摘要
为了解决PC端的bilibili无法下载视频的问题,使用python语言可以实现一个能够爬取bilibili某个视频资源(不包括会员视频)的程序。采用整个视频下载与分片拼接视频两种思路实现程序,比较两种方式的下载效率,最终采用分片下载视频再拼接成为一个视频的方式实现了bilibili视频(不包括会员视频)的下载。实现bilibili视频下载,可以用于离线观看或者收集视频素材用于剪辑,具有一定实际的用途。
引言
由于bilibili只能通过手机app下载视频缓存,电脑打开需要将缓存从手机将文件传到电脑,不方便。
本文从如何借助chorme浏览器的开发者工具与搜索引擎了解bilibili请求视频资源的方式、如何使用python的各种库模拟浏览器发送请求去获取bilibili服务器的视频资源、运行实现的python爬虫程序并下载一个视频三个步骤介绍bilibili视频爬虫的实现。
系统结构
使用到的工具
IntelliJ IDEA 2018.2.4 x64(集成开发环境)
Python3.8(编程语言)
requests库(发送http请求)
lxml库(xpath解析)
json库(解析json数据)
ffmpeg(合并音频和视频)
实现功能的原理
通过输入视频编号再拼接成为url,通过用python的request库使用url模拟浏览器请求访问视频页面。使用lxml库与json库从返回的响应信息中提取到视频资源的链接,再去模拟浏览器请求获取音频和视频资源,再将获得的音频和视频资源合并保存到本地。
实现代码
1.了解url结构
使用chorme浏览器,先到bilibili首页随便点开一个视频如图3.1所示。
图3.1
进入视频页面后,点进第二p,开始分析该页面的请求的结构如图3.2所示。
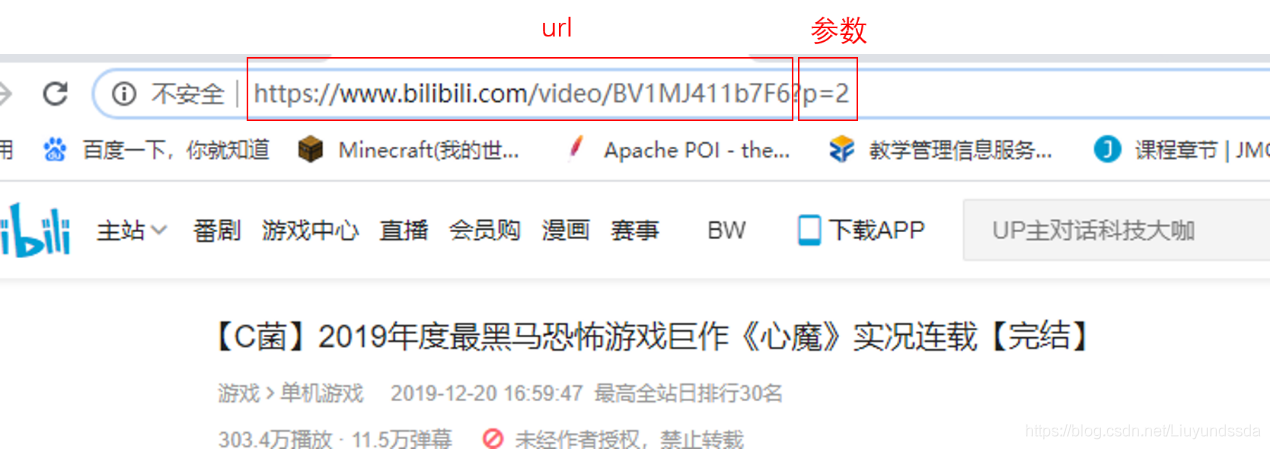
图3.2
可以看到请求由url和一个参数p拼接而成。
2.编写输入程序
访问页面需要的url结构为https://www.bilibili.com/video/BV号?p=,我们下载视频的话可以输入视频p数的分类来下载多个分p视频,总结以上需要输入程序的信息就包括视频BV号、起始p、结束p这三个信息,编写代码如下。
if __name__ == '__main__':
# 输入bilibili视频的BV号
bv = input('视频BV号:')
url='https://www.bilibili.com/video/'+bv
# 选择视频从第几p开始到第几p结束
startPart=input('起始P:')
endPart = input('终止P;')
print("url:",url)
print("startPart:",startPart)
print("endPart:",endPart)
输出结果如图3.3所示。
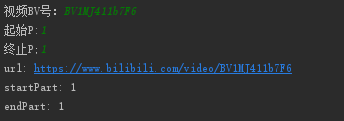
图3.3
3.解析网页,找到下载视频的链接
在chorme浏览器按下F12打开开发者工具,查找页面元素,找到在head标签的第3个script标签里面存有视频播放信息,划红线的baseUrl既是视频资源链接如图3.4所示。

图3.4
