前言
当我们想对股票数据用python爬取的时候,总是找不到好的获取数据,有一些相关的包,tushare等,但是它有限股票数据就没有,比如我最近在爬的SZ159915,在tushare库中,就爬不到。
找接口
以下以雪球为例:
打开雪球:
搜索六位代码,如159915:
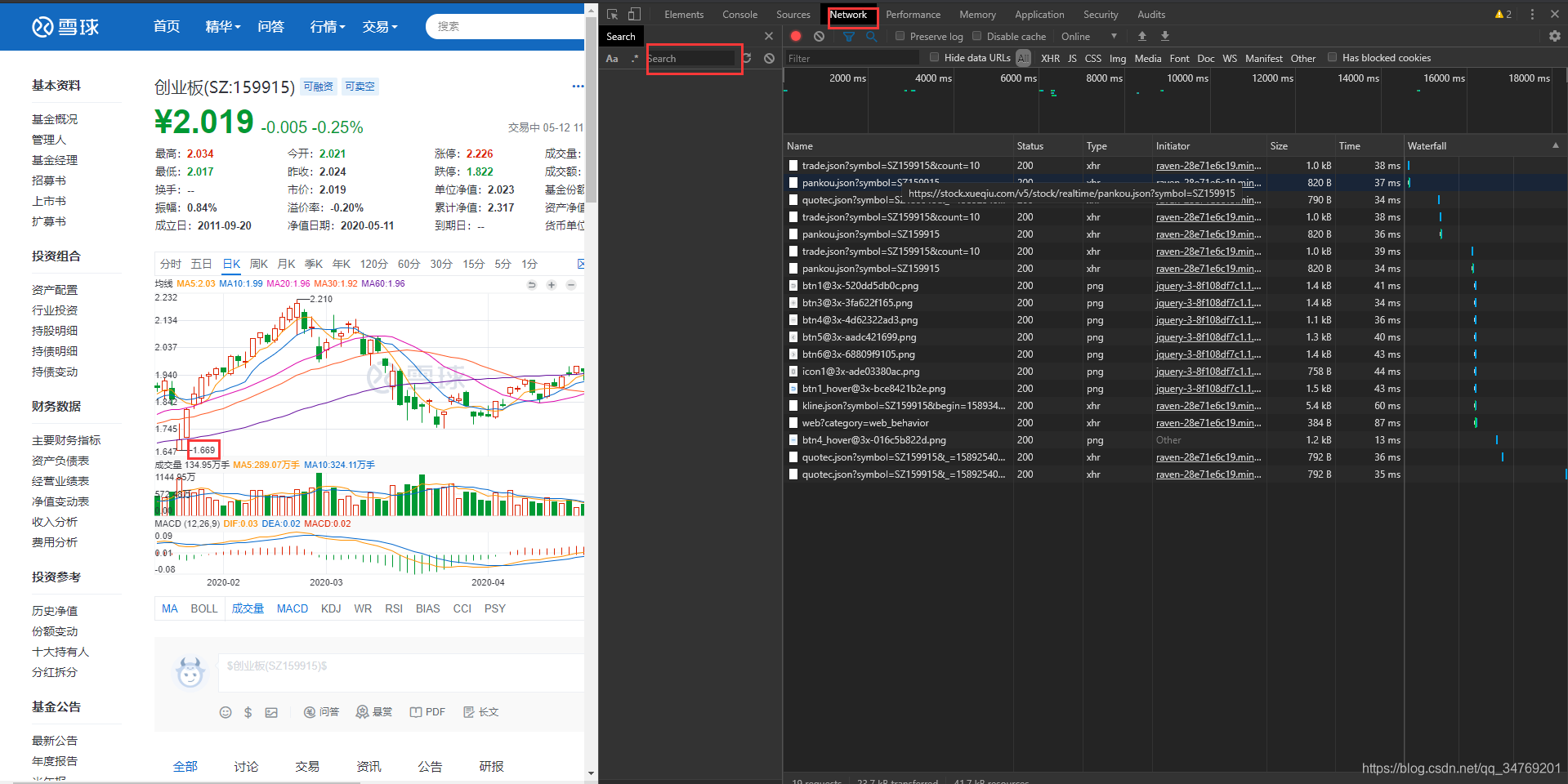
开发者模式,打开Network页面,搜索前期最高点或者最低点,如1.669
单击第一个
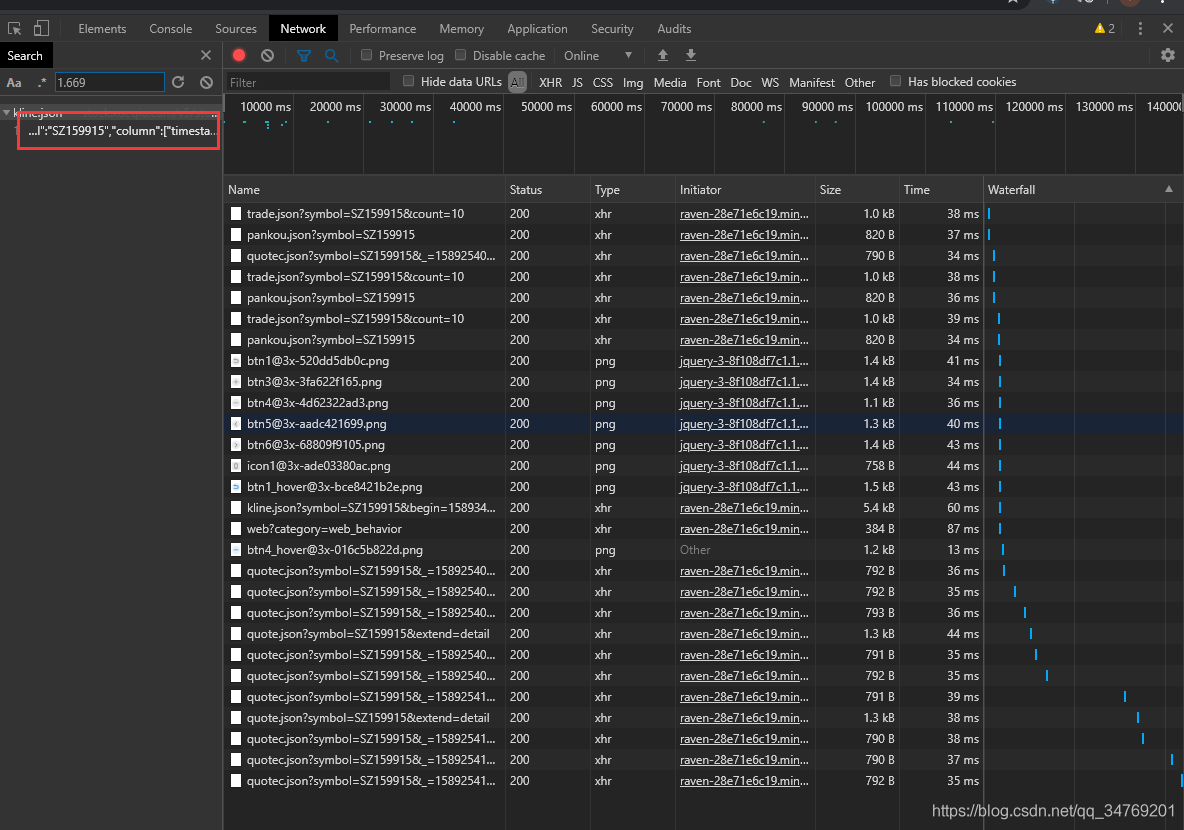
发现是这行数据:
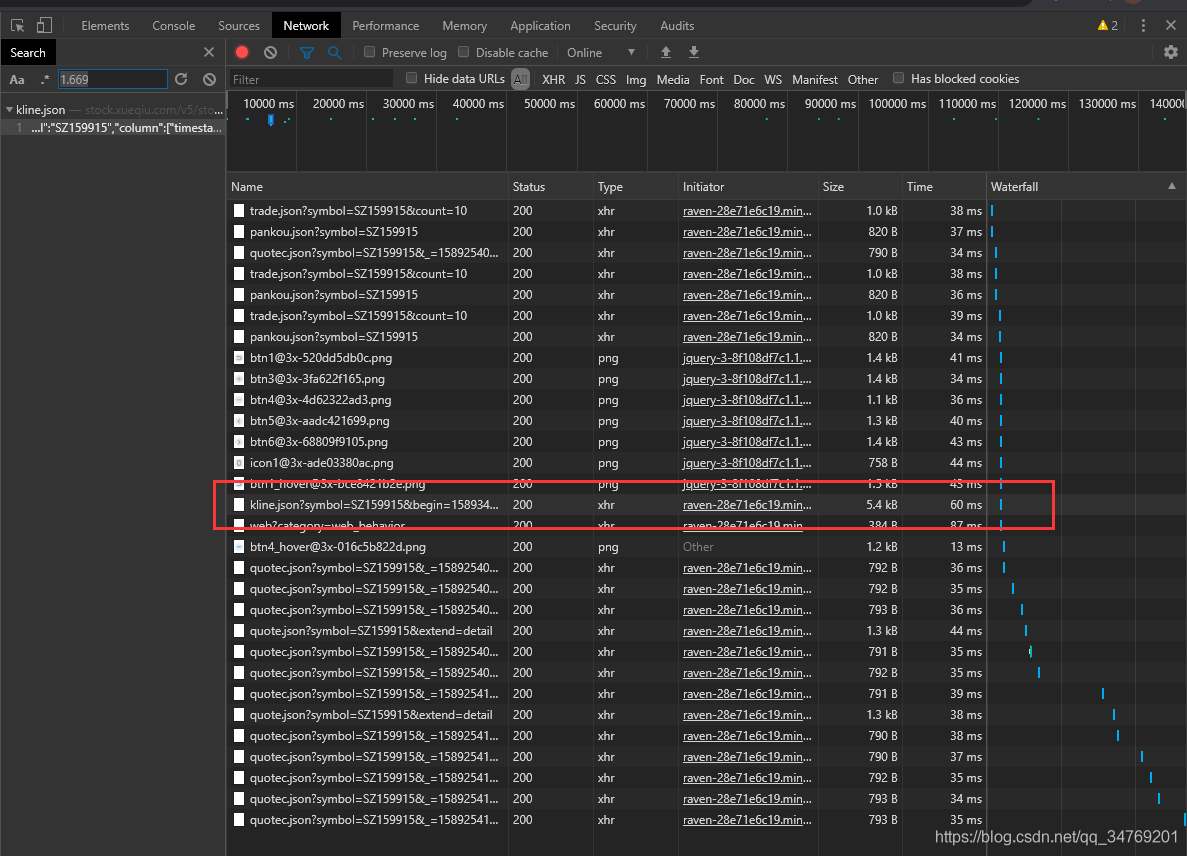
单击得到这个页面:
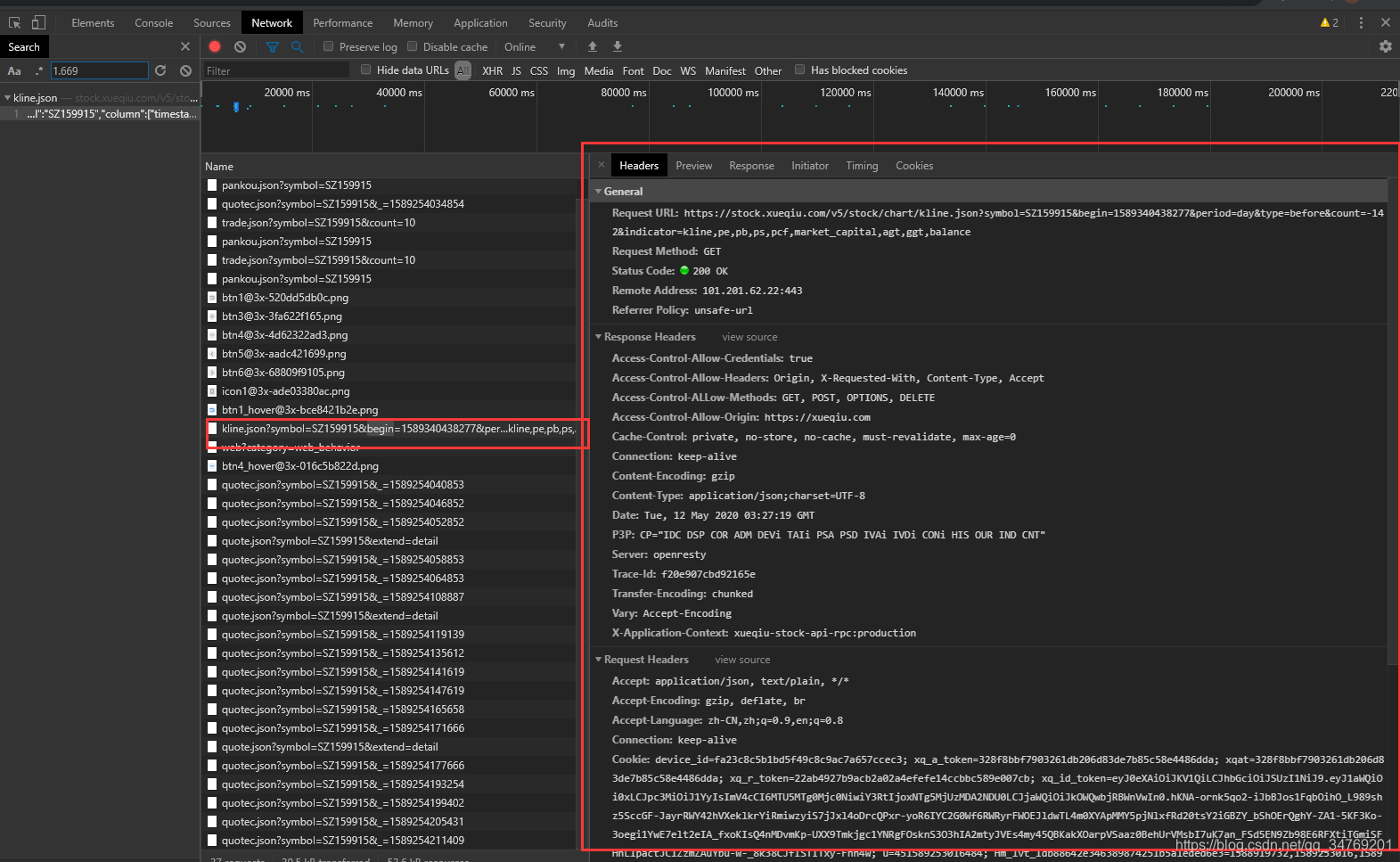
把General项的网址用浏览器打开看看:

接口参数意义:
https://stock.xueqiu.com/v5/stock/chart/kline.json?symbol=SZ159915&begin=1589340438277&period=day&type=before&count=-142&indicator=kline,pe,pb,ps,pcf,market_capital,agt,ggt,balance
