文章目录
零、读前说明
- 本文中没有涉及到很多的相关理论知识,也没有做深入的了解,所以,您如果是想要系统的学习、想要多学习关于理论的知识等,那么本文可能并不合适您。
- 本文中所有设计的代码均通过测试,并且在功能性方面均实现应有的功能。
- 设计的代码并非全部公开,部分无关紧要代码并没有贴出来。
- 如果你也对此感兴趣、也想测试源码的话,可以私聊我,非常欢迎一起探讨学习。
- 由于时间、水平、精力有限,文中难免会出现不准确、甚至错误的地方,也很欢迎大佬看见的话批评指正。
- 嘻嘻。。。。 。。。。。。。。收!
一、线性表定义
- 线性表(List)是零个或多个数据元素的集合
- 线性表中的数据元素之间是有顺序的
- 线性表中的数据元素个数是有限的
- 线性表中的数据元素的类型必须相同
线性表在程序中表现为一种特殊的数据类型
线性表的操作在程序中的表现为一组函数。
二、线性表性质
- a0为线性表的第一个元素,只有一个后继。
- an为线性表的最后一个元素,只有一个前驱
- 除a0和an外的其它元素ai,既有前驱,又有后继
- 线性表能够逐项访问和顺序存取
三、线性表的顺序存储结构
3.1、基本概念
线性表的顺序存储结构,指的是用一段地址连续的存储单元(数组)依次存储线性表的数据元素。
线性表的存储结构示意图。

3.2、设计与实现
插入元素算法
判断线性表是否合法
判断插入位置是否合法
判断线性表是否已满
把最后一个元索到插入位置的元素后移一个位置
将新元素插入
线性表长度加1
获取元素操作
判断线性表是否合法
判断位置是否合法
直接通过数组下标的方式获取元素
删除元素算法
判断线性表是否合法
判断删除位置是否合法
判断线性表是否已空
将要删除元素取出缓存
将删除位置后的元素分别向前移动一个位置
线性表长度减1
……
四、线性表的操作
创建线性表 List_create
销毁线性表 List_destory
清空线性表 List_clear
获取线性表的长度 List_length
获取线性表的容量 List_capacity
获取线性表中某个位置的元素 List_get
将元素插入线性表 List_insert
将元素从线性表中删除 List_delete
判断线性表已空 List_isEmpty
判断线性表已满 List_isFull
五、原理代码实现
本代码只是说明原理,所以业务数据结构与顺序表的结构绑定一起,在使用过程中,只要业务节点改变,则整个代码都需要修改,所以,将代码结构分成顺序表相关部分、头文件声明部分、调用测试部分。
本部分代码为测试方便,集成了cmake相关的文件。
详细说明请跳转:六、通用代码实现(顺序表与业务节点分离)
5.1、代码结构树
seqList/
├── CMakeLists.txt
├── README.md
├── build
└── src
│ ├── list.c
│ └── list.h
└── test.c
2 directory, 6 files
5.2、声明头文件
代码如下:
#ifndef __LIST_H__
#define __LIST_H__
#include <stdio.h>
#include <stdlib.h>
#define N 32
//数据类型
typedef int data_t;
//顺序表类型
typedef struct
{
data_t a[N]; //存储数据
int last; //最后一个元素的下标
} sqlist_t; //类型名,没有空间
//开辟空的顺序表
sqlist_t *sqlist_create();
//为满1 不满0
int sqlist_is_full(sqlist_t *p);
//插入数据
int sqlist_insert(sqlist_t *p, data_t value);
//为空1 不空0
int sqlist_is_empty(sqlist_t *p);
//删除最后一个数据
int sqlist_delete(sqlist_t *p);
//将指定的旧数据改成新的数据
int sqlist_change(sqlist_t *p, data_t old, data_t new);
//根据位置查找数据(return)
data_t sqlist_search(sqlist_t *p, int pos);
//按位置插入
int sqlist_insert_pos(sqlist_t *p, int pos, data_t value);
//按位置删除
int sqlist_delete_pos(sqlist_t *p, int pos);
//删除重复
int sqlist_delete_repeat(sqlist_t *p);
//遍历顺序表
int sqlist_show(sqlist_t *p);
#endif
5.3、顺序表的相关代码
代码如下:
#include "list.h"
