环境说明
系统:
centos7.7
docker:
19.03.11
elk:
sebp/elk latest
filebeat:
filebeat-7.2.0
备注:elk和filebeat在同一台服务器上
架构:
-
Elasticsearch
一个近乎实时查询的全文搜索引擎。Elasticsearch 的设计目标就是要能够处理和搜索巨量的日志数据。 -
Logstash
读取原始日志,并对其进行分析和过滤,然后将其转发给其他组件(比如 Elasticsearch)进行索引或存储。Logstash 支持丰富的 Input 和 Output 类型,能够处理各种应用的日志。 -
Kibana
一个基于 JavaScript 的 Web 图形界面程序,专门用于可视化 Elasticsearch 的数据。Kibana 能够查询 Elasticsearch 并通过丰富的图表展示结果。用户可以创建 Dashboard 来监控系统的日志。 -
Filebeat
引入Filebeat作为日志搜集器,主要是为了解决Logstash开销大的问题。相比Logstash,Filebeat 所占系统的 CPU 和内存几乎可以忽略不计。
日志处理流程:
Filebeat将日志发送给Logstash进行分析和过滤,然后由Logstash转发给Elasticsearch,最后由Kibana可视化Elasticsearch 的数据

安装 ELK 套件
ELK 的部署方案可以非常灵活,在规模较大的生产系统中,ELK 有自己的集群,实现了高可用和负载均衡。我们的目标是在最短的时间内学习并实践 ELK,因此将采用最小部署方案:在容器中搭建 ELK。
1.运行ELK镜像需要vm.max_map_count至少需要262144内存
echo "vm.max_map_count=262144" > /etc/sysctl.conf
sysctl -p
2.安装docker # 根据自己的情况更改docker镜像源,否则拉取镜像很慢。
yum -y install docker
systemctl start docker
systemctl enable docker
3.运行ELK镜像
sudo docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk
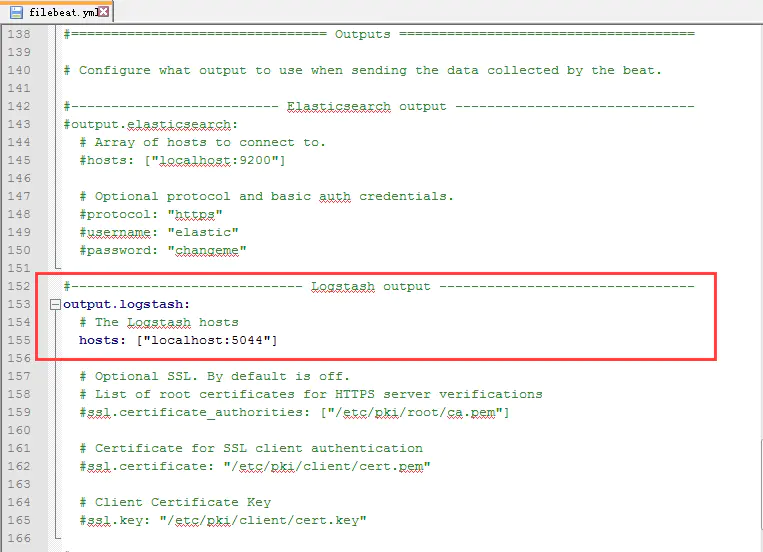
4.配置logstash
进入容器 sudo docker exec -it elk /bin/bash
修改02-beats-input.conf
vim /etc/logstash/conf.d/02-beats-input.conf
删除 ssl => true
删除 ssl_certificate => "/pki/tls/certs/logstash.crt"
删除 ssl_key => "/pki/tls/private/logstash.key"

注意 1:将以下三行删除掉,这三行的意思是是否使用证书,本例是不使用证书的。如果你需要使用证书,将logstash.crt拷贝到客户端,然后在filebeat.yml里面添加路径即可。
注意 2:sebp/elk docker是自建立了一个证书logstash.crt,默认使用*通配配符,如果你使用证书,filebeat.yml使用的服务器地址必须使用域名,不能使用IP地址,否则会报错。
5.重启elk容器
docker restart elk
6.登录kibana ip:5601
注意:Elasticsearch的JSON接口:http://[Host IP]:9200/_search?pretty
7.安装Filebeat # 到官网下载filebeat即可
rpm -ivh filebeat.......rpm
systemctl enable filebeat
8.配置filebeat
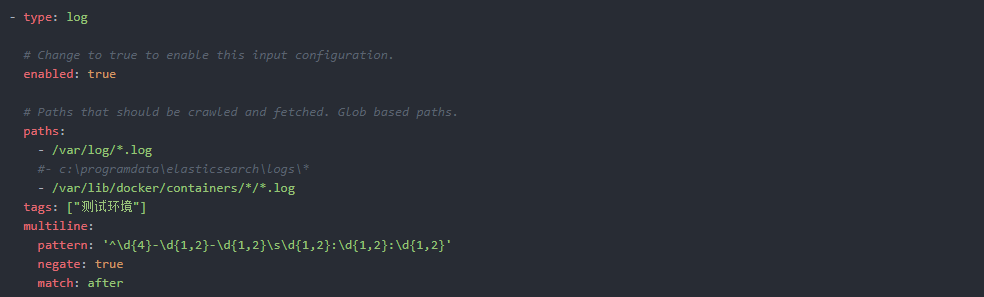
cat /etc/filebeat/filebeat.yml
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/datas/logs/*/*.log
- /var/lib/docker/containers/*/*.log
tags: ["测试环境"]
multiline:
pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})'
# pattern: '^\s*("{)'
negate: true
match: after
max_lines: 1000
timeout: 30s
注释:
enabled:filebeat 6.0后,enabled默认为关闭,必须要修改成true
paths:为你想要抓取分析的日志所在路径
multiline:如果不进行该合并处理操作的话,那么当采集的日志很长或是像输出xml格式等日志,就会出现采集不全或是被分割成多条的情况
pattern:配置的正则表达式,指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串),如果匹配不到的话,就进行合并行。
paths:为你想要抓取分析的日志所在路径
multiline:如果不进行该合并处理操作的话,那么当采集的日志很长或是像输出xml格式等日志,就会出现采集不全或是被分割成多条的情况
pattern:配置的正则表达式,指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串),如果匹配不到的话,就进行合并行。


9.启动filebeat服务
systemctl start filebeat
10.kibana配置
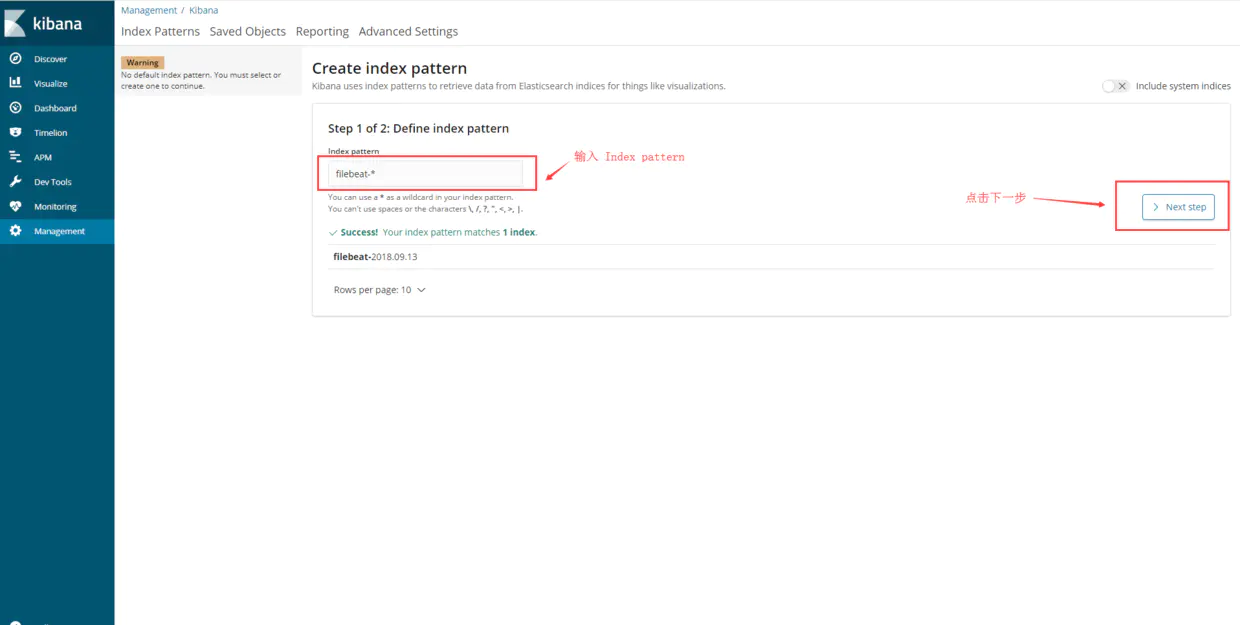
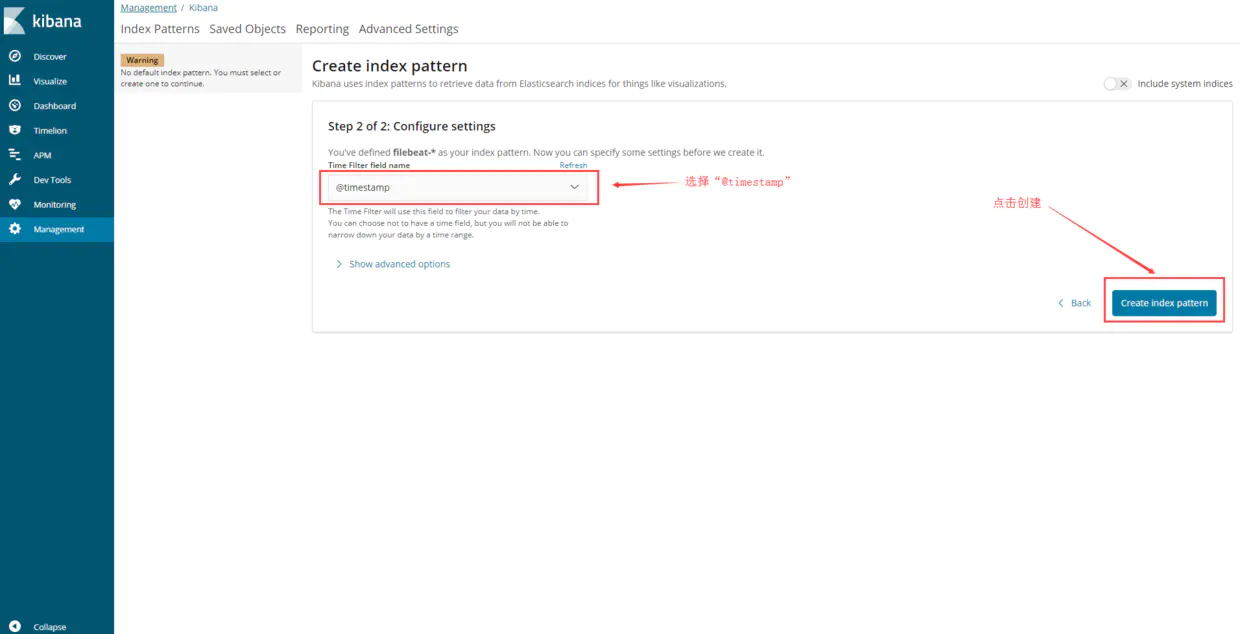
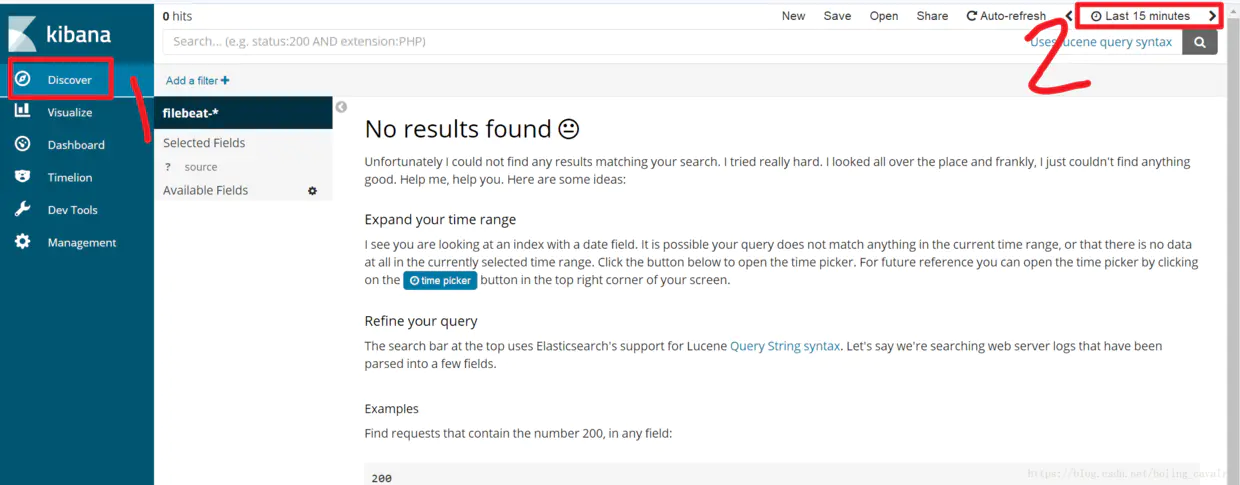
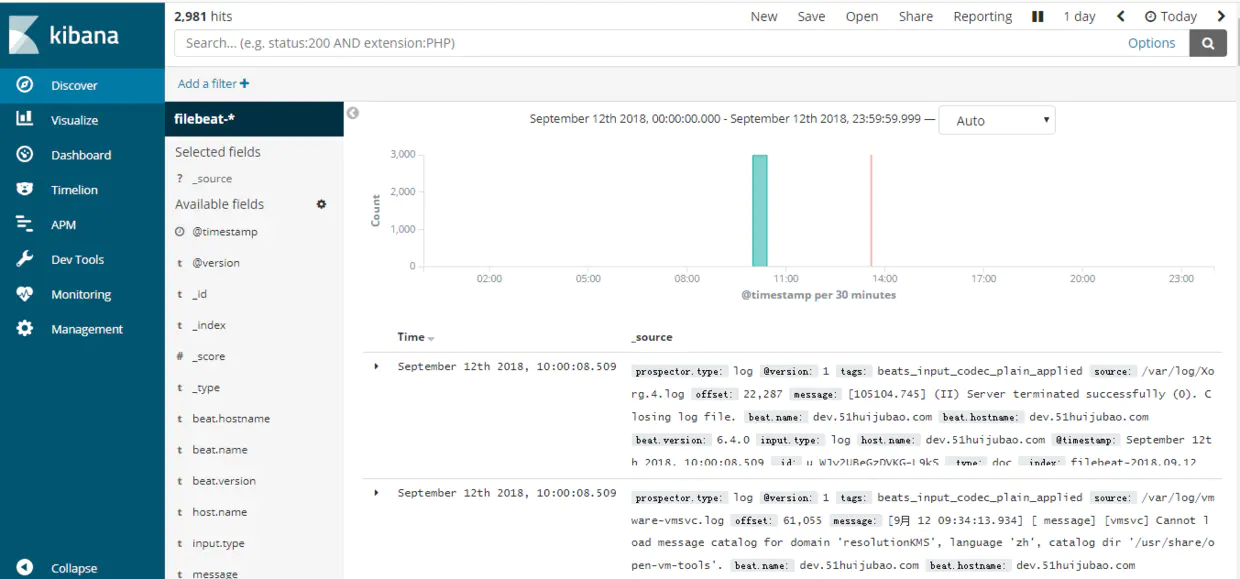
------------恢复内容开始------------
环境说明
系统:
centos7.7
docker:
19.03.11
elk:
sebp/elk latest
filebeat:
filebeat-7.2.0
备注:elk和filebeat在同一台服务器上
架构:
-
Elasticsearch
一个近乎实时查询的全文搜索引擎。Elasticsearch 的设计目标就是要能够处理和搜索巨量的日志数据。 -
Logstash
读取原始日志,并对其进行分析和过滤,然后将其转发给其他组件(比如 Elasticsearch)进行索引或存储。Logstash 支持丰富的 Input 和 Output 类型,能够处理各种应用的日志。 -
Kibana
一个基于 JavaScript 的 Web 图形界面程序,专门用于可视化 Elasticsearch 的数据。Kibana 能够查询 Elasticsearch 并通过丰富的图表展示结果。用户可以创建 Dashboard 来监控系统的日志。 -
