Spring Data JPA 入门实战笔记
相关概念
ORM思想
- Object-Relational Mapping 表示对象关系映射,在面向对象的软件开发中,通过ORM,就可以把对象映射到关系型数据库中。
- 主要目的:
操作实体类就相当于操作数据库表,不再重点关注sql语句 - 建立两个映射关系:
实体类和表的映射关系
实体类中属性和表中字段的映射关系 - 实现了ORM思想的框架:
Mybatis、Hibernate
Hibernate框架
- 一个开放源代码的对象关系映射框架
- 对JDBC进行了非常轻量级的对象封装
- 将POJO与数据库表建立映射关系,是一个全自动的ORM框架
JPA规范
-
JPA的全称是Java Persistence API, 即Java持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成。
-
JPA通过JDK 5.0注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
-
优点:
①标准化
任何声称符合 JPA 标准的框架都遵循同样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能够在不同的JPA框架下运行。
②容器级特性支持
JPA框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的局限,在企业应用发挥更大的作用。
③简单方便
在JPA框架下创建实体和创建Java 类一样简单,没有任何的约束和限制,只需要使用javax.persistence.Entity进行注释,JPA的框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。
④ 查询能力
JPA的查询语言是面向对象而非面向数据库的,JPA定义了独特的JPQL(Java Persistence Query Language),它是针对实体的一种查询语言,操作对象是实体,能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
⑤高级特性
JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性在关系数据库的持久化。 -
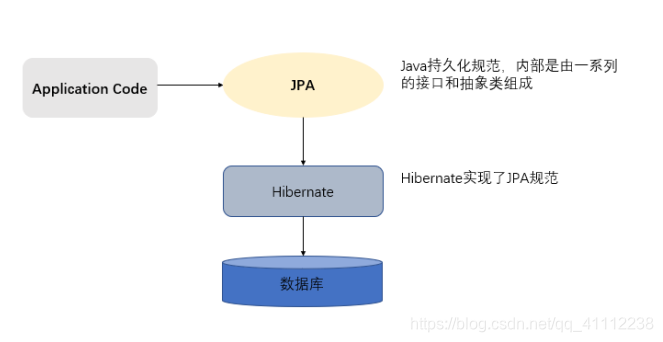
JPA与hibernate的关系
JPA规范本质上就是一种ORM规范,注意不是ORM框架——JPA并未提供ORM实现,它只是制订了规范,提供了编程的API接口,具体实现则由服务厂商来提供。JPA和Hibernate的关系就像JDBC和JDBC驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。如果使用JPA规范进行数据库操作,底层需要hibernate作为其实现类完成数据持久化工作。
Spring Data JPA概述
- Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。
- 它提供了包括增删改查等在内的常用功能,且易于扩展,可以极大提高开发效率。
- Spring Data JPA 让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
Spring Data JPA的特性
- 极大简化了数据库访问层代码。
- Dao层中只需要写接口,就自动具有了增删改查、分页查询等方法。
快速入门案例
搭建 Spring Boot 环境
首先从 https://start.spring.io/ 构建一个Gradle的 SpringBoot 工程,选择的组件包括Lombok、 Spring Data JPA 、Web 、MySQL。
下载之后解压,先使用记事本打开 build.gradle ,在 repositories 添加以下配置:
mavenLocal()
maven {
url 'http://maven.aliyun.com/nexus/content/groups/public/'
}
之后使用 IDEA 打开 build.gradle :
完整 build.gradle 配置文件:
plugins {
id 'org.springframework.boot' version '2.2.1.RELEASE'
id 'io.spring.dependency-management' version '1.0.9.RELEASE'
id 'java'
}
group = 'com.sjh'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenLocal()
maven {
url 'http://maven.aliyun.com/nexus/content/groups/public/'
}
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'mysql:mysql-connector-java'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
定义一个测试的 Controller:
@RestController
@RequestMapping("/test")
public class TestController {
@RequestMapping("/hello")
public String hello(){
return "HELLO SPRING BOOT";
}
}
找到 src/main/java 下的 SpringBoot 启动类,由于此时还没有配置数据库,需要对@SpringBootApplication注解添加忽视数据库配置的属性(在配置数据库信息后要取消):
@SpringBootApplication(exclude= {DataSourceAutoConfiguration.class})
public class SpringdatajpaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringdatajpaApplication.class, args);
}
}
然后启动该类,访问localhost:8080/test/hello:
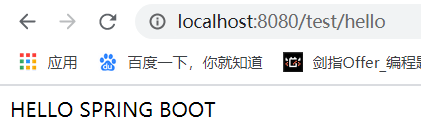
此时 Spring Boot 的环境已经成功搭建了。
创建数据库表
/*创建客户表*/
CREATE TABLE customer (
cust_id BIGINT(32) PRIMARY KEY AUTO_INCREMENT COMMENT '客户编号(主键)',
cust_name VARCHAR(32) NOT NULL COMMENT '客户名称(公司名称)',
cust_source VARCHAR(32) DEFAULT NULL COMMENT '客户信息来源',
cust_industry VARCHAR(32) DEFAULT NULL COMMENT '客户所属行业',
cust_level VARCHAR(32) DEFAULT NULL COMMENT '客户级别',
cust_address VARCHAR(128) DEFAULT NULL COMMENT '客户联系地址',
cust_phone VARCHAR(64) DEFAULT NULL COMMENT '客户联系电话'
);
配置数据库信息
在 src/main/resources 下新建 application.yml 配置文件:
spring:
datasource:
url: jdbc:mysql:///test?characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: sjh2019
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
show-sql: true
properties:
hibernate:
format_sql: true
创建实体类
@Table 关联实体类和表
@Column 关联实体类属性和表中字段
@Getter@Setter//Lombok的注解,自动生成getter、setter方法
@Entity//表明是一个实体类
@Table(name = "customer")
public class Customer {
@Id//声明主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//配置主键生产策略
@Column(name = "cust_id")
private Long id;//主键
@Column(name = "cust_name")
private String name;//名称
@Column(name = "cust_source")
private String source;//来源
@Column(name = "cust_industry")
private String industry;//行业
@Column(name = "cust_level")
private String level;//级别
@Column(name = "cust_address")
private String address;//地址
@Column(name = "cust_phone")
private String phone;//联系方式
}
@Table 注解报错其实是不影响正常执行的,如果要解决该问题,只需要配置一下IDEA的Database即可:
编写持久层接口
只需要继承 JpaRepository 即可,泛型参数列表中第一个参数是实体类类型,第二个参数是主键类型。
public interface CustomerRepo extends JpaRepository<Customer,Long> {
}
查询
根据 id 查询
@RunWith(SpringRunner.class)
@SpringBootTest
public class CustomerRepoTest {
@Autowired
private CustomerRepo customerRepo;
@Test
public void findById(){
Optional<Customer> customer = customerRepo.findById(1L);
System.out.println(customer);
}
}
结果(需要事先插入一些测试数据):