| 参数 | 意义 |
|---|---|
| begin | 起始日 |
| period | K线单位选择,日k,月k等 |
| type | 不知道什么意义 |
| count | 数据个数 |
| indicator | 其他指标参数 |
接口含义:从begin那天开始,向前记录count个交易日,并且得到indicator的指标。
图中一些变量的意义
| 变量 | 意义 |
|---|---|
| timestamp | 时间戳(以ms计)。 |
| volume | 成交量 |
| open | 开盘价 |
| high | 最高价 |
| low | 收盘价 |
| close | 收盘价 |
其他的一些参数自己可以对比K线查看。
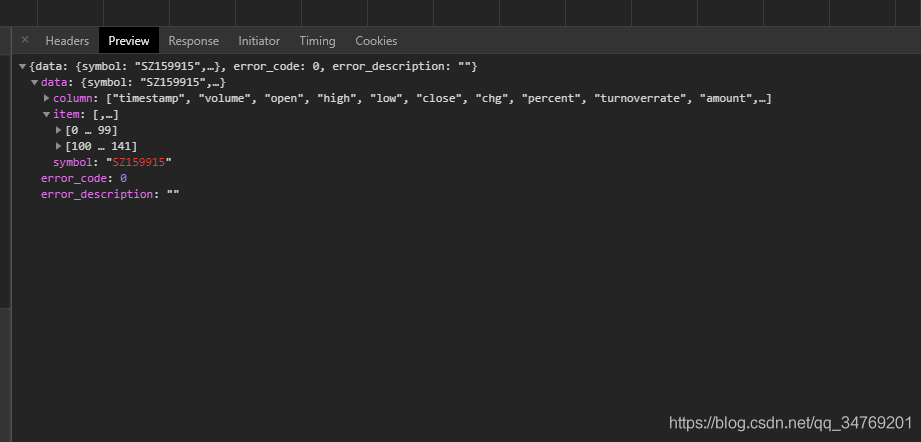
在Preview页面可以更简单查看到:
使用接口
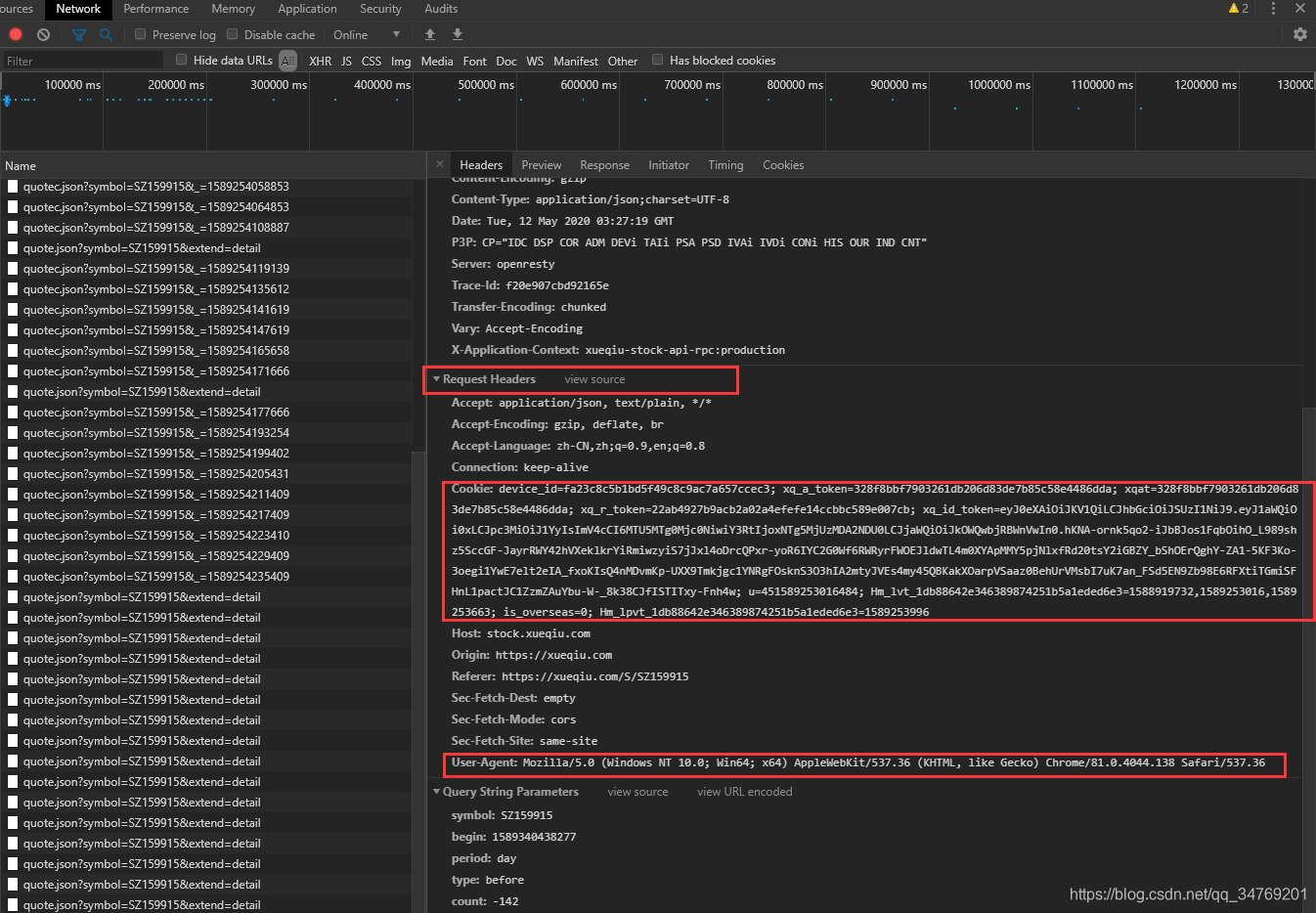
写代码的时候需要用到Request Hearders项下面的Cookie和User-Agent项
接下来可以写代码爬取了,代码直接贴上了,使用requests库。