#include <stdio.h>
#include <stdlib.h>
//开辟空的顺序表
sqlist_t *sqlist_create()
{
sqlist_t *p = (sqlist_t *)malloc(sizeof(sqlist_t)); //开辟顺序表的空间
//p:空间首地址
p->last = -1;
return p;
}
//为满1 不满0
int sqlist_is_full(sqlist_t *p)
{
return p->last == N - 1 ? 1 : 0;
}
//插入数据
int sqlist_insert(sqlist_t *p, data_t value)
{
if (sqlist_is_full(p) == 1)
{
printf("full\n");
return -1; //异常返回-1
}
p->last++;
p->a[p->last] = value;
return 0; //正常返回0
}
//为空1 不空0
int sqlist_is_empty(sqlist_t *p)
{
return p->last == -1 ? 1 : 0;
}
//删除最后一个数据
int sqlist_delete(sqlist_t *p)
{
if (sqlist_is_empty(p) == 1)
{
printf("empty\n");
return -1;
}
p->last--;
return 0;
}
//将指定的旧数据改成新的数据
int sqlist_change(sqlist_t *p, data_t old, data_t new)
{
int i;
for (i = 0; i <= p->last; i++)
{
if (p->a[i] == old)
{
p->a[i] = new;
}
}
return 0;
}
//根据位置查找数据(return)
data_t sqlist_search(sqlist_t *p, int pos)
{
if (pos < 0 || pos > p->last)
{
printf("pos error\n");
return (data_t)-1;
}
return p->a[pos];
}
//按位置插入
int sqlist_insert_pos(sqlist_t *p, int pos, data_t value)
{
//为满
if (sqlist_is_full(p))
{
printf("full");
return -1;
}
//判断pos的取值区间
if (pos < 0 || pos > p->last + 1)
{
printf("pos error\n");
return -1;
}
//数据往后移动
int i;
for (i = p->last; i >= pos; i--)
{
p->a[i + 1] = p->a[i];
}
//存储数据
p->a[pos] = value;
//更新last
p->last++;
return 0;
}
//按位置删除
int sqlist_delete_pos(sqlist_t *p, int pos)
{
//判断为空
if (sqlist_is_empty(p))
{
puts("empty");
return -1;
}
//判断pos有效取值区间
if (pos < 0 || pos > p->last)
{
puts("pos error");
return -1;
}
//数据往前移动
int i;
for (i = pos + 1; i <= p->last; i++)
{
p->a[i - 1] = p->a[i];
}
//更新last
p->last--;
return 0;
}
//删除重复
int sqlist_delete_repeat(sqlist_t *p)
{
int i, j; //i:基准值的下标 j:与基准值比较的下标
for (i = 0; i < p->last; i++)
{
for (j = i + 1; j <= p->last; j++)
{
if (p->a[i] == p->a[j])
{
sqlist_delete_pos(p, j);
j--; //重复判断删除后的新数据
}
}
}
return 0;
}
//遍历顺序表
int sqlist_show(sqlist_t *p)
{
int i;
for (i = 0; i <= p->last; i++)
{
printf("%d ", p->a[i]);
}
putchar(10);
return 0;
}
5.4、测试调用相关代码
代码可以如下:
#include "./src/list.h"
int main(int argc, const char *argv[])
{
sqlist_t *l = sqlist_create();
