2020年3月21日09:20:19
之前已经学习过 文本处理三剑客中的grep(egrep),今天来看其他两个命令:awk、sed。
文本处理命令
| 命令 | 描述 |
|---|---|
| grep | 默认不支持扩展表达式,加-E 选项开启 ERE。如果不加-E 使用花括号要加转义符 \ { \ } |
| egrep | 都支持 |
| awk | 支持 同egrep |
| sed | 默认不支持扩展表达式,加-r 选项开启 ERE。如果不加-r 使用花括号要加转义符\ { \ } |
下面是sed命令:
[root@localhost shell_study]# sed --help
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...
-n, --quiet, --silent
suppress automatic printing of pattern space
-e script, --expression=script
add the script to the commands to be executed
-f script-file, --file=script-file
add the contents of script-file to the commands to be executed
--follow-symlinks
follow symlinks when processing in place
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if SUFFIX supplied)
-c, --copy
use copy instead of rename when shuffling files in -i mode
-b, --binary
does nothing; for compatibility with WIN32/CYGWIN/MSDOS/EMX (
open files in binary mode (CR+LFs are not treated specially))
-l N, --line-length=N
specify the desired line-wrap length for the `l' command
--posix
disable all GNU extensions.
-r, --regexp-extended
use extended regular expressions in the script.
-s, --separate
consider files as separate rather than as a single continuous
long stream.
-u, --unbuffered
load minimal amounts of data from the input files and flush
the output buffers more often
-z, --null-data
separate lines by NUL characters
--help
display this help and exit
--version
output version information and exit
If no -e, --expression, -f, or --file option is given, then the first
non-option argument is taken as the sed script to interpret. All
remaining arguments are names of input files; if no input files are
specified, then the standard input is read.
GNU sed home page: <http://www.gnu.org/software/sed/>.
General help using GNU software: <http://www.gnu.org/gethelp/>.
E-mail bug reports to: <[email protected]>.
Be sure to include the word ``sed'' somewhere in the ``Subject:'' field.
sed命令
| sed详解 |
- 在Linux中 “一切皆文件”,但在使用常见的vim、cat、more等命令时,对诸如日志文件 配置文件等较大文件的编辑查询的效率并不是很高。而sed 命令是利用脚本来处理文本文件,即:可依照脚本的指令来处理、编辑文本文件。它主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。 因此,使用awk sed grep等这些工具,就可以在达到同样效果的前提下节省大量的重复性工作成本,提高工作效率。(繁杂的重复性文件操作:删除 增加 注释 修改等 + 大量需要操作的文件 = 人力物力财力被浪费)
- 与vim等不同的是:被处理的文件内容可以是来自文件,也可以直接来自键盘或管道等标准输入。最后的结果默认情况下是显示到终端的屏幕上,但是也可以输出到文件中,且无需全部将其加载至内存中。
sed 命令
---------------------------------------------------------------------
语法格式如下:
sed [选项] [sed命令] [输入文件(需要修改的文件)]
或:sed [-hnV][-e<script>][-f<script文件>][文本文件]
注:
1、注意sed以及后面选项,sed命令和输入文件,每个元素之间都至少有一个空格。
2、sed -commands(sed命令)是sed内置的一些命令选项,为了和前面的options(选项)区分,故称为sed命令
3、sed -commands 既可以是单个sed命令,也可以是多个sed命令组合。使用的时候加上 单or双引号
4、input -file (输入文件)是可选项,sed还能够从标准输入如管道获取输入。
---------------------------------------------------------------------
参数(选项)说明:
-e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。即:一行命令语句可以执行多条sed命令
-f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
-h或--help 显示帮助。
-n或--quiet或--silent 仅显示script处理后的结果。即:取消默认的sed的输出,常与sed命令的p连用。不输出模式空间的内容
--version 显示版本信息。
-r 使用扩展正则表达式,默认情况sed只识别基本正则表达式。+ | ?