import requests
import json
import pandas as pd
import time
number = 2000 # 需要获取的交易日的个数
begin = int(time.time() * 1000)
url = 'https://stock.xueqiu.com/v5/stock/chart/kline.json?symbol=SZ159915&begin=' + str(
begin) + '&period=day&type=before&count=-' + str(number)
# Cookie参数根据每个人的设备来变动
headers = {'User-Agent': 'Mozilla/5.0',
'Cookie': 'xq_a_token=48575b79f8efa6d34166cc7bdc5abb09fd83ce63; xqat=48575b79f8efa6d34166cc7bdc5abb09fd83ce63; xq_r_token=7dcc6339975b01fbc2c14240ce55a3a20bdb7873; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4OTY4MjczMCwiY3RtIjoxNTg4OTE5Njc4OTk4LCJjaWQiOiJkOWQwbjRBWnVwIn0.l6yOJc-qTWMNU8g6wXjew0X7TmWbi82cuGiYkVvWGnUoxYSGWIx3DtfIki0etjSbN8mG0r1Gwd_q-PGo6EHL4h-SreHzt7tnteLtmnFrJ5hdyNh1g_x2u4XMvTX-pIEZmVInhBIM_BGVFerYXHuIJ6lm1G-EPR4RlVG2PQ7PTvvsz9-VycQJVZuF1zguF936WiSbPTBmhG0wcXUdfziFC1RPrXgFNTrwNXqaIiWfT5WbRWckm8aFNM3krCGCaES494Jco0FBM3eB5GJlGeB5xS1if_de7T6__PSTCmzMHokG133gRqt4FvYHu9kIQg74CdGw8u7EDWSigw-kASVAzg; u=851588919733219; is_overseas=0; Hm_lvt_1db88642e346389874251b5a1eded6e3=1588919732; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1588919732; device_id=fa23c8c5b1bd5f49c8c9ac7a657ccec3'}
