本文重点
归一化是数据预处理的一种常用方法,它将不同尺度的特征转化为统一的尺度,使得数据在同一量纲下进行比较和分析。对于数值类型的特征,归一化的目的是消除不同特征之间的量纲差异,使得模型能够更好地学习特征之间的关系,提高模型的性能。
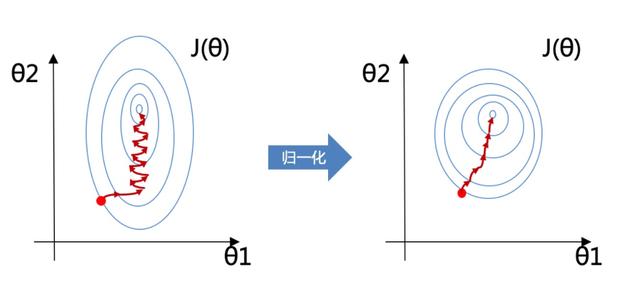
对数值类型特征进行归一化的好处
避免量纲混淆
不同特征的量纲不同,即使数值相同,也可能因为量纲不同而导致模型对特征的解释出现偏差。例如,身高和体重两个特征,身高的单位是cm,体重的单位是kg,如果不进行归一化,模型可能会更多地关注体重这个数值较大的特征,而忽略了身高这个数值较小的特征。
改善模型收敛速度
在使用梯度下降等优化算法时,特征值的量级差异会导致优化过程的不稳定性,使得模型收敛速度变慢。通过归一化,可以将特征值缩放到一个较小的范围内,提高优化算法的稳定性和收敛速度。
提高模型性能
对于很多机器学习算法,如KNN、SVM、神经网络等,特征的尺度差异会导致模型对某些特征更加敏感,从而影响模型的性能。通过归一化可以消除特征之间的尺度差异,使得模型能够更加平衡地学习各个特征的权重,提高模型的性能。
避免异常值的影响
在一些数据集中,可能存在一些异常值,这些异常值的存在会影响模型的训练效果。通过归一化可以将异常值的影响降低,使得模型更加稳定。