-i 直接修改文件内容,而不是输出到终端,如果不使用-i选项sed软件只是修改在内存中的数据,并不会影响磁盘上的文件
---------------------------------------------------------------------
sed命令说明:
a (append):追加操作。即:在指定行后添加一行或多行文本(追加文本到指定行后)
c (change):取代指定的行
d (delete):删除指定的行
i (insert):插入操作。即:在指定行前添加一行或多行文本(插入文本到指定行前)
p ( print):打印模式空间内容,通常p会与选项-n一起使用
! :取反操作。即:对指定行以外的所有行应用命令
---------------------------------------------------------------------
原理说明:
sed读取一行,首先将这行放入到缓存中。然后才对这行进行处理。完成以后,将缓冲区的内容发送到终端(屏幕)。
存储sed读取到的内容的缓存区空间称之为:模式空间(Pattern Space)
下面详细介绍sed命令的增删改查操作:
注:下面的命令使用只要不加 -i操作,都是随意操作文件的(并不实质修改文件内容)。
sed增加
这里我们需要用到上面的2个sed命令,分别是:a 和 i
[root@localhost shell_study]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]# sed "9a Hello,I am Songbaobao" test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
Hello,I am Songbaobao #只是看到了这个效果
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin #文件内容没有变
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]#
--------------------------------------------------------------
[root@localhost shell_study]# sed "9a Hello,I am Songbaobao" test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
Hello,I am Songbaobao #这是原第九行的后面追加
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]# sed "10i Hello,I am Songbaobao" test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
Hello,I am Songbaobao #这是原第十行的前面插入
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]#
--------------------------------------------------------------
[root@localhost shell_study]# 下面是支持 $ 表示最后一行
[root@localhost shell_study]# sed "$a Hello,I am Songbaobao" test.txt
sed: -e expression #1, char 3: extra characters after command
[root@localhost shell_study]# sed '$a Hello,I am Songbaobao' test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
Hello,I am Songbaobao #这是原最后一行的后面追加
[root@localhost shell_study]#
[root@localhost shell_study]# sed '$i Hello,I am Songbaobao' test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
Hello,I am Songbaobao #这是原最后一行的前面插入
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]#
--------------------------------------------------------------
[root@localhost shell_study]# 下面表示的是多行的插入
[root@localhost shell_study]# sed '$a Hello,I am Songbaobao\nTsinghua\nPekingUniversity\nZhejiangUniversity' test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
Hello,I am Songbaobao #这是原最后一行的后面追加 多行内容
Tsinghua
PekingUniversity
ZhejiangUniversity
[root@localhost shell_study]#
sed删除
这里我们需要用到上面的sed命令是:d 。同上:sed可以对单行或多行文本进行处理。若是在sed命令前面不指定地址范围,那么默认会匹配所有行。
[root@localhost shell_study]# sed 'd' test.txt
[root@localhost shell_study]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]# 下面是删除第一行
[root@localhost shell_study]# sed '1d' test.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]# 下面是删除1到5行
[root@localhost shell_study]# sed '1,5d' test.txt
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]# 下面是删除匹配到的行
[root@localhost shell_study]# sed '/^root/d' test.txt 匹配root开头的行
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]# sed '/root/d' test.txt 匹配到root的行
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
[root@localhost shell_study]#
注:如上,在sed使用正则的格式和awk一样,使用2个”/“包含指定的正则表达式,即“/正则表达式/”。
[root@localhost shell_study]# sed '2,$d' test.txt 从第2行开始删完
root:x:0:0:root:/root:/bin/bash
----------------------------------------------------------------
[root@localhost shell_study]# 下面是sed的取反 ! 的使用
[root@localhost shell_study]# 下面是删除除 1 2行的
[root@localhost shell_study]# sed '1,2!d' test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@localhost shell_study]#
sed修改
这里我们需要用到上面的sed命令是:c 。即:change,意思是替换
[root@localhost shell_study]# sed '1c Hello,I am Songbaobao' test.txt
Hello,I am Songbaobao #修改替换的是第一行
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost shell_study]#
下面是文本替换:(将root全部替换成songbaobao)
这里用到的sed命令,其中的选项如下:
- “s”:单独使用–>将每一行中第一处匹配的字符串进行替换==>sed命令
- “g”:每一行进行全部替换–>sed命令 s的替换标志之一(全局替换global),非sed命令。
- “-i”:修改文件内容==>sed的选项,注意和sed命令i区别。(不加 -i 就不修改文件的实际内容)
[root@localhost myshell]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed 's/root/songbaobao/' test.txt #不加g标志
songbaobao:x:0:0:root:/root:/bin/bash # 只替换了每一行的第一个匹配内容
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/songbaobao:/sbin/nologin# 只替换了每一行的第一个匹配内容
[root@localhost myshell]# sed 's/root/songbaobao/g' test.txt #加g标志
songbaobao:x:0:0:songbaobao:/songbaobao:/bin/bash# 替换了每一行的全部 匹配内容
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/songbaobao:/sbin/nologin# 替换了每一行的全部 匹配内容
[root@localhost myshell]#
[root@localhost myshell]# sed '/^root/{s/root/songbaobao/g}' test.txt
songbaobao:x:0:0:songbaobao:/songbaobao:/bin/bash#只替换了以root开头的行的全部 匹配内容
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed '/^root/{s/root/songbaobao/}' test.txt
songbaobao:x:0:0:root:/root:/bin/bash#只替换了以root开头的行的第一个 匹配内容
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
#-------------------------------------------------------------------------
[root@localhost myshell]# cp /etc/sysconfig/selinux ./linux.txt
[root@localhost myshell]# ls
linux.txt test.txt
[root@localhost myshell]# cat linux.txt
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=enforcing
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@localhost myshell]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' linux.txt
[root@localhost myshell]# cat linux.txt
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@localhost myshell]# 下面将使用上 分组 \1进行调用;-r为扩展正则
[root@localhost myshell]# sed -i -r 's/(SELINUX=)disabled/\1enforcing/' linux.txt
[root@localhost myshell]# cat linux.txt
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=enforcing
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@localhost myshell]#
sed查询
这里我们需要用到上面的sed命令是:“p”。即:输出指定内容,但默认会输出2次匹配的结果,因此使用-n选项取消默认输出:print。
相较于之前最常用的是cat或more或less命令等,sed就能查看指定的行 。而且我们前面也说过使用sed比其他命令vim等读取速度更快!
[root@localhost myshell]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed '2p' test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin #第二行被多打印了一遍
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# 可是我不想看到重复的这一行,即:只想要这个 第二行。如下:
[root@localhost myshell]# sed -n '2p' test.txt
bin:x:1:1:bin:/bin:/sbin/nologin
[root@localhost myshell]# 打印多行,如下:
[root@localhost myshell]# sed -n '2,5p' test.txt #若是不加-n
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost myshell]# #若是不加-n
[root@localhost myshell]# sed '2,5p' test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
#-------------------------------------------------------------------------
[root@localhost myshell]# sed -n '/root/p' test.txt
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
注:在使用上面的p的时候 不要同 -i 进行混合使用。具体原因如下:
[root@localhost myshell]# sed -n '2p' test1.txt
bin:x:1:1:bin:/bin:/sbin/nologin #只把第二行打印出来了
[root@localhost myshell]# cat test1.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed -ni '2p' test1.txt
[root@localhost myshell]# cat test1.txt
bin:x:1:1:bin:/bin:/sbin/nologin #-i 把第二行给写到原文件里面了
[root@localhost myshell]#
下面是加上 -e,执行的多点操作:
[root@localhost myshell]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed -e "1d" -e "3d" -e "5d" test.txt 删除1 3 5行
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed -n -e '2p' -e '5p' test.txt 只查2 5行
bin:x:1:1:bin:/bin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost myshell]#
下面展示一下 怎么删除注释行和空白行:
[root@localhost myshell]# ls
test.txt
[root@localhost myshell]# vim test.txt
[root@localhost myshell]# cat test.txt
#root:x:0:0:root:/root:/bin/bash
#bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed -e '/^#/d' -e '/^$/d' test.txt
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#下面展示 第二种方式:grep
#---------------------------------------------------------------
[root@localhost myshell]# cat test.txt
#root:x:0:0:root:/root:/bin/bash
#bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# grep -E "(^#)|(^$)" test.txt 拿到要删除的行
#root:x:0:0:root:/root:/bin/bash
#bin:x:1:1:bin:/bin:/sbin/nologin
[root@localhost myshell]# grep -E -v "(^#)|(^$)" test.txt 取反
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# grep -E -v "(^#)|(^$)" test.txt >test1.txt
[root@localhost myshell]# cat test1.txt
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
sed命令 小结
- 查找指定的字符串
# 显示文件中保含root的行(显示模式空间中的内容)
[root@localhost myshell]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed -n '/root/p' test.txt
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
- 在指定的位置做增删
[root@localhost myshell]# sed '/^root/d' test.txt 删除以root为开头的行
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed '/root/a I am Songbabaobao' test.txt 在包含root的行后添加一行
root:x:0:0:root:/root:/bin/bash
I am Songbabaobao
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
I am Songbabaobao
[root@localhost myshell]#
- 按行替换(将5到9行的内容替换为I am Songbaobao)
[root@localhost myshell]# sed '5,9c I am Songbaobao' test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
I am Songbaobao
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
- 按照字符替换(上面已经展示过了:将/etc/selinux/config中的SELINUX=disabled改成 enforcing)
# sed -i 's/SELINUX=disabled/SELINUX=enforcing/g' 文件
# sed -r -i 's/(SELINUX=)disabled/\1enforcing/g' 文件
- 查找指定的内容再做替换
# 将以r开头的行中的oo替换为666
[root@localhost myshell]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]# sed '/^r/{s/oo/666/g}' test.txt #找到匹配行,做替换
r666t:x:0:0:r666t:/r666t:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
- 多点编辑
上面的删除#注释行和空白行
sed -e '/^#/d' -e '/^$/d' test.txt
grep -E -v "(^#)|(^$)" test.txt >test1.txt
- 取反操作
# 显示非1-3行
[root@localhost myshell]# sed -n '1,3!p' test.txt
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
awk命令
awk详解
| awk详解 |
awk不仅仅是linux系统中的一个命令,而且是一种编程语言:可以用来处理数据和生成报告(excel)。处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。
awk 命令
---------------------------------------------------------------------
语法格式如下:
1. awk 命令由模式,动作,或者模式和动作的组合组成。
2. pattern 类似模式匹配(理解为条件),可由表达式组成;亦可 / 正则表达式 /。
3. action 由{语句1;语句2;---}
---------------------------------------------------------------------
使用格式如下:
awk 【options(awk参数)】 'pattern(模式,即条件) {action}(动作,即找到之后干啥)' test.txt
注:awk 命令后面处理的内容的来源:标准输入、一个或多个文本文件、管道
---------------------------------------------------------------------
参数说明如下:
-F:指定分隔符
---------------------------------------------------------------------
常见概念如下:
4. record:一行就是一个记录
5. field separator:进行对记录进行切割的时候所使用的字符
6. field:将一条记录分割成的每一段 为字段
7. filename:当前处理文件的文件名
8. FS(Field Separator):字段分隔符(默认是以空格为分隔符)
9. NR(Number of Record):记录的编号(awk每读取一行,NR就加1)
10. NF(Number of Field):字段数量(记录了当前这条记录包含多少个字段)
11. ORS(Output Record Separator):指定输出记录分隔符(指定在输出结果中记录末尾是什么,默认是\n,也就是换行)
12. OFS(Output Field Separator):输出字段分隔符
13. RS:记录分隔符
下面看一下特殊的 $ 输出字段的表示:(对应字段的输出)
$1 输出第一个字段
$2 输出第二个字段
$NF 输出最后一个字段
$0 输出整个记录
| awk简单使用 |
下面主要是看一下awk命令的具体实例,其工作背景如下:
[root@localhost myshell]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
显示第2到5行的每条记录,如下
[root@localhost myshell]# awk 'NR>=2&&NR<=5{print $0}' test.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost myshell]#
如上:模式(条件)就是NR>=2&&NR<=5 ;后面的{} 自然就是匹配成功之后的动作(干啥)。也就是说:awk开始处理test.txt文件 读取第一行(NR=1 不满足条件);接下来再读取一行 NR=2(直到5都是满足的)满足一行 就执行后面的动作一次。直到6 7 8 9 最后一行(End Of File)。
显示全文,并前面有行号,如下
[root@localhost myshell]# awk '{print NR,$0}' test.txt
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell]#
显示全文每条记录的bash类型,如下
注:那也就是要打印 每条记录 :分开的最后一列
[root@localhost myshell]# awk -F ":" '{print NR,$7}' test.txt
1 /bin/bash
2 /sbin/nologin
3 /sbin/nologin
4 /sbin/nologin
5 /sbin/nologin
6 /bin/sync
7 /sbin/shutdown
8 /sbin/halt
9 /sbin/nologin
10 /sbin/nologin
[root@localhost myshell]# awk -F ":" '{print NR,$NF}' test.txt
1 /bin/bash
2 /sbin/nologin
3 /sbin/nologin
4 /sbin/nologin
5 /sbin/nologin
6 /bin/sync
7 /sbin/shutdown
8 /sbin/halt
9 /sbin/nologin
10 /sbin/nologin
[root@localhost myshell]#
输出有大于5个字段的行的第三个字段,如下
注:现在test.txt里面 每个记录的字段数都大于5 预收相当于把全文的第三个字段都打印出来了
[root@localhost myshell]# awk -F ":" 'NF>5{print NR,$3}' test.txt
1 0
2 1
3 2
4 3
5 4
6 5
7 6
8 7
9 8
10 11
[root@localhost myshell]#
输出每行行号和该行有几个字段,如下
[root@localhost myshell]# awk -F ":" '{print NR,NF}' test.txt
1 7
2 7
3 7
4 7
5 7
6 7
7 7
8 7
9 7
10 7
[root@localhost myshell]#
awk正则表达式
| awk正则表达式 |
工作的背景内容同上。我们上面也说过了awk支持 基础正则表达式和扩展正则表达式:
简单地使用正则表达式的例子,如下
[root@localhost myshell]# free -h
total used free shared buff/cache available
Mem: 2.9G 275M 2.3G 9.1M 355M 2.4G
Swap: 2.0G 0B 2.0G
[root@localhost myshell]# free -m
total used free shared buff/cache available
Mem: 3018 276 2386 9 355 2477
Swap: 2047 0 2047
[root@localhost myshell]# free -h | awk -F "G" 'NR==2{print $2}'
276M 2.3
[root@localhost myshell]# free -h | awk -F "G" 'NR==2{print $2}' | awk -F "M" '{print $2}'
2.3
[root@localhost myshell]# free -h | awk -F " +" 'NR==2{print $4}'
2.3G
[root@localhost myshell]# free -m | awk -F " +" 'NR==2{print $4}'
2386
[root@localhost myshell]#
使用正则表达式 匹配整行,如下
[root@localhost myshell]# awk '/^root/' test.txt
root:x:0:0:root:/root:/bin/bash
[root@localhost myshell]# awk '/^root/{print $0}' test.txt
root:x:0:0:root:/root:/bin/bash
[root@localhost myshell]# awk '$0~/^root/' test.txt 整行后面使用正则表达式
root:x:0:0:root:/root:/bin/bash
[root@localhost myshell]# awk '$0~/^root/{print $0}' test.txt
root:x:0:0:root:/root:/bin/bash
[root@localhost myshell]#
注:awk只用正则表达式的时候是默认匹配整行的,即‘$0~/^root/’ 和 ‘/^root/’是一样的。
使用正则表达式 匹配某一列,如下
[root@localhost myshell]# awk -F ":" '$5~/root/' test.txt
root:x:0:0:root:/root:/bin/bash
[root@localhost myshell]# awk -F ":" '$5~/root/{print $0}' test.txt
root:x:0:0:root:/root:/bin/bash
[root@localhost myshell]#
注释上面:
- $5表示第五个区域(列)
- ~表示匹配(正则表达式匹配)
- /root/表示匹配root这个字符串
- $5~/root/表示第五个区域(列)匹配正则表达式/root/。即:第5列包含root这个字符串,则显示这一行。
使用正则表达式 匹配行尾为shutdown,如下
[root@localhost myshell]# awk '/shutdown$/{print $0}' test.txt
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
[root@localhost myshell]# awk -F ":" '/shutdown$/{print $0}' test.txt
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
[root@localhost myshell]#
显示名字和登录类型,如下
[root@localhost myshell]# awk -F ":" '{print $1,$NF}' test.txt
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
[root@localhost myshell]#
awk的特殊模式
| awk BEGIN&END模式 |
awk的两种特殊模式:
- BEGIN 模块在awk命令执行之前(读取文件)就执行,它主要是来定义 内置变量(预定义变量,例如:FS RS)。换言之:BEGIN模块是最先执行的(就是BEGIN后面的动作{ action }) 。awk必须在输入文件进行任何处理前先执行BEGIN里的动作(action)。我们可以不要任何输入文件,就可以对BEGIN模块进行测试,因为awk需要先执行完BEGIN模式,才对输入文件做处理。因此BEGIN模式常常被用来修改内置变量ORS,RS,FS,OFS等值。
- 而EHD模块是在awk读取完所有的文件的时候,再执行END模块(awk全部执行完 才执行END)。一般用来输出一个结果(如:累加,数组结果),也可以是和BEGIN模块类似的结尾标识信息。与BEGIN模式相对应的END模式,格式一样,但是END模式仅在awk处理完所有输入行后才进行处理。
[root@localhost myshell]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:4e:a9:01 brd ff:ff:ff:ff:ff:ff
inet 192.29.0.51/23 brd 192.29.1.255 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::9269:9004:6205:f3b7/64 scope link
valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 52:54:00:fe:41:90 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN qlen 1000
link/ether 52:54:00:fe:41:90 brd ff:ff:ff:ff:ff:ff
[root@localhost myshell]# ip a | awk '/global virbr0/{print $0}'
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
[root@localhost myshell]# ip a | awk '/global virbr0/{print $0}' | awk -F "( +)|/" '{print $3}'
192.168.122.1
[root@localhost myshell]# ip a | awk '/global virbr0/{print $0}' | awk 'BEGIN{FS="( +)|/"}{print $3}'
192.168.122.1
[root@localhost myshell]#
如上:使用BEGIN模块预定义了 分隔符。
[root@localhost myshell]# cat test.txt | awk '{print NR,$0}END{print "Hello,I am Songbaobao"}'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
