01 特征归一化
为了消除数据特征之间的量纲影响,我们需要对特征进行归一化处理,使得不同指标之间具有可比性。例如,分析一个人的身高和体重对健康的影响,如果使用米(m)和千克(kg)作为单位,那么身高特征会在1.6~1.8m的数值范围内,体重特征会在50~100kg的范围内,分析出来的结果显然会倾向于数值差别比较大的体重特征。想要得到更为准确的结果,就需要进行特征归一化(Normalization)处理,使各指标处于同一数值量级,以便进行分析。
知识点
特征归一化
问题 为什么需要对数值类型的特征做归一化?
分析与解答
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下两种。
(1)线性函数归一化(Min-Max Scaling)。它对原始数据进行线性变换,使结果映射到[0, 1]的范围,实现对原始数据的等比缩放。归一化公式如下:
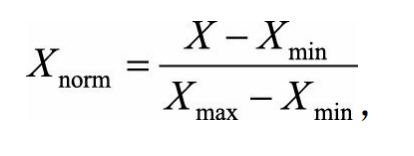
其中X为原始数据,Xmax、Xmin分别为数据最大值和最小值。
(2)零均值归一化(Z-Score Normalization)。它会将原始数据映射到均值为0、标准差为1的分布上。具体来说,假设原始特征的均值为μ、标准差为σ,那么归一化公式定义为

为什么需要对数值型特征做归一化呢?我们不妨借助随机梯度下降的实例来说明归一化的重要性。假设有两种数值型特征,x1的取值范围为 [0, 10],x2的取值范围为[0, 3],于是可以构造一个目标函数符合图1.1(a)中的等值图。在学习速率相同的情况下,x1的更新速度会大于x2,需要较多的迭代才能找到最优解。如果将x1和x2归一化到相同的数值区间后,优化目标的等值图会变成图1.1(b)中的圆形,x1和x2的更新速度变得更为一致,容易更快地通过梯度下降找到最优解。

当然,数据归一化并不是万能的。在实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树模型则并不适用,以C4.5为例,决策树在进行节点分裂时主要依据数据集D关于特征x的信息增益比(详见第3章第3节),而信息增益比跟特征是否经过归一化是无关的,因为归一化并不会改变样本在特征x上的信息增益。
另外博主收藏这些年来看过或者听过的一些不错的常用的上千本书籍,没准你想找的书就在这里呢,包含了互联网行业大多数书籍和面试经验题目等等。有人工智能系列(常用深度学习框架TensorFlow、pytorch、keras。NLP、机器学习,深度学习等等),大数据系列(Spark,Hadoop,Scala,kafka等),程序员必修系列(C、C++、java、数据结构、linux,设计模式、数据库等等)以下是部分截图
更多文章见本原创微信公众号「五角钱的程序员」,我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活。关注回复【电子书】即可领取哦。

给大家推荐一个Github,上面非常非常多的干货:https://github.com/XiangLinPro/IT_book
Make up your mind to act decidedly and take the consequences. No good is ever done in this world by hesitation.
下定决心,果断行动,并承担后果。在这世界上犹豫不决成就不了任何事。