查询所有
@Test
public void findAll(){
List<Customer> customers = customerRepo.findAll();
System.out.println(customers);
}
由于只插入了一条测试数据,结果仍然只有一条,但是可以发现 SQL 语句是不同的,不再有 WHERE 筛选:

添加和修改
添加
如果添加对象的 id 在表中还不存在,会执行添加操作。
@Test
public void save(){
Customer customer = new Customer();
customer.setId(3L);
customer.setName("kobe");
customerRepo.save(customer);
}
此时数据库没有 id=3 的记录,根据 SQL 语句可以发现执行的是 insert 操作。

修改
如果添加对象的 id 在表中已经存在,会执行更新操作。
@Test
public void update(){
Customer customer = new Customer();
customer.setId(3L);
customer.setName("sjh");
customerRepo.save(customer);
}
此时数据库有 id=3 的记录,根据 SQL 语句可以发现执行的是 update 操作。

删除
@Test
public void delete(){
customerRepo.deleteById(3L);
}
可以发现此时 SQL 执行的是 delete 操作:

执行过程和原理总结:
- 通过
JdkDynamicAopProxy的invoke方法创建了一个动态代理对象SimpleJpaRepository。 SimpleJpaRepository中封装了JPA的操作。- 通过
hibernate(封装了JDBC)完成数据库操作。
复杂查询
接口方法查询
统计总数
使用 count() 方法查询总数
@Test
public void count(){
long count = customerRepo.count();
System.out.println("记录数:"+count);
}
执行的 SQL 语句和结果:

判断存在
使用 existsById() 方法根据 id 查询满足条件的记录数,如果值大于0代表存在,反之。
@Test
public void exists(){
boolean exists = customerRepo.existsById(2L);
System.out.println("该客户记录:"+ (exists?"存在":"不存在"));
}
执行的 SQL 语句和结果:

根据 id 查询
与之前不同的是,使用 getOne() 方法根据 id 查询。
注意使用 getOne() 方法要加上 @Transactional 注解,否则无法正常执行。
@Test
@Transactional
public void getOne(){
Customer one = customerRepo.getOne(1L);
System.out.println(one);
}
执行的 SQL 语句和结果:

与 findById() 方法的不同:
findById() 调用 find 方法,属于立即加载
getOne() 调用 getReference 方法,获得的是一个动态代理对象,属于延迟加载,使用时才进行查询,需要事务的支持。
使用 JPQL 查询
根据名称查询
在接口中增加一个根据名称查询的方法:
//根据客户名称查询
@Query(value = "from Customer where name = ?1 ")//?1表示参数列表的第一个参数
Customer findByName(String name);
测试类和方法:
@RunWith(SpringRunner.class)
@SpringBootTest
public class CustomerRepoJPQLTest {
@Autowired
private CustomerRepo customerRepo;
@Test
public void findByName(){
Customer sjh = customerRepo.findByName("sjh");
System.out.println(sjh);
}
}
执行的 SQL 和结果:

根据 id 和名称查询
接口方法:
//根据客户id和名称查询
@Query(value = "from Customer where id = ?1 and name = ?2 ")
Customer findByIdAndName(Long id, String name);
测试方法:
@Test
public void findByIdAndName(){
Customer sjh = customerRepo.findByIdAndName(4L,"sjh2");
System.out.println(sjh);
}
执行的 SQL 和结果:

根据 id 来更新客户名称
接口方法:
//根据客户id更新名称
@Query(value = "update Customer set name = ?2 where id = ?1 ")
@Modifying//更新和删除操作要使用该注解表明是修改操作
void updateNameById(Long id, String name);
测试方法:
@Test
@Transactional//JPQL除了查询之外的修改操作需要事务支持
@Rollback(value = false)//默认回滚,需要取消该属性
public void updateNameById(){
customerRepo.updateNameById(1L,"sjh1");
}
执行的 SQL 和结果:

SQL 查询
查询全部
接口方法:
nativeQuery 属性代表是否使用本地查询,false是默认值即使用 JPQL 查询, true表示使用 SQL 查询。
@Query(value = "select * from customer", nativeQuery = true)
List<Customer> findAllBySQL();
测试方法:
@Test
public void findAllBySQL(){
List<Customer> customers = customerRepo.findAllBySQL();
System.out.println(customers);
}
执行的 SQL 和结果:

模糊查询
接口方法:
nativeQuery 属性代表是否使用本地查询,false是默认值即使用 JPQL 查询, true表示使用 SQL 查询。
@Query(value = "select * from customer where cust_name like ?1 ",nativeQuery = true)
List<Customer> findByNameLike(String pattern);
测试方法:
@Test
public void findByNameLike(){
List<Customer> customers = customerRepo.findByNameLike("sjh%");
System.out.println(customers);
}
执行的 SQL 和结果:

方法名称规则查询
是对 JPQL 的封装,只需要按照 Spring Data JPA 提供的方法名称规则定义方法,不需要再进行配置。
findBy+ 查询条件,在运行阶段会根据方法名称进行解析。
基础查询
根据 id 查询 :
Optional<Customer> findById(Long id);
根据名称查询:
Customer findByName(String name);
模糊查询
根据名称模糊查询:
Customer findByNameLike(String name);
多条件查询
根据 id 和名称精确查询:
Customer findByIdAndName(Long id, String name);
根据名称模糊查询和行业精准查询:
Customer findByNameLikeAndIndustry(String name, String industry);
Specifications动态查询
使用动态查询需要继承另一个接口JpaSpecificationExecutor,泛型参数为实体类类型:
public interface CustomerRepo extends JpaRepository<Customer,Long>, JpaSpecificationExecutor<Customer>
该接口的方法包括:
public interface JpaSpecificationExecutor<T> {
//查询单个对象
Optional<T> findOne(@Nullable Specification<T> var1);
//查询全部
List<T> findAll(@Nullable Specification<T> var1);
//查询全部并分页,Pageable是分页参数
Page<T> findAll(@Nullable Specification<T> var1, Pageable var2);
//查询全部并排序,Sort是排序参数
List<T> findAll(@Nullable Specification<T> var1, Sort var2);
//统计总数
long count(@Nullable Specification<T> var1);
}
Specification 代表的是查询条件,是一个接口,需要自定义实现该接口的toPredicate方法:
@Nullable
Predicate toPredicate(Root<T> var1, CriteriaQuery<?> var2, CriteriaBuilder var3);
root 代表查询的根对象,封装了查询属性;CriteriaQuery 代表顶层查询对象(一般不用);CriteriaBuilder代表查询构造器,封装了查询条件。
条件查询
查询名称为 sjh 的记录:
@RunWith(SpringRunner.class)
@SpringBootTest
public class CustomerRepoSpecTest {
@Autowired
private CustomerRepo customerRepo;
@Test
public void findOne(){
//构建自定义查询条件
Specification<Customer> spec = (Specification<Customer>) (root, criteriaQuery, criteriaBuilder) -> {
Path<Object> name = root.get("name");//获取比较的属性
return criteriaBuilder.equal(name, "sjh");
};
Optional<Customer> customer = customerRepo.findOne(spec);
System.out.println(customer);
}
}
执行的 SQL 和结果:

查询名称为 sjh,行业为 it 的记录:
@Test
public void findOne2(){
Specification<Customer> spec = (Specification<Customer>) (root, criteriaQuery, criteriaBuilder) -> {
Path<Object> name = root.get("name");
Path<Object> industry = root.get("industry");
Predicate p1 = criteriaBuilder.equal(name, "sjh");
Predicate p2 = criteriaBuilder.equal(industry, "it");
return criteriaBuilder.and(p1,p2);
};
Optional<Customer> customer = customerRepo.findOne(spec);
System.out.println(customer);
}
执行的 SQL 和结果:

根据客户名称模糊查询:
对于 gt、lt、ge、le、like 等比较需要将 path 对象通过 as(Class<X> var1) 方法转换成相应的类型参数。
@Test
public void findAll(){
Specification<Customer> spec = (Specification<Customer>) (root, criteriaQuery, criteriaBuilder) -> {
Path<Object> name = root.get("name");
return criteriaBuilder.like(name.as(String.class),"s%");
};
List<Customer> customers = customerRepo.findAll(spec);
System.out.println(customers);
}
执行的 SQL 和结果:

条件+排序查询
根据名称模糊查询+根据 id 倒序排序:
使用 Sort.by()方法创建排序对象
@Test
public void findSort(){
Specification<Customer> spec = (Specification<Customer>) (root, criteriaQuery, criteriaBuilder) -> {
Path<Object> name = root.get("name");
return criteriaBuilder.like(name.as(String.class),"s%");
};
//创建排序对象
Sort sort = Sort.by(Sort.Direction.DESC, "id");
List<Customer> customers = customerRepo.findAll(spec, sort);
System.out.println(customers);
}
执行的 SQL 和结果:

条件+分页查询
分页查询,查询第1页,每页显示2条:
@Test
public void findPage(){
Specification<Customer> spec = null;
Pageable pageable = PageRequest.of(0,2);
//创建分页对象
Page<Customer> customers = customerRepo.findAll(spec, pageable);
System.out.println("总条数:" + customers.getTotalElements());
System.out.println("页数"+ customers.getTotalPages());
System.out.println("数据"+ customers.getContent());
}
执行的 SQL 和结果:

多表查询
一对多
一的一方为主表,多的一方为从表,需要在从表新建一列作为外键,取值来源于主表的主键。
主表使用之前的 customer 表,从表使用 linkman 表。
- 一对一
- 一对多
一的一方为主表,多的一方为从表,需要在从表新建一列作为外键,取值来源于主表的主键 - 多对多
需要一张中间表,最少需要两个字段作为外键指向两张表的主键,组成了联合主键
实体类关系
- 包含 通过实体类的包含关系描述表关系
- 继承
步骤
- 明确表关系
- 确定表关系(描述 通过外键|中间表)
- 编写实体类,在实体类中描述表关系(包含关系)
- 配置映射关系
创建 linkman 表
/*创建联系人表*/
CREATE TABLE linkman (
lkm_id BIGINT(32) PRIMARY KEY AUTO_INCREMENT COMMENT '联系人编号(主键)',
lkm_name VARCHAR(16) COMMENT '联系人姓名',
lkm_gender CHAR(1) COMMENT '联系人性别',
lkm_phone VARCHAR(16) COMMENT '联系人办公电话',
lkm_mobile VARCHAR(16) COMMENT '联系人手机',
lkm_email VARCHAR(64) COMMENT '联系人邮箱',
lkm_position VARCHAR(16) COMMENT '联系人职位',
lkm_memo VARCHAR(512) COMMENT '联系人备注',
lkm_cust_id BIGINT(32) NOT NULL COMMENT '客户id(外键)',
CONSTRAINT `FK_cst_linkman_lkm_cust_id` FOREIGN KEY (`lkm_cust_id`) REFERENCES `customer` (`cust_id`)
);
创建实体类和对应接口
@Getter@Setter
@Entity
@Table(name="linkman")
public class Linkman {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "lkm_id")
private Long id;
@Column(name ="lkm_name" )
private String name;
@Column(name = "lkm_gender")
private String gender;
@Column(name = "lkm_phone")
private String phone;
@Column(name = "lkm_mobile")
private String mobile;
@Column(name = "lkm_email")
private String email;
@Column(name = "lkm_position")
private String position;
@Column(name = "lkm_memo")
private String memo;
}
-----
public interface LinkmanRepo extends JpaRepository<Linkman,Long> {
}
配置关系
在 Customer 类配置一对多关系:
@OneToMany :配置一对多关系,mappedBy属性 = 主表实体类在从表实体类中对应的属性名。
@OneToMany(mappedBy = "customer")
@JoinColumn(name ="lkm_cust_id" ,referencedColumnName = "cust_id")
private Set<Linkman> linkmen=new HashSet<>();
在 Linkman 类配置多对一关系:
在从表一方维护外键关系,提示效率。
@ManyToOne :配置多对一关系,targetEntity属性 = 主表对应实体类的字节码。
@JoinColumn:配置外键关系,name = 外键名称,referencedColumnName = 主表主键名称。
@ManyToOne(targetEntity = Customer.class)
@JoinColumn(name ="lkm_cust_id" ,referencedColumnName = "cust_id")
private Customer customer;
添加记录
测试类和方法:
@RunWith(SpringRunner.class)
@SpringBootTest
public class OneToManyTest {
@Autowired
private CustomerRepo customerRepo;
@Autowired
private LinkmanRepo linkmanRepo;
@Test
@Transactional
@Rollback(value = false)
public void save(){
//创建客户和联系人
Customer customer = new Customer();
customer.setName("customer");
Linkman linkman = new Linkman();
linkman.setName("linkman");
//保存外键关系
linkman.setCustomer(customer);
//保存客户和联系人
customerRepo.save(customer);
linkmanRepo.save(linkman);
}
}
执行的 SQL 和结果:

删除记录
**删除从表数据:**可以任意删除。
删除主表数据:
-
有从表数据
- 在默认情况下,它会把外键字段置为null,然后删除主表数据。如果在数据库的表 结构上,外键字段有非空约束,默认情况就会报错。
- 如果配置了放弃维护关联关系的权利,则不能删除(与外键字段是否允许为null, 没有关系)因为在删除时,它根本不会去更新从表的外键字段了。
- 如果还想删除,使用级联删除。
-
没有从表数据引用:随便删
级联操作
指操作一个对象同时操作它的关联对象
使用方法:只需要在操作主体的注解上配置 cascade 属性。
//配置一对多关系
@OneToMany(mappedBy = "customer",cascade = CascadeType.ALL)
private Set<Linkman> linkmen = new HashSet<>();
级联添加:
只需要保存客户就可以保存联系人
@Test
@Transactional
@Rollback(false)
public void save(){
//创建客户和联系人
Customer customer = new Customer();
customer.setName("customer");
Linkman linkman = new Linkman();
linkman.setName("linkman");
//保存外键关系
linkman.setCustomer(customer);
customer.getLinkmen().add(linkman);
//保存客户和联系人
customerRepo.save(customer);
}
执行的 SQL 和结果:

级联删除:
只需要删除客户就可以删除联系人
@Test
@Transactional
@Rollback(false)
public void delete(){
Customer customer = customerRepo.getOne(13L);
customerRepo.delete(customer);
}
执行的 SQL 和结果:

对象导航查询
含义:查询一个对象(get方法查询)的同时,通过此对象可以查询它的关联对象。
对象导航查询一到多默认使用延迟加载的形式查询, 关联对象是集合,使用立即加载可能浪费资源。
对象导航查询多到一默认使用立即加载的形式查询, 关联对象是一个对象,所以使用立即加载。
如果要改变加载方式,在实体类注解配置加上fetch属性即可,LAZY 表示延迟加载,EAGER 表示立即加载。
多对多
创建数据库表
创建一个 user 表,字段为 id 和 name。
创建一个 role 表,字段为 id 和 name。
创建一个 user_role 中间表 ,字段为 uid 和 rid。
创建对应实体类
@ManyToMany:配置多表之间的关系,targetEntity = 对方实体类的class对象。
@JoinTable:配置中间表关系,name = 中间表表名,joinColumns 配置自己在中间表的字段和对应实体类的属性,inverseJoinColumns配置对方在中间表的字段和对应实体类的属性。
User类:
@Getter@Setter
@Entity
@Table(name = "user")
public class User implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
@Column(name = "name")
private String name;
@ManyToMany(targetEntity = Role.class)
@JoinTable(name = "user_role",
joinColumns = {@JoinColumn(name = "uid",referencedColumnName = "id")},
inverseJoinColumns = {@JoinColumn(name ="rid" ,referencedColumnName ="id" )})
private Set<Role> roles=new HashSet<>();
}
Role类:
@Getter
@Setter
@Entity
@Table(name = "role")
public class Role implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
@Column(name = "name")
private String name;
@ManyToMany(targetEntity = User.class)
@JoinTable(name = "user_role",
joinColumns = {@JoinColumn(name = "rid",referencedColumnName = "id")},
inverseJoinColumns = {@JoinColumn(name ="uid" ,referencedColumnName ="id" )})
private Set<User> users=new HashSet<>();
}
创建接口
public interface UserRepo extends JpaRepository<User,Long> {
}
----------
public interface RoleRepo extends JpaRepository<Role,Long> {
}
添加记录
@RunWith(SpringRunner.class)
@SpringBootTest
public class ManyToManyTest {
@Autowired
private UserRepo userRepo;
@Autowired
private RoleRepo roleRepo;
@Test
@Transactional
@Rollback(false)
public void save(){
User user = new User();
user.setName("sjh");
Role role = new Role();
role.setName("tw");
user.getRoles().add(role);
userRepo.save(user);
roleRepo.save(role);
}
}
执行的 SQL 和结果:

如果保存方法中,双方同时执行报错操作就会出错:
@Test
@Transactional
@Rollback(false)
public void save(){
...
user.getRoles().add(role);
role.getUsers().add(user);
...
}
在多对多保存中,如果双向都设置关系,意味着双方都维护中间表,都会往中间表插入数据,中间表的2个字段又作为联合主键,所以报错,主键重复,解决保存失败的问题:只需要在任意一方放弃对中间表的维护权即可。
修改 Role 中的外键配置为:
@ManyToMany(mappedBy = "roles")
private Set<User> users=new HashSet<>();
再次执行保存操作就可以成功执行了。
级联操作
和一对多的级联操作类似,只需要添加 cascade属性
在 User 类的 roles 属性的 @ManyToMany 添加级联属性
@ManyToMany(targetEntity = Role.class, cascade = CascadeType.ALL)
测试方法:
只需要添加用户即可自动添加角色并维护中间表关系。
@Test
@Transactional
@Rollback(false)
public void save(){
User user = new User();
user.setName("sjh");
Role role = new Role();
role.setName("tw");
user.getRoles().add(role);
userRepo.save(user);
}
执行的 SQL 和结果:

删除也是一样的:
只需要删除用户就会自动删除对应的角色并维护中间表关系。
@Test
@Transactional
@Rollback(false)
public void delete(){
userRepo.deleteById(5L);
}
执行的 SQL 和结果:
