -- 查询math+english的和 select *,(math+english) as 总成绩 from student; -- 查询math+english的和 省略as select *,(math+english) 总成绩 from student; 5.条件查询 where
5.1 为什么要条件查询
如果没有条件查询,则每次查询所有的行。
实际应用中,一般要指定查询的条件, 对记录进行过滤。
5.2 条件查询语法
select 字段名 from 表名 where 条件;
-- 条件查询流程: 取出表中的每条数据, 满足条件的记录就返回, 不满足条件的记录不返回
5.3 准备数据
-- 创建一个学生表
create table student3 (
id int, -- 编号 name varchar(20), -- 性别 age int, -- 年龄 sex varchar(5), -- 性别 address varchar(100), -- 地址 math int, -- 数学 english int -- 英语 ); -- 添加记录 INSERT INTO student3(id,NAME,age,sex,address,math,english) VALUES (1,'马云',55,'男','杭州',66,78),(2,'马化腾',45,'女','深圳',98,87),(3,'马景涛',55,'男','香港',56,77),(4,'柳岩',20,'女','湖南',76,65),(5,'柳青',20,'男','南',86,NULL),(6,'刘德华',57,'男','香港',99,99),(7,'马德',22,'女','香港',99,99),(8,'德玛西亚',18,'男','南京',56,65); 6. 排序order by
通过ORDER BY 子句,可以将查询出的结果进行排序(排序只是显示方式,不会影响数据库中数据的顺序)
- 语法
SELECT 字段名 FROM 表名 WHERE 字段= 值 ORDER BY 字段名 [ASC|DESC]; asc : 升序,默认 desc : 降序 6.1 单列排序
- 什么是单列排序?
只按某一个字段进行排序
- 实现
-- 查询所有数据,使用年龄降序排序
select * from student order by age desc; 6.2 组合排序
- 什么是组合排序?
同时对多个字段进行排序,如果第 1 个字段相等,则按第 2 个字段排序,依次类推。
- 语法
SELECT 字段名 FROM 表名 WHERE 字段= 值 ORDER BY 字段名 1 [ASC|DESC], 字段名 2 [ASC|DESC]; - 实现
-- 查询所有数据,在年龄降序排序的基础上,如果年龄相同再以数学成绩升序排序
select * from student order by age desc , math asc; 7. 聚合函数/分组函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向询, 它是对一列的值进行计算,然后返回一个结果值。聚合函数会忽略空值 NULL。
7.1 五个聚合函数
| SQL 中的聚合函数 | 作用 |
|---|---|
| max( 列名) | 求这一列的最大值 |
| min( 列名) | 求这一列的最小值 |
| avg( 列名) | 求这一列的平均值 |
| count( 列名) | 统计这一列有多少条记录 |
| sum( 列名) | 对这一列求总和 |
7.2 语法
SELECT 聚合函数( 列名) FROM 表名;
-- 查询学生总数
select count(id) as 总人数 from student; select count(*) as 总人数 from student; 我们发现对于 NULL 的记录不会统计,建议如果统计个数则不要使用有可能为 null 的列,但如果需要把 NULL也统计进去呢?
IFNULL( 列名,默认值) 如果列名不为空,返回这列的值。如果为 NULL ,则返回默认值。 -- 查询 id 字段,如果为 null,则使用 0 代替
select ifnull(id,0) from student; -- 我们可以利用 IFNULL()函数,如果记录为 NULL,给个默认值,这样统计的数据就不会遗漏 select count(ifnull(id,0)) from student; 7.3 实现
-- 查询年龄大于 20 的总数
select count(*) from student where age>20; -- 查询数学成绩总分 select sum(math) 总分 from student; -- 查询数学成绩平均分 select avg(math) 平均分 from student; -- 查询数学成绩最高分 select max(math) 最高分 from student; -- 查询数学成绩最低分 select min(math) 最低分 from student; 8. 分组 group by
分组查询是指使用 GROUP BY 语句对查询信息进行分组,相同数据作为一组
- 语法
SELECT 字段 1, 字段 2... FROM 表名 GROUP BY 分组字段 [HAVING 条件]; - group by 怎么分组的?
将分组字段结果中相同内容作为一组,如按性别将学生分成 2 组。

GROUP BY 将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用。
-- 按性别进行分组,求男生和女生数学的平均分
select sex, avg(math) from student3 group by sex; 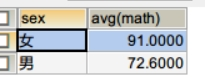
实际上是将每组的 math 求了平均,返回每组统计的结果
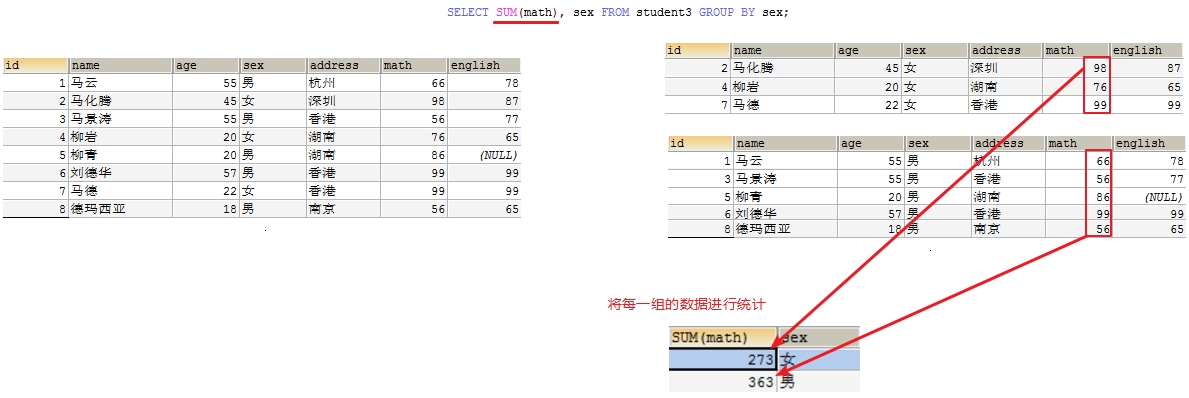
- 注意:
当我们使用某个字段分组,在查询的时候也需要将这个字段查询出来,否则看不到数据属于哪组的
- 练习1: 查询男女各多少人
-- 查询所有数据,按性别分组。
-- 统计每组人数
select sex, count(*) from student3 group by sex; 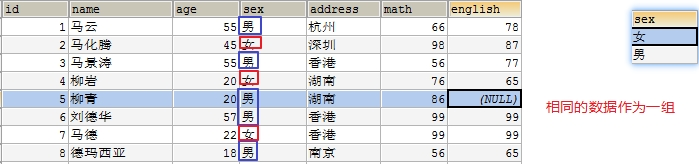
- 练习2: 查询年龄大于 25 岁的人,按性别分组,统计每组的人数
-- 先过滤掉年龄小于 25 岁的人。
-- 再分组
-- 最后统计每组的人数
select sex, count(*) from student3 where age > 25 group by sex ; 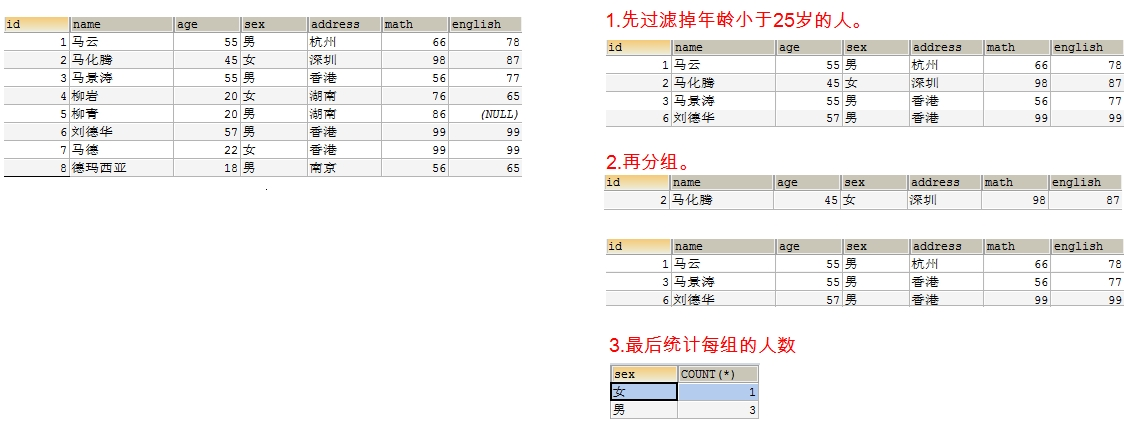
- 练习3: 查询年龄大于 25 岁的人,按性别分组,统计每组的人数,并只显示性别人数大于 2 的数据
-- 对分组查询的结果再进行过滤 只有分组后人数大于 2 的`男`这组数据显示出来
SELECT sex, COUNT(*) FROM student3 WHERE age > 25 GROUP BY sex having COUNT(*) >2; 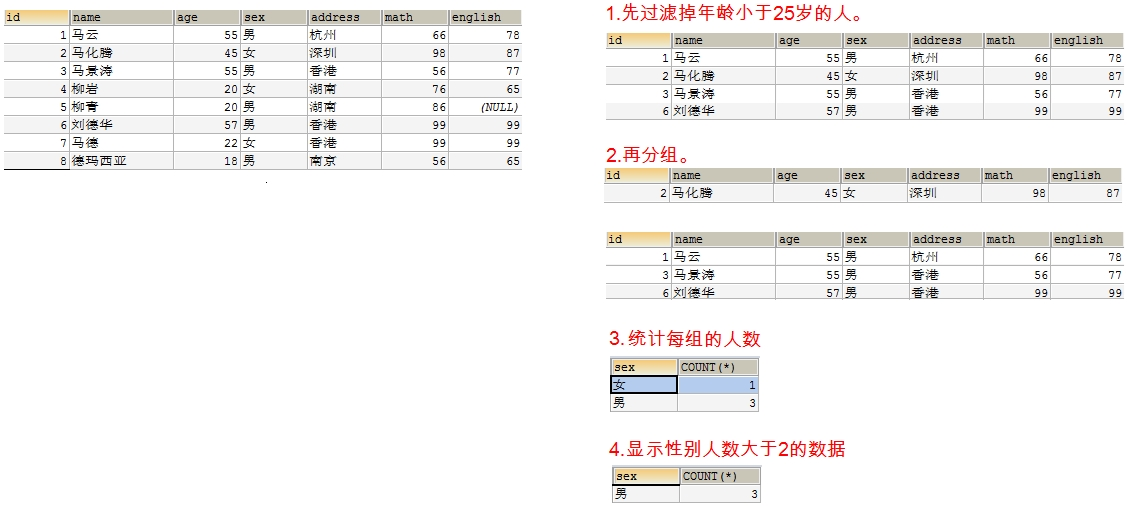
9. 分组运算 having
9.1 语法
SELECT 字段1,字段2… FROM 表名 GROUP BY分组字段 HAVING 分组条件; 9.1 having和where的区别
| 子名 | 作用 |
|---|---|
| where 子句 | 1) 对查询结果进行分组前,将不符合 where 条件的行去掉,即在分组之前过滤数据,即先过滤再分组。 2) where 后面不可以使用聚合函数 |
| having 子句 | 1) having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。2) having 后面可以使用聚合函数 |
9.2 注意
having参与运算的列, 必须在select中体现出来。
10. limit语句
10.1 准备数据
INSERT INTO student3(id,NAME,age,sex,address,math,english) VALUES (9,'唐僧',25,'男','长安',87,78), (10,'孙悟空',18,'男','花果山',100,66), (11,'猪八戒',22,'男','高老庄',58,78), (12,'沙僧',50,'男','流沙河',77,88), (13,'白骨精',22,'女','白虎岭',66,66), (14,'蜘蛛精',23,'女','盘丝洞',88,88); 10.2 limit的作用
LIMIT 是限制的意思,所以 LIMIT 的作用就是限制查询记录的条数。
- 语法
SELECT *| 字段列表 [as 别名] FROM 表名 [WHERE 子句] [GROUP BY 子句][HAVING 子句][ORDER BY 子句][LIMIT 子句]; /* LIMIT offset,length; offset: 起始行数, 从0开始计数, 如果省略, 默认就是0 length: 返回的行数 */ - 实现
-- 查询学生表中数据,从第 3 条开始显示,显示 6 条。
select * from student3 limit 2,6; 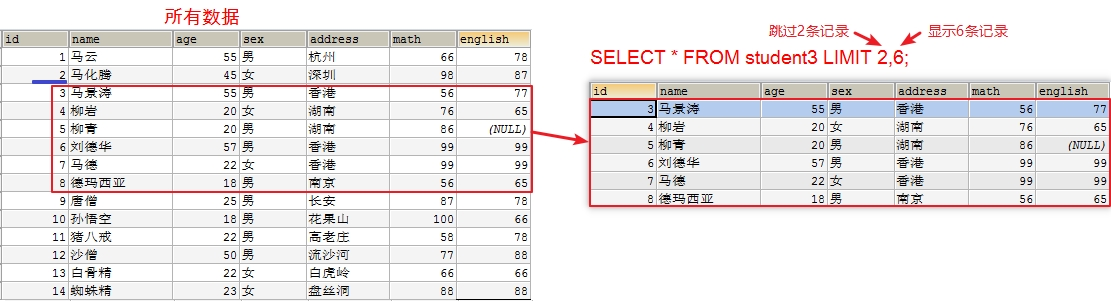
10.3 limit的使用场景
分页:比如我们登录京东,淘宝,返回的商品信息可能有几万条,不是一次全部显示出来。是一页显示固定的条数。 假设我们每页显示 5 条记录的方式来分页。
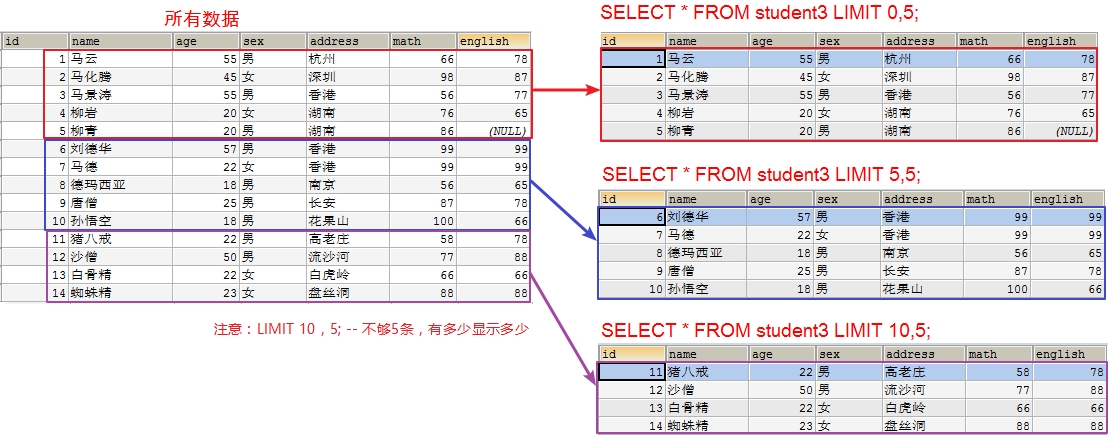
-- 如果第一个参数是 0 可以省略写:
select * from student3 limit 5; -- 最后如果不够 5 条,有多少显示多少
select * from student3 limit 10,5; 11. 查询总结
11.1 书写顺序
select 字段 from 表名 where 条件 group by 字段 having 运算条件 order by 字段
11.2 执行顺序
-
- from 表名
-
- where 条件
-
- group by 字段
- 字段相同的数据会被分为一组
-
- having 条件
- 对每一组分别进行一次运算
-
- select 字段
- 把每组中第一条数据取出来。合并成一张新伪表,展示这个新伪表上的部分字段
-
- order by 字段
- 对新伪表进行最后排序
OK,这篇就到这里
来源:百科