标题由于进行数据抽取时,必须顺便清洗数据,所以实现一个简单的抽取式摘要生成算法,来进行摘要的生成,这里我用java实现了TextRank算法。
TextRank算法思想
与PageRank一样,textrank算法给每一个句子一个权重,然后根据一个句子与其他句子的相似程度,将自己的权重按相似程度分配给其他句子,为了避免某一个句子的权重变为0,则需要加一个调和参数,进行平滑。
具体的公式为:
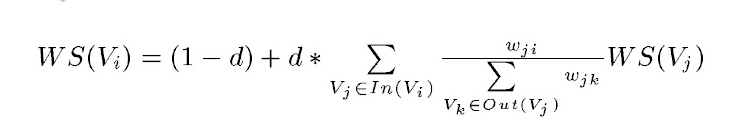
等式左边表示一个句子的权重(WS是weight_sum的缩写),右侧的求和表示每个相邻句子对本句子的贡献程度。与提取关键字的时候不同,一般认为全部句子都是相邻的,不再提取窗口。
求和的分母wji表示两个句子的相似程度,分母又是一个weight_sum,而WS(Vj)代表上次迭代j的权重。整个公式是一个迭代的过程。
相似程度的计算BM25算法
BM25算法常用来做搜索相关性的评分,对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相 对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
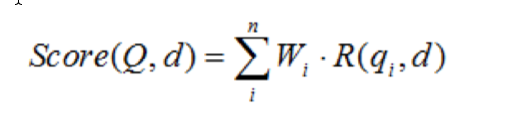
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重; R(qi,d)表示语素qi与文档d的相关性得分。
下面用IDF来定义权重:
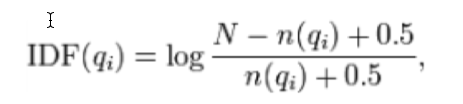
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。

通过计算即可得到一句查询与一个文本的相似程度
BM25算法的实现
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
public class BM25 {
/**
* 文档句子的个数
*/
int D;
/**
* 文档句子的平均长度
*/
double avgdl;
/**
* 拆分为[句子[单词]]形式的文档
*/
List<List<String>> docs;
/**
* 文档中每个句子中的每个词与词频
*/
Map<String, Integer>[] f;
/**
* 文档中全部词语与出现在几个句子中
*/
Map<String, Integer> df;
/**
* IDF
*/
Map<String, Double> idf;
/**
* 调节因子
*/
final static float k1 = 1.5f;
/**
* 调节因子
*/
final static float b = 0.75f;
public BM25(List<List<String>> docs)
{
this.docs = docs;
D = docs.size();
//计算文档中句子的平均长度 总词数/句子总数
for (List<String> sentence : docs)
{
avgdl += sentence.size();
}
avgdl /= D;
f = new Map[D];
df = new TreeMap<String, Integer>();
idf = new TreeMap<String, Double>();
init();
}
/**
* 在构造时初始化自己的所有参数
*
*/
private void init()
{
int index = 0;//index表示现在是文档中的第几句话
for (List<String> sentence : docs)
{
//对于每个句子的分词结果 计算 分词在这个句子中出现的频率 为tf 存成String int的映射形式
Map<String, Integer> tf = new TreeMap<String, Integer>();
for (String word : sentence)
{
//计算每个值出现的频数 作为tf
Integer freq = tf.get(word);
freq = (freq == null ? 0 : freq) + 1;
tf.put(word, freq);
}
f[index] = tf;//存储每句话对应的tf值Map
//根据tf值算df值 计算每个词出现在几个句子中
for (Map.Entry<String, Integer> entry : tf.entrySet())
{
String word = entry.getKey();
Integer freq = df.get(word);
freq = (freq == null ? 0 : freq) + 1;
df.put(word, freq);
}
++index;
}
//根据df计算idf 公司为log(D - freq + 0.5) - Math.log(freq + 0.5) D为文档中句子个数 0.5为平滑项
for (Map.Entry<String, Integer> entry : df.entrySet())
{
//计算逆文档频率 idf
String word = entry.getKey();
Integer freq = entry.getValue();
idf.put(word, Math.log(D - freq + 0.5) - Math.log(freq + 0.5));
}
}
/**
* 计算相似度 最终得到一个句子 与对应index句子的相关性得分
* @param sentence
* @param index
* @return
*/
public double sim(List<String> sentence, int index)
{
double score = 0;
//对于一句话中的每一个单词 计算这个单词 与其他句子的相关性得分 这个得分用BM25计算出
for (String word : sentence)
{