sqlist_insert(l, 10);
sqlist_insert(l, 20);
sqlist_insert(l, 30);
sqlist_insert(l, 40);
sqlist_insert(l, 50);
sqlist_insert(l, 60);
printf("插入数据:");
sqlist_show(l);
sqlist_delete(l);
printf("删除数据:");
sqlist_show(l);
sqlist_change(l, 30, 13);
printf("修改数据:");
sqlist_show(l);
sqlist_insert_pos(l, 3, 19);
printf("按位置插:");
sqlist_show(l);
sqlist_delete_pos(l, 3);
printf("按位置删:");
sqlist_show(l);
printf("查找数据:%d\n", sqlist_search(l, 2));
putchar(10);
sqlist_t *m = sqlist_create();
sqlist_insert(m, 10);
sqlist_insert(m, 20);
sqlist_insert(m, 30);
sqlist_insert(m, 20);
sqlist_insert(m, 40);
sqlist_insert(m, 20);
sqlist_insert(m, 20);
sqlist_insert(m, 50);
sqlist_insert(m, 60);
printf("插入数据:");
sqlist_show(m);
sqlist_delete_repeat(m);
printf("删除重复:");
sqlist_show(m);
free(l);
free(m);
l = NULL;
m = NULL;
return 0;
}
5.5、测试效果
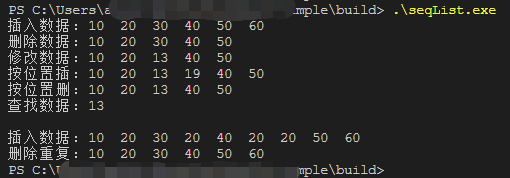
使用cmake编译完成之后,运行的效果如下图所示。
六、通用代码实现(顺序表与业务节点分离)
此处主要实现追主要的插入、获取、删除、测试算法的代码,其他的详细代码如果有兴趣可以私聊我。嘻嘻^_^
6.1、链表节点的定义
①、在实际使用中,自定义链表逻辑节点,定义如下:
typedef struct __tag_seqlist
{
int length; // 长度
int capacity; // 最大容量
unsigned int **node; // 指向内存空间
} seqlist_t;
②、在代码中, 封装了一些用户自定义的数据类型,如下
typedef void seqList;
typedef void ListNode;
typedef int status;
③、在主函数中,定义业务节点如下
typedef struct __teacher
{
int age;
char name[32];
} teacher;
6.2、插入元素
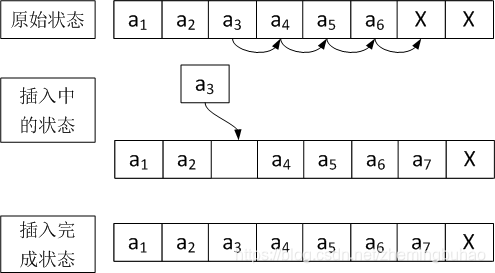
假设顺序表最大容量为8,目前循序表中有6个节点,现在需要在第三个位置插入新的节点,那么,需要做的主要工作为:
- 因为是插入节点,所以需要首先判断顺序表目前是否为满
- 需要将第三个位置之后的所有节点依次后移
- 将新的节点插入到顺序表中
- 更新顺序表的长度
插入示意图入下图所示。
那么,代码实现可以为:
status List_insert(seqList *list, ListNode *node, int pos)
{
int i;
seqlist_t *tlist = (seqlist_t *)list;
if (list == NULL || node == NULL || pos < 0 || pos > tlist->capacity)
{
printf("func insert error, illegal parameter!\n");
return -1;
}
// 当输入的参数大于当前顺序表中的元素数目,则将新插入的元素插入到最末尾
if (pos > tlist->length)
{
pos = tlist->length;
}
// 1、判断是否为满
if (List_isFull(list))
{
printf("func insert error, seqlinst is Full!\n");
return -1;
}
// 2、元素后移
for (i = tlist->length; i > pos; i--)
{
tlist->node[i] = tlist->node[i - 1];
}
// 3、插入参数
tlist->node[i] = (unsigned int)node;
// 4、顺序表的长度更新
tlist->length += 1;
return 0;