根据网上搜索了解到bilibili2018年后的视频分为音频与视频,但是在此标签里面没有找到与音频有关的键,这里我直接拷贝标签文本,放到文本编辑器notepad++中,查找“audio”发现了音频键值对,如图3.5所示。
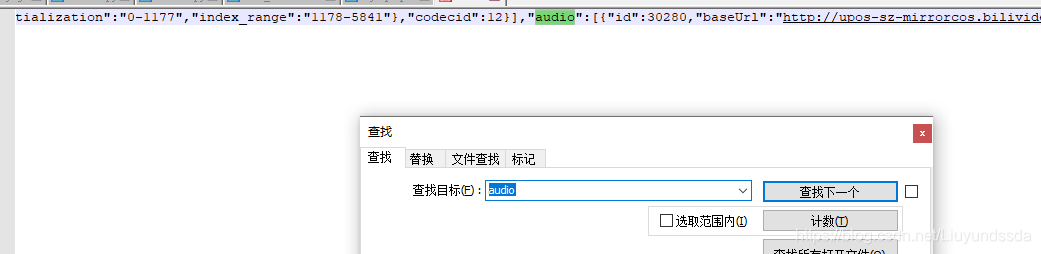
图3.5
其中“baseUrl”后面的内容就是音频资源链接,如图3.6所示。

图3.6
这里我需要先通过发送请求获取网页二进制文本信息,然后再通过解析文本获取需要的链接。
增加函数getBiliBiliVideo,使用到的库有json、os、requests、etree,代码如下。
import json
import requests
from lxml import etree
# 防止因https证书问题报错
requests.packages.urllib3.disable_warnings()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36',
'Refer'
'er': 'https://www.bilibili.com/'
}
'''
获取bilibili视频的主要函数
@param url 视频页面url 结构为:url?参数
@param p 视频p数
@param bv 视频bv数
'''
def getBiliBiliVideo(url,p,bv):
session = requests.session()
res = session.get(url=url,headers=headers,verify=False)
_element = etree.HTML(res.content)
# 获取window.__playinfo__的json对象,[20:]表示截取'window.__playinfo__='后面的json字符串
videoPlayInfo = str(_element.xpath('//head/script[3]/text()')[0].encode('utf-8').decode('utf-8'))[20:]
videoJson = json.loads(videoPlayInfo)
# 获取视频链接和音频链接
try:
# 2018年以后的b站视频由.audio和.video组成 flag=0表示分为音频与视频
videoURL = videoJson['data']['dash']['video'][0]['baseUrl']
audioURl = videoJson['data']['dash']['audio'][0]['baseUrl']
flag=0
except Exception:
# 2018年以前的b站视频音频视频结合在一起,后缀为.flv flag=1表示只有视频
videoURL = videoJson['data']['durl'][0]['url']
flag=1
print("videoURL:",videoURL)
print("audioURl:",audioURl)
print("flag:",flag)
if __name__ == '__main__':
getBiliBiliVideo("https://www.bilibili.com/video/BV1MJ411b7F6?p=2",2,"BV1MJ411b7F6")
输出结果图3.7所示。

图3.7
成功获取链接。
4.下载视频与音频
再去查看视频资源的网络请求,发现一共有两种请求方式,一种是GET,如图3.8所示。
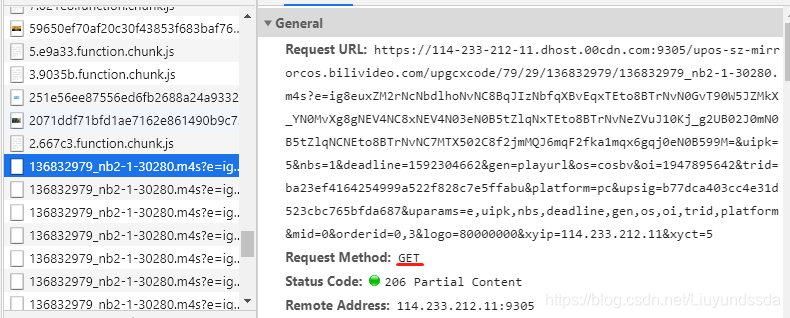
图3.8
另一种是OPTION,如图3.9所示。
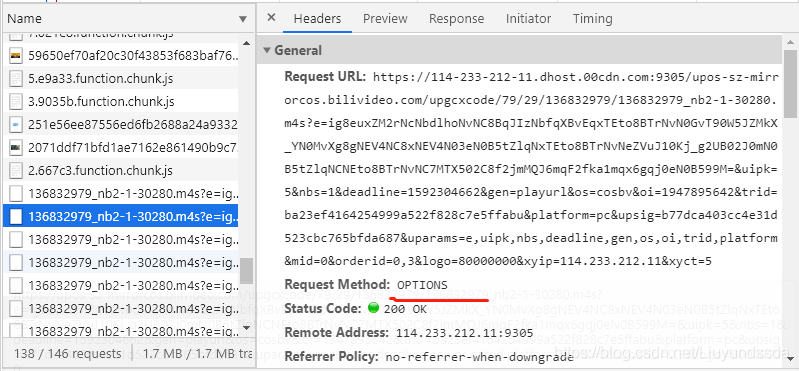
图3.9
所以视频资源可能需要先发送OPTION请求,获取服务器许可后再请求资源,许可的保持时间较长,所以只发一次Option请求就可以了,如图3.10所示。
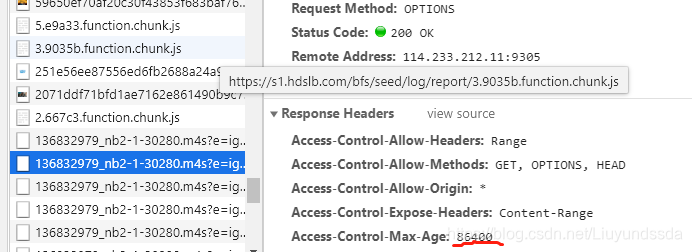
图3.10
这里有两种下载视频的方式:
第一种是利用416报错码分片下载,留意在请求头划红线的这两个参数,如图3.11所示。

图3.11
Referer用于写明来源,Range用于规定分片的字节大小以及范围,每下载一定字节的资源,就修改Range,直到最后一次字节数大于剩下的资源时,服务器返回416报错,再重新将Range设置为’Range’: ‘bytes=上一次开始的索引-’。把最后剩下的资源下载下来。每获得一个视频的分片就给他拼接到文件最后,最后得到完整文件。
第二种是不加入Range参数,直接下载整个的音频与视频,只需要注释掉添加请求头Range参数的语句即可。
增加函数为fileDownload,增加导入的库有json、os、requests、etree、os,代码如下。
import json
import os
import requests
from lxml import etree
# 防止因https证书问题报错
requests.packages.urllib3.disable_warnings()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36',
'Refer'
'er': 'https://www.bilibili.com/'
}
'''
获取bilibili视频的主要函数
@param url 视频页面url 结构为:url?参数
@param p 视频p数
@param bv 视频bv数
'''
def getBiliBiliVideo(url,p,bv):
session = requests.session()
res = session.get(url=url,headers=headers,verify=False)
_element = etree.HTML(res.content)
# 获取window.__playinfo__的json对象,[20:]表示截取'window.__playinfo__='后面的json字符串
videoPlayInfo = str(_element.xpath('//head/script[3]/text()')[0].encode('utf-8').decode('utf-8'))[20:]
videoJson = json.loads(videoPlayInfo)
# 获取视频链接和音频链接
try:
# 2018年以后的b站视频由.audio和.video组成 flag=0表示分为音频与视频
videoURL = videoJson['data']['dash']['video'][0]['baseUrl']
audioURl = videoJson['data']['dash']['audio'][0]['baseUrl']
flag=0
except Exception:
# 2018年以前的b站视频音频视频结合在一起,后缀为.flv flag=1表示只有视频
videoURL = videoJson['data']['durl'][0]['url']
flag=1
# 指定文件生成目录,如果不存在则创建目录
dirname = ("E:/result").encode("utf-8").decode("utf-8")
if not os.path.exists(dirname):
os.makedirs(dirname)
print('文件夹创建成功!')
# 获取每一集的名称
name = bv + "-" + str(p)
# 下载视频和音频
print('正在下载 "'+name+'" 的视频····')
fileDownload(homeurl=url,url=videoURL, name='E:/result/'+name + '_Video.mp4', session=session)
if flag == 0:
print('正在下载 "'+name+'" 的音频····')
fileDownload(homeurl=url,url=audioURl, name='E:/result/'+name+ '_Audio.mp3', session=session)
print(' "'+name+'" 下载完成!')
'''
使用session保持会话下载文件
@param homeurl 访问来源
@param url 音频或视频资源的链接
@param name 下载后生成的文件名
@session 用于保持会话
'''
def fileDownload(homeurl,url, name, session=requests.session()):
# 添加请求头键值对,写上 refered:请求来源
headers.update({'Referer': homeurl})
# 发送option请求服务器分配资源
session.options(url=url, headers=headers,verify=False)
# 指定每次下载1M的数据
begin = 0
end = 1024*512 - 1
flag = 0
while True:
# 添加请求头键值对,写上 range:请求字节范围
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
# 获取视频分片
res = session.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
# 响应码不为为416时有数据
begin = end + 1
end = end + 1024*512
else:
headers.update({'Range': str(end + 1) + '-'})
res = session.get(url=url, headers=headers,verify=False)