if (!f[index].containsKey(word)) {
continue;
}
int d = docs.get(index).size();//index对应句子的词的个数
Integer wf = f[index].get(word);//在index对应句子中 词word出现的次数
//,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得
//分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
score += (idf.get(word) * wf * (k1 + 1)
/ (wf + k1 * (1 - b + b * d
/ avgdl)));
}
//最终得到一个句子 与对应index句子的相关性得分
return score;
}
/**
* 计算整体的相似度 计算每一个句子与其他所有句子的相似度
* @param sentence
* @return
*/
public double[] simAll(List<String> sentence)
{
double[] scores = new double[D];
for (int i = 0; i < D; ++i)
{
scores[i] = sim(sentence, i);
}
return scores;
}
}
(1)我们将一段文字,首先通过标点切分成句子,然后将句子分词,就可以得到[句子[单词]]形式的文档docs,
然后对于句子中的每一个次计算tf值和idf值(tf值为某个分词在某句话中出现的频率 df为每个词出现在几个句子中 idf为df计算得出的逆文档频率)
(2)我们计算两句话之间的相似程度,得到两个句子的相关性得分,使用BM25算法。
(3)最终我们计算一个句子与其他所有句子的相似程度。
实现TextRank算法
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.dictionary.stopword.CoreStopWordDictionary;
import com.hankcs.hanlp.seg.common.Term;
import java.util.*;
/**
* TextRank 自动摘要
*/
public class TextRankSummary {
/**
* 阻尼系数,一般取值为0.85
*/
final double d = 0.85f;
/**
* 最大迭代次数
*/
final int maxIter = 200;
final double min_diff = 0.001f;
/**
* 文档句子的个数
*/
int docSentenceCount;
/**
* 拆分为[句子[单词]]形式的文档
*/
List<List<String>> docs;
/**
* 排序后的最终结果 score <-> index
* 使用treemap 因为treemap自动按key排序
*/
TreeMap<Double, Integer> top;
/**
* 句子和其他句子的相关程度
*/
double[][] weight;
/**
* 该句子和其他句子相关程度之和
*/
double[] weightSum;
/**
* 迭代之后收敛的权重
*/
double[] vertex;
/**
* BM25相似度
*/
BM25 bm25;
public TextRankSummary(List<List<String>> docs)
{
this.docs = docs;
bm25 = new BM25(docs);
docSentenceCount = docs.size();
// 句子和其他句子的相关程度
weight = new double[docSentenceCount][docSentenceCount];
weightSum = new double[docSentenceCount];
//该句子和其他句子相关程度之和
vertex = new double[docSentenceCount];
//选出排名靠前的句子
top = new TreeMap<Double, Integer>(Collections.reverseOrder());
solve();
}
/**
* 构造矩阵计算最相似的内容
*/
private void solve()
{
int cnt = 0;
//对于文档中的每一句话 都要计算他与其他每一句话的相似程度 以及他与其他所有句子的总相似程度
for (List<String> sentence : docs)
{
//对于文档中的每一个句子 计算它与文档中其他所有句子的相似程度
double[] scores = bm25.simAll(sentence);
//将计算结果存储在矩阵中
weight[cnt] = scores;
// 减掉自己,自己跟自己肯定最相似
weightSum[cnt] = sum(scores) - scores[cnt];
//所有句子权重初始化都为1
vertex[cnt] = 1.0;
++cnt;
}
//开始使用textrank算法进行迭代 200轮
for (int iter = 0; iter < maxIter; ++iter)
{
double[] m = new double[docSentenceCount];
double maxDiff = 0;
for (int i = 0; i < docSentenceCount; ++i)
{
m[i] = 1 - d;
for (int j = 0; j < docSentenceCount; ++j)
{
if (j == i || weightSum[j] == 0) {
continue;
}
m[i] += (d * weight[j][i] / weightSum[j] * vertex[j]);
}
double diff = Math.abs(m[i] - vertex[i]);
if (diff > maxDiff)
{
maxDiff = diff;
}
}
vertex = m;
if (maxDiff <= min_diff) {
break;
}
}
// 然后进行排序 输出权重最大的那个
for (int i = 0; i < docSentenceCount; ++i)
{
top.put(vertex[i], i);
}
}
/**
* 获取前几个关键句子
* @param size 要几个
* @return 关键句子的下标
*/
public int[] getTopSentence(int size)
{
Collection<Integer> values = top.values();
size = Math.min(size, values.size());
int[] indexArray = new int[size];
Iterator<Integer> it = values.iterator();
for (int i = 0; i < size; ++i)
{
indexArray[i] = it.next();
}
return indexArray;
}
/**
* 简单的求和
* @param array
* @return
*/
private static double sum(double[] array)
{
double total = 0;
for (double v : array)
{
total += v;
}
return total;
}
/**
* 将文章分割为句子 分割依据为标点符号
* @param document
* @return
*/
static List<String> spiltSentence(String document)
{
List<String> sentences = new ArrayList<String>();
if (document == null) {
return sentences;
}
String regex1 = "[\r\n]";
String regex2 = "[,,。::“”??!!;;]";
for (String line : document.split(regex1)) {
line = line.trim();
if (line.length() == 0) {continue;}
for (String sent : line.split(regex2))
{
sent = sent.trim();
if (sent.length() == 0) {
continue;
}
sentences.add(sent);
}
}
return sentences;
}
/**
* 是否应当将这个term纳入计算,词性属于名词、动词、副词、形容词
* @param term
* @return 是否应当
*/
public static boolean shouldInclude(Term term) {
return CoreStopWordDictionary.shouldInclude(term);
}
/**
* 一句话调用接口
* @param document 目标文档
* @param size 需要的关键句的个数
* @return 关键句列表
*/
public static String getTopSentenceList(String document, int size) {
List<String> sentenceList = spiltSentence(document);
//存储句子分词后的结果
List<List<String>> docs = new ArrayList<List<String>>();
for (String sentence : sentenceList) {
//利用HanLP的接口将句子进行分词
List<Term> termList = HanLP.segment(sentence);
List<String> wordList = new LinkedList<String>();
//是否应当将这个term纳入计算,词性属于名词、动词、副词、形容词
for (Term term : termList) {
if (shouldInclude(term)) {
wordList.add(term.word);
}
}
docs.add(wordList);
}
TextRankSummary textRankSummary = new TextRankSummary(docs);
//然后获取排名最高的几个句子
int[] topSentence = textRankSummary.getTopSentence(size);
List<String> resultList = new LinkedList<String>();
for (int i : topSentence) {
resultList.add(sentenceList.get(i));
}
String result = String.join("-",resultList);
return result;
}
}
(1)首先,输入目标文本和需要生成的摘要个数,然后我们现将文本,通过标点符号切分成句子,然后对每句话进行分词,这里分词使用了HanLP库(https://github.com/hankcs/hanlp),最后得到文档docs。
(2)然后通过docs使用BM25算法,计算每句话相互之间的文本相似度
(3)有了每句话的相似度之后,就可以给每个句子一个初始的权重,使用textrank算法,结合句子之间的相似度进行迭代,迭代200轮之后,停止迭代,输出权重最高的句子作为这篇文本的摘要。
(与pagerank算法思想相同,将自己的权重通过文本相似度的不同按比例分给不同的其他文本,自己也获得其他文本传来的权重,然后逐渐收敛)
最终的效果为


他只是抽取了几句,在文本中权重比较大的句子,语义之间没有连贯性,效果很不好。
明天准备尝试以下深度学习的方法来进行摘要的生成。