数据库索引问题总结
数据库索引本质上是一种数据结构(存储结构+算法),目的是为了加快目标数据检索的速度。
一.数据库索引的优缺
优点:
1.大大加快数据的检索速度2.创建唯一性索引,可以保证数据库每一行数据的唯一性3.加速表与表之间的连接4.在使用分组和排序子句进行数据库检索时,可以显著减少查询分组和排序的维护速度.
缺点:
1.创建索引需要占用物理空间2.对表中数据进行增删改,索引需要从新计算,消耗性能.
性别字段为什么不适合加索引?从B+树角度分析
重复率高的不适合做索引,区分度越高,扫描的记录数越少.
区分的公式count(distinct col)/count(*)
待补充....
二.索引分类
唯一索引/主键索引/ 聚簇索引/非聚簇索引 组合索引/
- 唯一索引:确保数据唯一性
- 非唯一索引:这些字段可以重复,不要求唯一.
- 主键索引:是唯一索引的特定类型,创建主键时自动创建.
- 聚簇索引: 表中记录的物理顺与键值顺序相同,表数据和主键一起存储.
- 非聚簇索引: 表数据和索引分两部分存储
聚簇非聚簇区别,和格子使用场景
根本区别: 表记录的 物理顺序 索引的排列顺序 是否一致
聚簇索引:
- 优点: 查询速度快,主键和索引在一个结构里.
-
缺点: 对表进行修改速度慢,** 插入新纪录要重排,维持B+树特性二频繁分裂调整,十分低效.
- 场景:要取出一定范围的数据时;无需插入新值时.
非聚簇索引:
- 优点:添加纪录不会引起数顺序重排.
- 场合:频繁更新的列;此列包含了大数目的不同值
6.组合索引(联合索引):基于多个字段而创建的索引
语法:
create index i_name on table_name(col1,col2...)
;
注意:如果查询条件不包含索引首字段,将不会走索引
条件查询会让部分索引失效
三.索引的实现(数据结构)
目前大部分数据库系统及文件系统采用的是B-Tree或B+Tree.而B+Tree是数据库系统实现索引的首选数据结构(不同引擎对索引的实现不同)
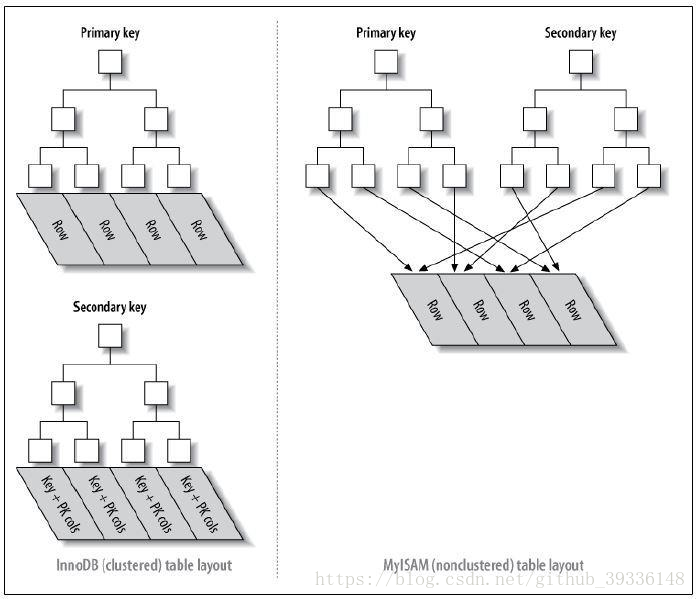
MyISAM索引实现(非聚簇索引)
MyISAM不管是主键索引还是辅助索引都用的非聚簇索引,结构一致
索引文件和数据文件是分离的,因为叶子节点data域保存数据地址
检索过程:按照B+Tree搜索算法搜索索引,存在指定Key,取出data域的值,以data地址取对应数据记录.
InnoDB索引实现(聚簇索引)
InnoDB索引用的是聚簇索引,表数据是和主键一起存储的,
主键索引的叶结点data域存储完整数据表记录.
辅助索引的叶结点data域存储行的主键值。
主键索引非常高效,但是辅助索引需要检索两边索引(辅助索引首先获得主键,通过主键索引检索记录)
两种索引对比图
- 结合实例进行比较
id
为主键,name为辅助索引,比较如下:
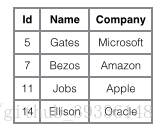
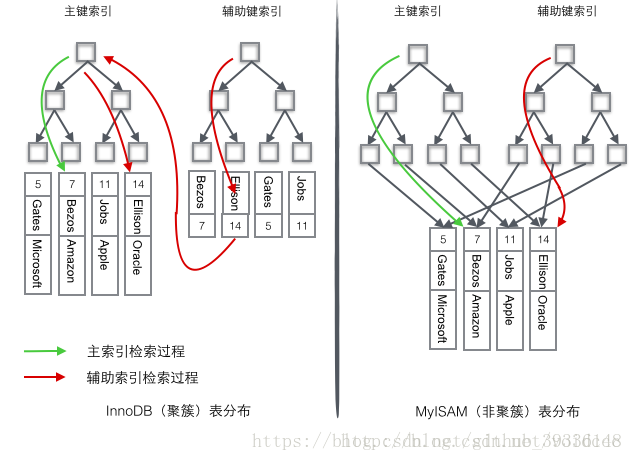
image.png
四.建索引的几大原则
- 最左前缀原则(< >范围查询尽量放后面)
- 区分度越高,扫描记录越少(反例:性别)
- 尽量扩展,不要新建
- where中经常用到的建立索引
- like模糊查询中,右模糊(123%)才会用到索引.