对爬虫还挺有兴趣的,但是一直没有尝试过,今天看了几篇写得非常好的博客,学到了一丢丢,自己也写了个简单的爬虫娱乐娱乐。
1.分析需求
需求:
爬取b站up主王老菊所有视频投稿的编号,标题,播放数量以及评论数量。
分析:
1.先要进入b站,到这位up主的个人主页:

2.按f12进入控制台f5刷新,如图所示找到需要的信息:

3.图中的xhr文件就包含了我们需要的信息,挨个打开,直到找到需要的信息:

4.把这个文件在浏览器里打开就能找到我们需要的url:

如图:

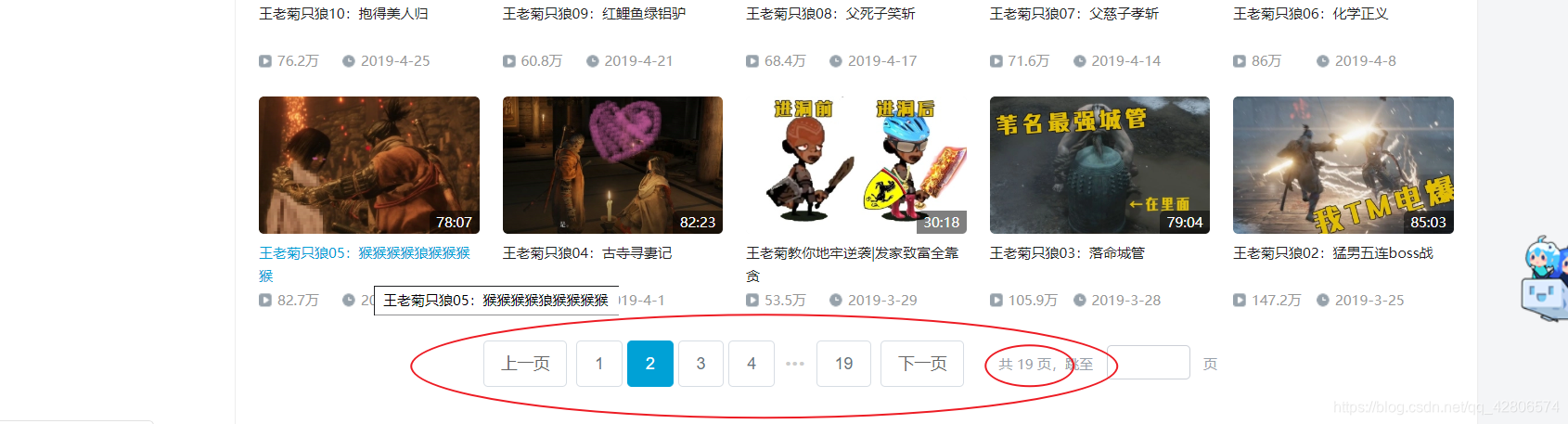
5.这里有一个问题,老菊的视频投稿一共有19页,而每一页的url其实是不一样的。
但是很容易就能找到规律,在请求访问时,可以用一个循环将所有的url都访问到。
2.环境配置
1.保证网络连接
2.pycharm中安装导入需要的模块
这里我用的是requests第三方模块,安装的时候可能会出现超时或者请求更新pip,解决的办法在我另一篇博客里有。
打开pycharm ,打开设置,点击 + 号,搜索 requests 然后安装。如图:

安装完成之后就可以开始了。
(1)首先导入需要用到的模块
import json
import requests(2)有些网站会禁止爬取,因此这里采用一个非常基础的方法,模拟浏览器进行访问
headers = {
'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}这里的内容获取方法如图:

(3)因为老菊投稿一共有19页,所以采用循环的方法:
for i in range(1,20):
url = 'https://api.bilibili.com/x/space/arc/search?mid=423895&pn=%s&ps=25&jsonp=jsonp'%(i)
3.完整代码
#导入模块
import json
import requests
#循环19次,将每一页的数据都抓取到
for i in range(1,20):
#模拟浏览器
headers = {
'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
#包含待爬取信息的url
url = 'https://api.bilibili.com/x/space/arc/search?mid=423895&pn=%s&ps=25&jsonp=jsonp'%(i)
#访问url
r = requests.get(url,headers)
#将爬取道德json格式的数据转化为字典
text = json.loads(r.text)
#取出嵌套字典里我们想要的部分
#这里的字典嵌套在控制台里其实看的很清楚,我在上面的截图里圈了出来
res = text['data']['list']['vlist']
for item in res:
#以列表的形式取出对我们有用的数据
list = ['av: '+str(item['aid']),' 视频标题: '+item['title'],' 播放量: '+str(item['play']),' 评论条数: '+str(item['video_review'])]
#转化为字符串格式
result = ''.join(list)
#写进文件里
with open('wlg.txt','a+',encoding="utf-8") as f:
f.write(result+'\n')
4.运行结果