}
6.3、获取元素
顺序表可以直接通过位置来获取对应的元素,代码可以这样写:
ListNode *List_get(seqList *list, int pos)
{
seqlist_t *tlist = (seqlist_t *)list;
if (list == NULL || pos < 0 || pos > tlist->capacity || pos > tlist->length)
{
printf("func get error, illegal parameter!\n");
return NULL;
}
return (ListNode *)tlist->node[pos];
}
6.4、删除元素
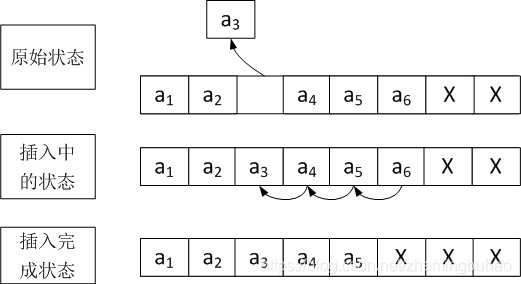
假设顺序表最大容量为8,目前循序表中有6个节点,现在需要删除第三个位置的节点,那么,需要做的工作为:
- 因为是删除节点,所以需要首先判断顺序表目前是否为空
- 需要将删除的节点先做缓存,以便调用者去处理后续事宜
- 需要将第3个位置之后的所有节点依次前移
- 更新顺序表的长度
那么,代码实现可以为:
ListNode *List_delete(seqList *list, int pos)
{
int i;
seqlist_t *tlist = (seqlist_t *)list;
// 参数判断
if (tlist == NULL || pos < 0 || pos > tlist->capacity || pos > tlist->length)
{
printf("func get error, illegal parameter!\n");
return NULL;
}
if (List_isEmpty(list))
{
printf("func insert error, seqlinst is Empty!\n");
return NULL;
}
// 缓存要删除的节点
seqlist_t *tmp = (seqlist_t *)tlist->node[pos];
// 依次前移元素
for (i = pos + 1; i < tlist->length; i++)
{
tlist->node[i - 1] = tlist->node[i];
}
// 长度更新
tlist->length--;
return tmp;
}
七、测试用例
说明:
本例程中使用的线性表,与普通的常见的线性表有点区别,主要表现为:
线性表不管上层应用是什么样的节点,对每一个节点的生命周期也不管,只关注的是节点的内存空间的首地址,然后线性表负责将这些节点组织成一个线性表。
也就是说,
本例程中的线性表,将上层应用节点与顺序表分离开来,上层应用的节点可以是任意的节点,只要提供给节点的首地址,则可以将任意形式的节点组织成线性表。
7.1、测试用例文件结构
seqList/
├── CMakeLists.txt
├── README.md
├── build
└── src
│ ├── list.c
│ └── list.h
└── test.c
2 directory, 6 files
CMakeLists.txt: cmake文件
build: cmake编译工作目录
list.*: 顺序表相关的源码、头文件
test.c: 测试用例的主要测试文件
7.2、用户自定义声明
说明一下,在list.h中定义了相关用户自定义变量、结构体等
typedef void seqList;
typedef void ListNode;
typedef int status;
typedef struct __func_seqlist
{
seqList *(*create)(int);
status (*destory)(seqList *);
status (*clear)(seqList *);
int (*length)(seqList *);
int (*capacity)(seqList *);
ListNode *(*get)(seqList *, int);
status (*insert)(seqList *, ListNode *, int);
ListNode *(*delete)(seqList *, int);
status (*isEmpty)(seqList *);
status (*isFull)(seqList *);
} funSeqList;
7.3、CMake相关
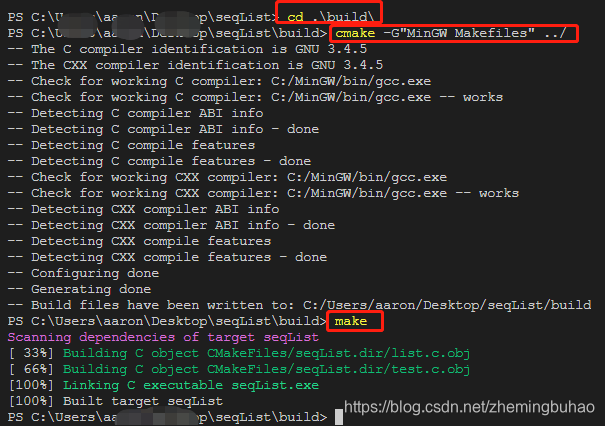
为了在不同的平台下,均可以比较省事情的进行代码功能测试,在本历程中集成了Cmake工具,在使用过程中,几个简单的指令就可以完成测试,笔者是在windows环境下使用的,所以说使用的分别为:
cd build
cmake -G"MinGW Makefiles" ..