Hello,I am Songbaobao
[root@localhost myshell]# awk -F ':' 'BEGIN{print "user_name","bash_type"}{print $1,$NF}END{print "Hello,I am Songbaobao"}' test.txt
user_name bash_type
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
Hello,I am Songbaobao
[root@localhost myshell]#
统计包含root的行的数量,如下
[root@localhost myshell]# cat test.txt | grep root | wc -l
2
[root@localhost myshell]# cat test.txt | grep -c root
2
[root@localhost myshell]# cat test.txt | awk 'BEGIN{i=0}/root/{i++}END{print i}'
2
[root@localhost myshell]# cat test.txt | awk '/root/{i++}END{print i}'
2
[root@localhost myshell]#
因此,带有BEGIN END模块的awk执行过程(命令结构),如下:
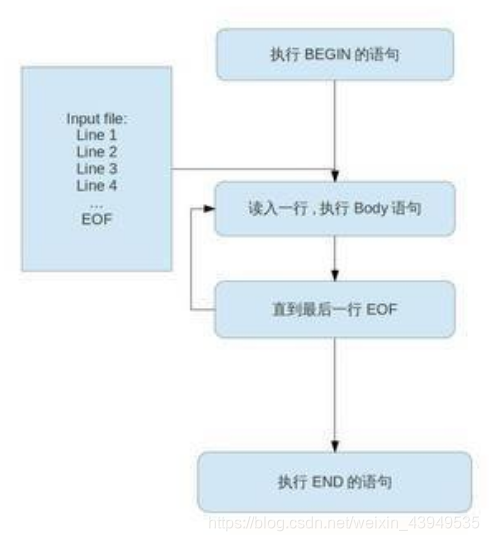
awk 'BEGIN{commands}/pattern/{commands}END{commands}' test.txt
awk数组的使用
| awk数组 |
awk 数组结构如下:
----------------------------------------------------
数组名【元素名】=值
array_name[element_name]=value
awk数组完成的任务 我们也可以使用cut sort unique来实现。当然使用awk相对来说,更加的简洁易懂。下面看一下awk数组使用:
统计域名出现的次数,如下
注:这个我们已经在第一节的时候,已经通过使用命令来实现过了。背景如下:
[root@localhost myshell]# vim test.txt
[root@localhost myshell]# cat test.txt
http://www.baidu.com
http://www.baidu.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
[root@localhost myshell]#
实现如下:
[root@localhost myshell]# cat test.txt | awk -F "/+" '{array[$2]++}END{for (i in array) print i,array[i]}'
www.sina.com 12
www.qq.com 6
www.taobao.com 6
www.baidu.com 16
[root@localhost myshell]#
awk命令 小结
背景同上!
- 结合内置变量,打印指定的几行,以及字段数量
# 输出有大于5个字段的行的第三个字段
[root@localhost myshell]# cat test1.txt | awk -F ":" 'NF>=5{print $3}'
0
1
2
3
4
5
6
7
8
11
# 输出每行行号和该行有几个字段
[root@localhost myshell]# cat test1.txt | awk -F ":" '{print NR,NF}'
1 7
2 7
3 7
4 7
5 7
6 7
7 7
8 7
9 7
10 7
# 输出用户名,要求所有用户显示在同一行,而且用空格分隔
[root@localhost myshell]# cat test1.txt | awk 'BEGIN{FS=":"; ORS=" "}{print $1}'
root bin daemon adm lp sync shutdown halt mail operator [root@localhost myshell]#
- 结合正则来匹配一行或者某个字段
# 输出用户名以s为开头的用户的uid
[root@localhost myshell]# cat test1.txt | awk -F ":" '/^s/{print $3}'
5
6
# 输出第五个字段是以t为结尾的用户的姓名
[root@localhost myshell]# cat test1.txt | awk -F ":" '$5~/t$/{print $1}'
root
halt
- 采用比较符号来进行打印指定的某些行
# 实现仅仅输出3-5的内容,每行前面添加一个行号
[root@localhost myshell]# cat test1.txt | awk 'NR>=3&&NR<=5{print NR,$1}'
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost myshell]# cat test1.txt | awk 'NR==3,NR==5{print NR,$1}'
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
# 实现仅仅输出3 和 5 和 7行的内容,每行前面添加一个行号
[root@localhost myshell]# cat test1.txt | awk 'NR==3||NR==5||NR==7{print NR,$1}'
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
下面的背景如下:
[root@localhost myshell]# cat test1.txt
#root:x:0:0:root:/root:/bin/bash
#bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
#lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:/sbin/nologin
[root@localhost myshell]#
- END
# 统计mypwd中以#开头的行有多少行
[root@localhost myshell]# cat test1.txt | awk 'BEGIN{n=0}/^#/{n+=1}END{print n}'
3
# 以:为分隔符,字段数量在5-8的行的数目
[root@localhost myshell]# cat test1.txt | awk 'BEGIN{FS=":"}NF>=5&&NF<=8{n+=1}END{print n}'
9
注:awk的学习 也可以参见这篇写的很好的博客
awk 用法(使用入门)
2020年3月30日18:31:44