一、主从复制
1、主从复制的概念
主从复制:将一台redis服务器上的数据复制到另外一台redis服务器中,前者称之为
主节点(Master),后者称之为从节点(Slave)。数据只能从主节点到从节点,复制
是单向的。master以写为主,slave以读为主。
注意: 每个redis服务器都是一个主节点,每个主节点可以连接多个从节点,但是每个从节点只能有一个主节点(一个爸爸可以有多个儿子,但儿子只能一个爸爸,隔壁老王除外,儿子也可以有儿子,既能当爹也能当儿子)。最少是一主二从(一个主机挂掉了还可以有从机进行替代)。
2、主从复制的作用
2.1 数据冗余:(一个数据集合中重复的数据)
》主从复制实现了数据的热备份,是持久化之外的数据冗余的一种方式。
2.2 故障恢复:
》当主节点出现故障时,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务的冗余
2.3 负载均衡:
》在主从复制的基础上,配合读写分离,可以由主节点提供写服务,从节点提供读服务(即写Redis数据应当连接主节点,读redis数据应该连接从节点),分担服务器负载,尤其是在写少读多的情况下,通过多个从节点,可以分担读负载,大大提高redis服务器的负载量。
2.4 高可用基石:
》主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基石
3、主从复制原理和策略
3.1 原理:
Slave启动成功连接到master后会发送一个sync同步命令Master接受到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
3.2 配置方式:
[root@iZm5eahcvgu9z4wc5wsl3yZ ~]# redis-cli
127.0.0.1:6379> info replication #查看主从配置信息
# Replication
role:master #当前进程redis为主节点
connected_slaves:3 #它下面有三个从节点
######################从节点案例###################
[root@iZm5eahcvgu9z4wc5wsl3yZ redis-4.0.10]# redis-cli -p 6380 #启动一个从节点服务器
127.0.0.1:6380> info replication
# Replication
role:slave #为从节点
要配置从节点,我们首先需要修改服务其的配置文件,修改其端口号等。这里就不一一展示了。
[root@iZm5eahcvgu9z4wc5wsl3yZ redis-4.0.10]# redis-server redis82.conf
[root@iZm5eahcvgu9z4wc5wsl3yZ redis-4.0.10]# redis-cli -p 6382
127.0.0.1:6382> info replication
# Replication
role:master #当前角色为master
127.0.0.1:6382> slaveof 127.0.0.1 6379 #设置为从节点
OK
127.0.0.1:6382> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
二、哨兵模式
假想一下,如果某一天,MASTER皇帝驾崩了,也就是我们redis主节点宕机挂掉,这个时候不可能是群龙无首,那么应该怎么处理这个问题呢?
在古代,皇帝驾崩由太子继位,但是如果皇帝是突然暴毙而又未立太子,必定是引起纷争,免不了刀兵想见。
不过值得庆幸,我们是在社会主义,社会主义那个好啊。好了,不扯了。一般当官位空缺,我们会通过选举这种方法进行投票,选举一个新的MASTER。在redis集群中也是如此,那么就要引进我们的哨兵模式。
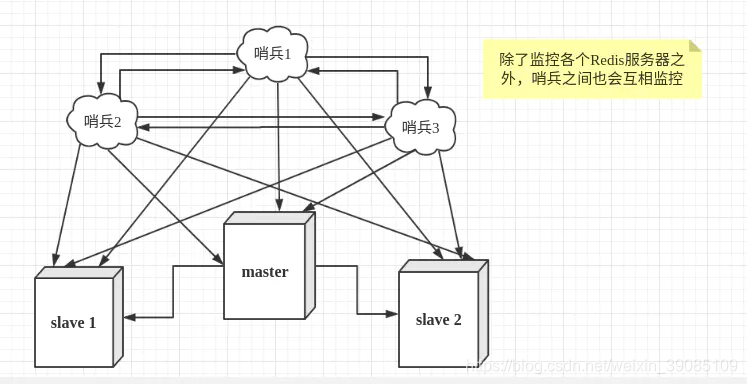
哨兵监控多个redis服务器,同时互相监督。
总结哨兵模式的三个作用:
1、监控:不断的监控redis主从服务器是否正常运行
2、提醒:当被监控的redis出现问题时,哨兵可以发出警示信息
3、自动故障迁移:当主节点MASTER出现问题,哨兵会通过选举机制将从节点SLAVE升级为主节点MASTER。
前面已经有主从复制的分布式集群了,我们来做个试验,光说不练假把式。GO!