flag=1
with open(name.encode("utf-8").decode("utf-8"), 'ab') as fp:
fp.write(res.content)
fp.flush()
# data=data+res.content
if flag==1:
fp.close()
break
if __name__ == '__main__':
getBiliBiliVideo("https://www.bilibili.com/video/BV1MJ411b7F6?p=2",2,"BV1MJ411b7F6")
输出结果如图3.12所示。

图3.12
通过第一种分片下载视频得到音频与视频如图3.13所示。
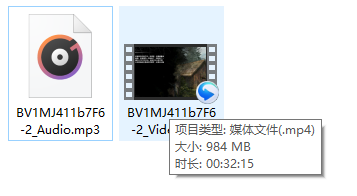
图3.13
而通过第二种直接下载视频得到的视频出现异常, 如图3.14所示,中途还是停止了下载,不考虑这个方法。
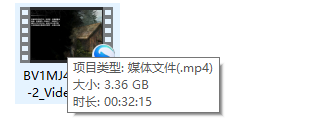
图3.14
最后推荐使用第一种方法分片下载音频与视频。
5.合并视频与音频
对于bilibili2018年以后的视频需要再多一步音频与视频合并的操作,这里通过ffmpeg来实现这个功能。
首先到https://ffmpeg.zeranoe.com/builds/下载static包,我的配置选择如图3.15所示。
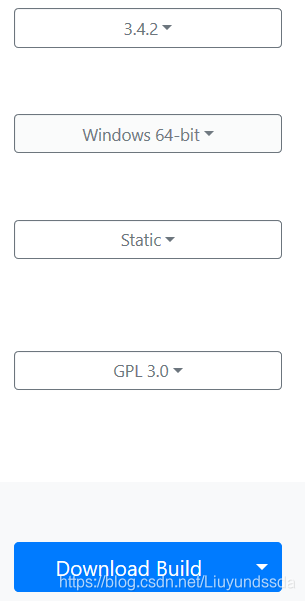
图3.15
下载zip包到自定义文件夹下解压,找到bin目录,如图3.16所示。

图3.16
将bin的完整目录添加到系统环境变量Path中,如图3.17所示。
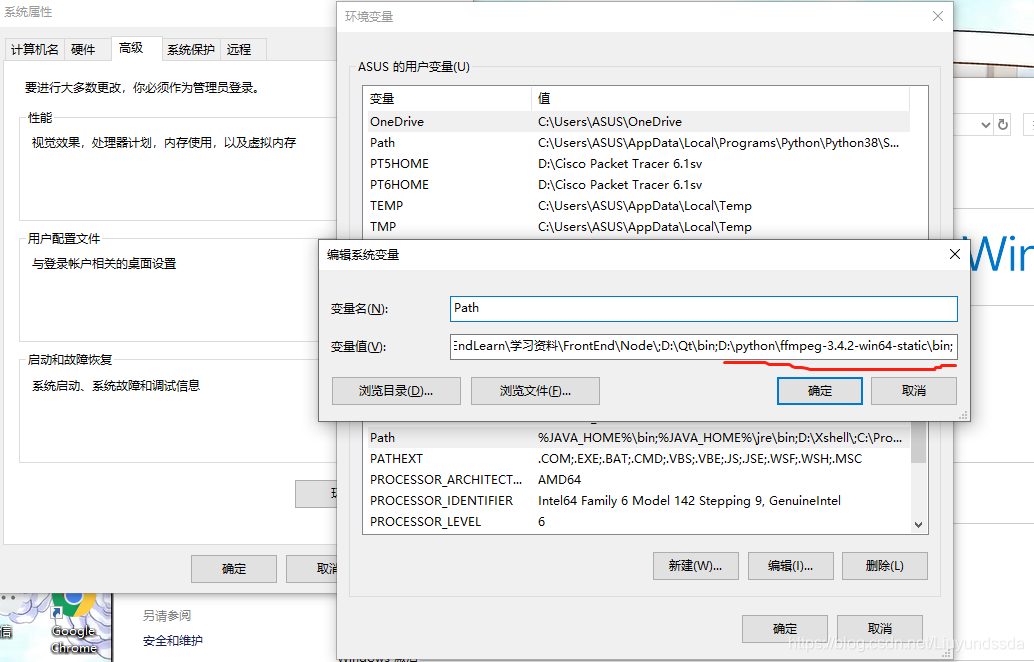
图3.17
Win+R运行cmd指令输入ffmpeg -version查看到如图3.18所示则配置成功。
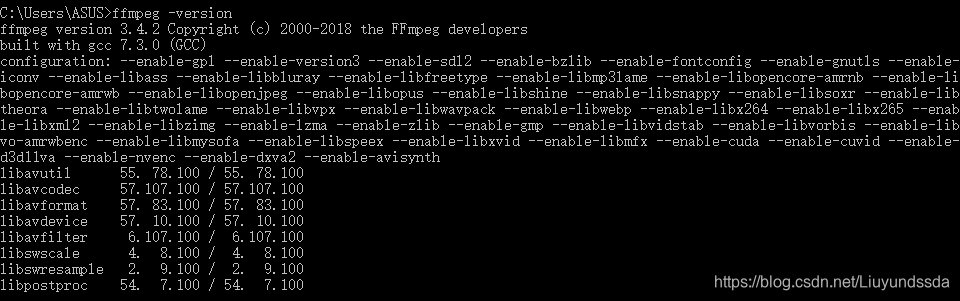
图3.18
编写函数命名为combineVideoAudio,导入库subprocess、os,使用subprocess.call()执行ffmpeg命令,然后使用os.remove()将原本的音频和视频删除,代码如下。
import subprocess
import os
'''
用于合并音频与视频
@param videopath 视频路径
@param audiopath 音频路径
@param outpath 生成合并视频的路径
'''
def combineVideoAudio(videopath,audiopath,outpath):
subprocess.call(("D:/python/ffmpeg-3.4.2-win64-static/bin/ffmpeg -i " + videopath + " -i " + audiopath + " -c copy "+ outpath).encode("utf-8").decode("utf-8"),shell=True)
os.remove(videopath)
os.remove(audiopath)
if __name__ == '__main__':