Filebeat
引入Filebeat作为日志搜集器,主要是为了解决Logstash开销大的问题。相比Logstash,Filebeat 所占系统的 CPU 和内存几乎可以忽略不计。
日志处理流程:
Filebeat将日志发送给Logstash进行分析和过滤,然后由Logstash转发给Elasticsearch,最后由Kibana可视化Elasticsearch 的数据
安装 ELK 套件
ELK 的部署方案可以非常灵活,在规模较大的生产系统中,ELK 有自己的集群,实现了高可用和负载均衡。我们的目标是在最短的时间内学习并实践 ELK,因此将采用最小部署方案:在容器中搭建 ELK。
1.运行ELK镜像需要vm.max_map_count至少需要262144内存
echo "vm.max_map_count=262144" > /etc/sysctl.conf
sysctl -p
2.安装docker # 根据自己的情况更改docker镜像源,否则拉取镜像很慢。
yum -y install docker
systemctl start docker
systemctl enable docker
3.运行ELK镜像
sudo docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk
4.配置logstash
进入容器 sudo docker exec -it elk /bin/bash
修改02-beats-input.conf
vim /etc/logstash/conf.d/02-beats-input.conf
删除 ssl => true
删除 ssl_certificate => "/pki/tls/certs/logstash.crt"
删除 ssl_key => "/pki/tls/private/logstash.key"
注意 1:将以下三行删除掉,这三行的意思是是否使用证书,本例是不使用证书的。如果你需要使用证书,将logstash.crt拷贝到客户端,然后在filebeat.yml里面添加路径即可。
注意 2:sebp/elk docker是自建立了一个证书logstash.crt,默认使用*通配配符,如果你使用证书,filebeat.yml使用的服务器地址必须使用域名,不能使用IP地址,否则会报错。
5.重启elk容器
docker restart elk
6.登录kibana ip:5601
注意:Elasticsearch的JSON接口:http://[Host IP]:9200/_search?pretty
7.安装Filebeat # 到官网下载filebeat即可
rpm -ivh filebeat.......rpm
systemctl enable filebeat
8.配置filebeat
cat /etc/filebeat/filebeat.yml
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/datas/logs/*/*.log
- /var/lib/docker/containers/*/*.log
tags: ["测试环境"]
multiline:
pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})'
# pattern: '^\s*("{)'
negate: true
match: after
max_lines: 1000
timeout: 30s
注释:
enabled:filebeat 6.0后,enabled默认为关闭,必须要修改成true
paths:为你想要抓取分析的日志所在路径
multiline:如果不进行该合并处理操作的话,那么当采集的日志很长或是像输出xml格式等日志,就会出现采集不全或是被分割成多条的情况
pattern:配置的正则表达式,指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串),如果匹配不到的话,就进行合并行。
paths:为你想要抓取分析的日志所在路径
multiline:如果不进行该合并处理操作的话,那么当采集的日志很长或是像输出xml格式等日志,就会出现采集不全或是被分割成多条的情况
pattern:配置的正则表达式,指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串),如果匹配不到的话,就进行合并行。
9.启动filebeat服务
systemctl start filebeat
10.kibana配置
------------恢复内容结束------------