127.0.0.1:6379> info replication #查看当前服务器角色
# Replication
role:master #当前为主节点
connected_slaves:3 #已经有三个从节点了
[root@izbp1bbjc5qwrrd5z2ezayz redis4]# redis-server sentinel.conf --sentinel #启动从哨兵
*** FATAL CONFIG FILE ERROR ***
Reading the configuration file, at line 69
>>> 'sentinel monitor mymaster 127.0.0.1 6379 2'
sentinel directive while not in sentinel mode
[root@izbp1bbjc5qwrrd5z2ezayz redis4]# redis-server sentinel.conf --sentinel
26324:X 10 Jun 14:58:48.902 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
26324:X 10 Jun 14:58:48.902 # Redis version=4.0.2, bits=64, commit=00000000, modified=0, pid=26324, just started
26324:X 10 Jun 14:58:48.902 # Configuration loaded
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.2 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 26324
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
26324:X 10 Jun 14:58:48.906 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
26324:X 10 Jun 14:58:48.909 # Sentinel ID is 785f7f540bba4ca5eda46191f92d50a98968ea8c
26324:X 10 Jun 14:58:48.909 # +monitor master mymaster 127.0.0.1 6379 quorum 2
26324:X 10 Jun 14:58:48.910 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
26324:X 10 Jun 14:58:48.915 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
26324:X 10 Jun 14:58:48.917 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
强制关闭主节点服务器
127.0.0.1:6379> exit
[root@izbp1bbjc5qwrrd5z2ezayz redis4]# ps -ef | grep redis #查看主节点进程id
root 26234 1 0 14:19 ? 00:00:02 redis-server 127.0.0.1:6379
root 26254 1 0 14:22 ? 00:00:01 redis-server 127.0.0.1:6381
root 26260 1 0 14:22 ? 00:00:01 redis-server 127.0.0.1:6380
root 26270 1 0 14:25 ? 00:00:01 redis-server 127.0.0.1:6382
root 26274 26216 0 14:25 pts/3 00:00:00 redis-cli -p 6382
root 26324 26174 0 14:58 pts/1 00:00:00 redis-server *:26379 [sentinel]
root 26349 26195 0 15:02 pts/2 00:00:00 redis-server *:26479 [sentinel]
root 26354 27841 0 15:03 pts/0 00:00:00 grep --color=auto redis
[root@izbp1bbjc5qwrrd5z2ezayz redis4]# kill -9 26234 #强制关闭主节点
[root@izbp1bbjc5qwrrd5z2ezayz redis4]# ps -ef | grep redis #可以看到主节点已经不存在
root 26254 1 0 14:22 ? 00:00:01 redis-server 127.0.0.1:6381
root 26260 1 0 14:22 ? 00:00:01 redis-server 127.0.0.1:6380
root 26270 1 0 14:25 ? 00:00:01 redis-server 127.0.0.1:6382
root 26274 26216 0 14:25 pts/3 00:00:00 redis-cli -p 6382
root 26324 26174 0 14:58 pts/1 00:00:00 redis-server *:26379 [sentinel]
root 26349 26195 0 15:02 pts/2 00:00:00 redis-server *:26479 [sentinel]
root 26356 27841 0 15:03 pts/0 00:00:00 grep --color=auto redis
此时,从节点的哨兵后台输出了一句话
26324:X 10 Jun 15:04:14.947 # +sdown master mymaster 127.0.0.1 6379 #主节点已经关闭
+odown master mymaster 127.0.0.1 6379 #quorum 1/1
26407:X 10 Jun 15:30:24.757 # +new-epoch 1
26407:X 10 Jun 15:30:24.757 # +try-failover master mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:24.760 # +vote-for-leader 785f7f540bba4ca5eda46191f92d50a98968ea8c 1
26407:X 10 Jun 15:30:24.760 # +elected-leader master mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:24.760 # +failover-state-select-slave master mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:24.818 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:24.818 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:24.901 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:25.837 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:25.837 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:25.924 * +slave-reconf-sent slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:26.861 * +slave-reconf-inprog slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:27.878 * +slave-reconf-done slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:27.977 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:28.938 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:28.938 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:29.022 # +failover-end master mymaster 127.0.0.1 6379
26407:X 10 Jun 15:30:29.022 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381
26407:X 10 Jun 15:30:29.022 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6381
26407:X 10 Jun 15:30:29.022 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
26407:X 10 Jun 15:30:29.022 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
26407:X 10 Jun 15:30:59.035 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
从中可以看出,已经进行投票,将6381设置为master了。
来,我们光说不行,来验证一下:
127.0.0.1:6381> info replication
# Replication
role:master #该端口已经为主节点了
connected_slaves:2
那么,若果原来的主节点重新连接上来会是什么情况呢?
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6381
可以看出,它也不会上位,重新变成主节点,它只能乖乖打工了,打工是不可能打工的。