combineVideoAudio("E:/result/BV1MJ411b7F6-2_Video.mp4","E:/result/BV1MJ411b7F6-2_Audio.mp3","E:/result/BV1MJ411b7F6-2_output.mp4")
合并第4步下载的音频和视频,截取执行结果如图3.19与3.20所示。
图3.19
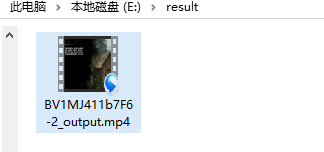
图3.20
能够正常观看视频,如图3.21所示。
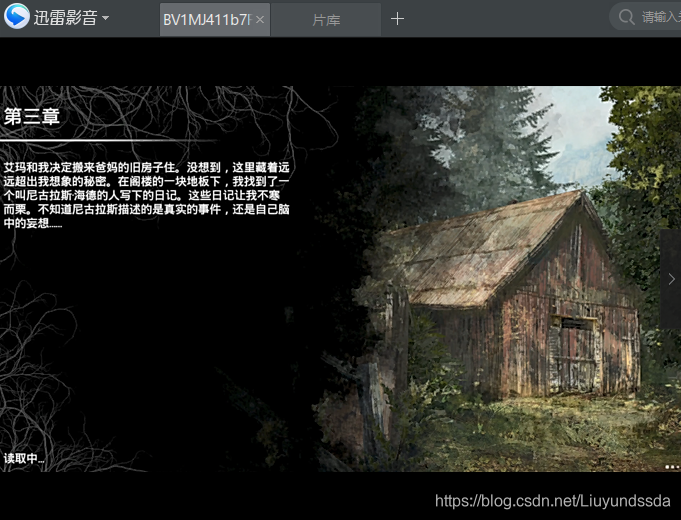
图3.21
6.最终代码
import json
import os
import subprocess
import requests
from lxml import etree
# 防止因https证书问题报错
requests.packages.urllib3.disable_warnings()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36',
'Refer'
'er': 'https://www.bilibili.com/'
}
'''
获取bilibili视频的主要函数
@param url 视频页面url 结构为:url?参数
@param p 视频p数
@param bv 视频bv数
'''
def getBiliBiliVideo(url,p,bv):
session = requests.session()
res = session.get(url=url,headers=headers,verify=False)
_element = etree.HTML(res.content)
# 获取window.__playinfo__的json对象,[20:]表示截取'window.__playinfo__='后面的json字符串
videoPlayInfo = str(_element.xpath('//head/script[3]/text()')[0].encode('utf-8').decode('utf-8'))[20:]
videoJson = json.loads(videoPlayInfo)
# 获取视频链接和音频链接
try:
# 2018年以后的b站视频由.audio和.video组成
videoURL = videoJson['data']['dash']['video'][0]['baseUrl']
audioURl = videoJson['data']['dash']['audio'][0]['baseUrl']
flag=0
except Exception:
# 2018年以前的b站视频音频视频结合在一起,后缀为.flv
videoURL = videoJson['data']['durl'][0]['url']
flag=1
# 指定文件生成目录,如果不存在则创建目录
dirname = ("E:/result").encode("utf-8").decode("utf-8")
if not os.path.exists(dirname):
os.makedirs(dirname)
print('文件夹创建成功!')
# 获取每一集的名称
name = bv + "-" + str(p)
# 下载视频和音频
print('正在下载 "'+name+'" 的视频····')
fileDownload(homeurl=url,url=videoURL, name='E:/result/'+name + '_Video.mp4', session=session)
if flag == 0:
print('正在下载 "'+name+'" 的音频····')
fileDownload(homeurl=url,url=audioURl, name='E:/result/'+name+ '_Audio.mp3', session=session)
print('正在组合 "'+name+'" 的视频和音频····')
combineVideoAudio('E:/result/' + name + '_Video.mp4','E:/result/' + name + '_Audio.mp3','E:/result/' + name + '_output.mp4')
print(' "'+name+'" 下载完成!')
'''
使用session保持会话下载文件
@param homeurl 访问来源
@param url 音频或视频资源的链接
@param name 下载后生成的文件名
@session 用于保持会话
'''
def fileDownload(homeurl,url, name, session=requests.session()):
# 添加请求头键值对,写上 refered:请求来源
headers.update({'Referer': homeurl})
# 发送option请求服务器分配资源
session.options(url=url, headers=headers,verify=False)
# 指定每次下载1M的数据
begin = 0
end = 1024*512 - 1
flag = 0
while True:
# 添加请求头键值对,写上 range:请求字节范围
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
# 获取视频分片
res = session.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
# 响应码不为为416时有数据
begin = end + 1
end = end + 1024*512
else:
headers.update({'Range': str(end + 1) + '-'})
res = session.get(url=url, headers=headers,verify=False)
flag=1
with open(name.encode("utf-8").decode("utf-8"), 'ab') as fp:
fp.write(res.content)
fp.flush()
# data=data+res.content
if flag==1:
fp.close()
break
'''
用于合并音频与视频
@param videopath 视频路径
@param audiopath 音频路径
@param outpath 生成合并视频的路径
'''
def combineVideoAudio(videopath,audiopath,outpath):
subprocess.call(("D:/python/ffmpeg-3.4.2-win64-static/bin/ffmpeg -i " + videopath + " -i " + audiopath + " -c copy "+ outpath).encode("utf-8").decode("utf-8"),shell=True)
os.remove(videopath)
os.remove(audiopath)
if __name__ == '__main__':
# 输入bilibili视频的BV号
bv = input('视频BV号:')
url='https://www.bilibili.com/video/'+bv
# 选择视频从第几p开始到第几p结束
startPart=input('起始P:')
endPart = input('终止P;')
for p in range(int(startPart),int(endPart) + 1):
getBiliBiliVideo(url + '?p=' + str(p),p,bv)
总结
很久之前就有想在PC端直接下载bilibili视频的想法,正好借这次Python的期末作业看能不能做出一个爬虫下载视频,通过百度找了很多的资料并借鉴了一些博客的经验,发现可行性很高,所以就准备以这个为题。利用chorme浏览器的开发者工具,从网页文本中找到视频资源的链接,再从一条条请求种找到请求视频的方式,慢慢地摸清了bilibili分p加载视频的机制之后,就开始编码,中间学习了如何使用python的各种库去请求网页、解析网页文本、下载音频与视频、合并音频与视频。在合并音频与视频这个问题上卡了挺久,最后试出来的方案是使用subprocess.call()来执行ffmpeg命令可以获得完整视频。
目前实现的爬取视频功能已经可以满足我离线观看视频,不用借助手机就可下载到视频素材的需求。当然,这个程序还存在一些可以后续添加的功能,比如输入多个BV号再逐个下载;实现循环输入,下载完一个视频后继续输入号,继续下载;显示弹幕等,这些功能根据以后的需求再进行添加。