r = requests.get(url, headers=headers) # 爬取数据
text = r.text # 获得文本
data = json.loads(text) # str转成json
item = data['data']['item'] # 从全部数据中取出item项
df = pd.DataFrame(item, columns=["timestamp", "volume", "open", "high", "low", "close", "chg", "percent", "turnoverrate", "amount", "volume_post", "amount_post"]) # list转为DataFrame数据格式,更方便以后的处理
print(df)
输出的数据如下:
timestamp volume open ... amount volume_post amount_post
0 1329408000000 67987778 0.726 ... NaN None None
1 1329667200000 39183956 0.725 ... NaN None None
2 1329753600000 77306937 0.721 ... NaN None None
3 1329840000000 193157652 0.738 ... NaN None None
4 1329926400000 124234294 0.765 ... NaN None None
... ... ... ... ... ... ... ...
1995 1588089600000 356095691 1.943 ... 696005741.0 None None
1996 1588176000000 411736129 1.964 ... 817442890.0 None None
1997 1588694400000 367767579 1.980 ... 737917205.0 None None
1998 1588780800000 265935124 2.030 ... 538456242.0 None None
1999 1588867200000 304340396 2.035 ... 622569015.0 None None
[2000 rows x 12 columns]
至此,爬取工作完成,后面如何使用根据个人需求而定。