概念
Read-Copy Update,简称RCU,可以认为它是一种锁或者一种同步机制,其实说它是一种同步机制应该更恰当些,因为本身RCU的核心实现没有用到锁,只是用了内存屏障+TLS(线程本地变量)或者是Per-CPU变量都可以。
RCU的使用场景是读多写少的场景,但是他和读写锁最大的差异就是,读写锁在持有写锁的时候,读锁会被阻塞,但是RCU允许读锁高并发,就算在持有写锁的时候,也能实现读锁不被阻塞。
RCU经常和链表的场景结合在一起。
RCU的内核主要实现者是Paul E. McKenney,他也写了很多RCU方面的文章: 他把这些文章和一些关于RCU的论文的链接整理到了一起
特点
RCU由三个基本机制组成,
第一个用于插入(发布 - 订阅机制)
第二个用于允许读者容忍并发插入和删除
第三个用于删除(等待预先存在的RCU读取器完成)
具体实现
发布订阅机制
这里举一个例子
p = kmalloc(sizeof(* p),GFP_KERNEL);
p-> a = 1;
p-> b = 2;
p-> c = 3;
gp = p;
这一段代码我们关心的是从编译器和cpu的优化角度,执行顺序的问题,很显然,语句1和语句2,3,4之间是有先后依赖关系的,
因为语句1对指针变量做了内存申请,语句2,3,4依赖语句1,对这个指针寻址取值,所以从编译器和cpu的角度来说,任何优化都不能打乱这个先后顺序,否则就乱套了,程序直接死机。
但是,语句2,3,4和语句5之间,是没有任何先后依赖的,从编译器和cpu的角度来说,先执行语句2,3,4还是先执行语句5,没有关系,所以他们会根据优化角度,用认为最合适的顺序来执行。所以没有任何东西迫使编译器和CPU按顺序执行最后四个赋值语句。
如果他们的执行顺序乱了的话,有可能我们在另一个线程获取到gp的时候,变量还没有初始化,导致程序运行逻辑异常,那么这个时候我们可以使用内存屏障来解决这个问题。
RCU就使用发布和订阅的概念,封装了内存屏障的实现,让用户不用g关心内存屏障的实现细节,直接改用发布订阅机制。
发布就是针对写者侧来说的,具体函数为rcu_assign_pointer(p, v)
订阅就是针对读者侧来说的,具体函数为rcu_dereference§
上面的代码改为使用发布订阅的话,改为一下流程:
p = kmalloc(sizeof(* p),GFP_KERNEL);
p-> a = 1;
p-> b = 2;
p-> c = 3;
rcu_assign_pointer(gp, p);
读者获取gp的时候:
rcu_dereference(gp)
需要注意的一点是,RCU的写者与写者之间,是需要加锁的,一般使用自旋锁,同时需要关闭系统的中断和任务抢占。
以下是linux kernel对RCU链表的使用代码片段
spin_lock_irqsave(&rb->event_lock, flags);
list_add_rcu(&event->rb_entry, &rb->event_list);
spin_unlock_irqrestore(&rb->event_lock, flags);
允许读者容忍并发插入和删除
上面提到,RCU写者与写者之间,是需要加锁的,但是读者的操作是不用任何锁,就算是写者正在操作的过程中,也是如此,那么它是怎么实现的呢?