make
./seqList.exe
效果如图所示
其他和cmake以及需要注意的事项在README.md里面有详细说明。
7.4、测试时候使用的代码
#include "./src/list.h"
extern funSeqList SeqListfunc;
typedef struct __teacher
{
int age;
char name[32];
} teacher;
int main(int argc, const char *argv[])
{
int ret = 0, i = 0;
seqList *list = NULL;
teacher t1, t2, t3, t4, t5;
t1.age = 31;
memcpy(t1.name, "George", sizeof("George"));
t2.age = 32;
memcpy(t2.name, "Page", sizeof("Page"));
t3.age = 33;
memcpy(t3.name, "PeppaPig", sizeof("PeppaPig"));
t4.age = 34;
memcpy(t4.name, "zhangsan", sizeof("zhangsan"));
t5.age = 35;
memcpy(t5.name, "lisi", sizeof("lisi"));
list = SeqListfunc.create(8);
if (list == NULL)
{
printf("func create() error, return NULL\n");
return -1;
}
// 插入
ret = SeqListfunc.insert(list, (ListNode *)&t1, 0); //头插入法
ret = SeqListfunc.insert(list, (ListNode *)&t2, 0); //头插入法
ret = SeqListfunc.insert(list, (ListNode *)&t3, 0); //头插入法
ret = SeqListfunc.insert(list, (ListNode *)&t4, 0); //头插入法
ret = SeqListfunc.insert(list, (ListNode *)&t5, 0); //头插入法
// 遍历
for (i = 0; i < SeqListfunc.length(list); i++)
{
teacher *tmp = SeqListfunc.get(list, i);
if (tmp == NULL)
{
return -1;
}
printf("name = %s\t age = %d\n", tmp->name, tmp->age);
}
// 打印当前顺序表的长度和最大容量
printf("length = %d, capacity = %d\n", SeqListfunc.length(list), SeqListfunc.capacity(list));
// 删除节点
SeqListfunc.delete(list, 0);
// 打印当前顺序表的长度和最大容量
printf("length = %d, capacity = %d\n", SeqListfunc.length(list), SeqListfunc.capacity(list));
while (SeqListfunc.length(list) > 0)
{
SeqListfunc.delete(list, 0);
}
// 打印当前顺序表的长度和最大容量
printf("length = %d, capacity = %d\n", SeqListfunc.length(list), SeqListfunc.capacity(list));
return 0;
}
7.5、运行效果
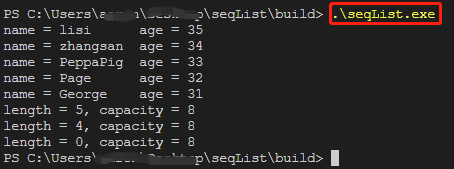
在使用make编译完成之后,可以直接指令 ./seqList.exe ,在windows环境下会自动编程下图所示的效果。
八、顺序表的特点、优点、缺点
8.1、特点
逻辑关系上相邻的两个元素在物理位置上也相邻,因此可以随机存取表中任一元素,它的存储位置可用一个简单、直观的公式来表示。
8.2、优点
不需要为线性表中的逻辑关系增加额外的空间
可以快速获取表中合法位置的元素
8.3、缺点
插入和删除操作需要移动大量的元素
当线性表变化较大的时难以确定存储空间的容量
上一篇: 数据结构(一) – C语言版 – 基本概念与算法基本概念
下一篇: 数据结构(三) – C语言版 – 线性表的链式存储 - 单链表