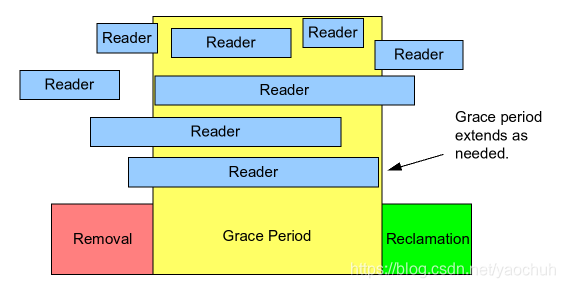
如上图所示,reader表示高并发的读者,removal表示写者准备开始删除某个节点,reclamation表示写者已经完成删除动作,而grace period表示删除的宽松期,宽松期的时间长短取决于写者开始删除的时候,当前有多少个读者正在锁里面。
写者的动作主要分为以下几步:
- 对链表进行修改,使用内存屏障保证一致性,这里的修改包括对链表节点的增加或者删除;
- 如果是删除节点,删除的节点的内存暂时不能free,需要等到宽松期结束,也就是说所有对这个节点使用的读者使用结束,具体实现原语就是synchronize_rcu,下面会将讲这个函数的实现逻辑;
- 释放节点内存
写者对链表操作分为以上三步,其中第一步不阻塞,第二步会阻塞,但是第二步不影响读者的使用。说白点,就是说,当写者完成第一步的时候,高并发的读者中,新的读者来使用链表的时候,链表中已经不存在旧的节点了,只是旧的节点需要在上面的第三部才回去删除而已。
这个时候高并发的读者可以一直使用链表,不管的新来的读者(看到的是更新后的链表),还是在宽松期里面的读者(看到的是旧的链表),这就是RCU读者能高并发的具体实现。
等待预先存在的RCU读取器完成
上面说到synchronize_rcu时写者等待宽松期到来的阻塞动作,那么它是怎么实现的?
最开始的时候,我说到“RCU的核心实现没有用到锁,只是用了内存屏障+TLS(线程本地变量)或者是Per-CPU变量都可以”
内存屏障在发布订阅里面有所体现,那么TLS或者per_cpu呢?
TLS即线程局部存储,TLS变量在一个线程中是全局的且归该线程独自所有,其他线程无法共享。
我们可以利用TLS来实现synchronize_rcu原语。
当我们在使用读锁的时候,我们会给读锁使用rcu_read_lock和rcu_read_unlock表示其临界区,
这个时候,如果我们在rcu_read_lock和rcu_read_unlock里面对tls变量做标记,那么,我们就能知道读锁是否已经完成,而且又不影响读锁的并发,因为tls是线程私有的。如下代码片段所示:
static inline void rcu_read_lock(void)
{
__get_thread_var(rcu_reader_gp) = rcu_gp_ctr + 1;
smp_mb();
}
static inline void rcu_read_unlock(void)
{
smp_mb();
__get_thread_var(rcu_reader_gp) = rcu_gp_ctr;
}
这个时候,我们只需要在synchronize_rcu里面判断所有线程的TLS变量,直到当前GP期里面的所有读者线程都退出临界区位置,我们就知道了可以释放旧的链表节点了。换言之,synchronize_rcu开始的时候,就是一个GP期开始的时刻,结束的时候就是GP结束的时刻。
for_each_online_thread(thread)
run_on(thread);
具体实现:
void synchronize_rcu(void)
{
int t;
/* Memory barrier ensures mutation seen before grace period. */
smp_mb();
/* Only one synchronize_rcu() at a time. */
spin_lock(&rcu_gp_lock);
/* Advance to a new grace-period number, enforce ordering. */
rcu_gp_ctr += 2;
smp_mb();
/*
* Wait until all threads are either out of their RCU read-side
* critical sections or are aware of the new grace period.
*/
for_each_thread(t) {
while ((per_thread(rcu_reader_gp, t) & 0x1) &&
((per_thread(rcu_reader_gp, t) - rcu_gp_ctr) < 0)) {
/*@@@ poll(NULL, 0, 10); */
barrier();
}
}
/* Let other synchronize_rcu() instances move ahead. */
spin_unlock(&rcu_gp_lock);
/* Ensure that any subsequent free()s happen -after- above checks. */
smp_mb();
}
这里使用了for_each_thread,当然,我们可以使用for_each_cpu,看具体实现,原理是一样的,像linux内核里面的实现,就是使用了per_cpu变量来实现的DEFINE_PER_CPU。
synchronize_rcu属于一个同步等待GP(宽松期)的实现,linux 内核在实现rcu的时候,还加入了call_rcu,这个函数的作用是通过异步的方式来实现synchronize_rcu,call_rcu主要是通过注册回调函数,注册到链表里面,让写者可以异步释放链表节点,不用一直阻塞在当前thread。
用户态rcu库
Mathieu Desnoyers and Paul E. McKenney实现了一套urcu的开源库,有兴趣的可以自己下载
yum search urcu就可以找到对应的版本了.