什么是JPA
JPA的全称是Java Persistence API,提供了一个规范,用于将数据通过Java对象持久化、读取和管理数据库中的关系表。所以JPA本质上就是一种ORM规范,它的目标是实现ORM的天下归一。
java数据库编程的进化史
这里我以自己的经历来简单说说。
我刚接触java的时候,操作数据库的姿势是这样的:
Class.forName("com.mysql.cj.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root","123456");
// 执行查询
Statement stmt = conn.createStatement();
String sql = "SELECT id, name, url FROM websites";
ResultSet rs = stmt.executeQuery(sql);
这是标准的JDBC操作数据库的方式。直接操作数据库,简单粗暴。
然后接触到Hibernate,这是我学习的第一个ORM框架,虽然现在来看它有一些不足,但是那个时候觉得使用框架操作数据库简直是太方便了。
Hibernate 可以认为是JPA规范的的一种实现,JPA使用一种ORM规范,但是规范在应用中你不能直接使用啊,需要有人实现它才能使用对不对。或者可以这样说,JPA只是声明接口,Hibernate是它的实现。
再后来就是Mybatis,我个人这两年一直在用。Mybatis是一个持久层的sql mapping框架。
mybatis的优势在于可以灵活的写SQL,自由度比较高,同时带来的问题可能是开发效率不如spring data jpa。
大概半年前左右吧,偶然接触到spring data jpa,觉得比mybatis好用,就像当年从eclipse切到idea的那种爽。现在是一直用,一直爽。(当然这种想法可能比较主观)
spring data jpa不是像Hibernate那样对jpa的实现,而是更进一步做了封装。就像netty和NIO的关系一样。既然是封装肯定是更加易用。本文就想分享一下我对spring data jpa的一些认识。
另外,spring data jpa还有一个最大的优势,就是它是spring生态系统中的成员。
spring data jpa的功能介绍
spring data jpa的目的就是不让程序员花太多时间在数据库层面的处理,所以极大的简化了这部分的工作,基本上程序员要做的只是声明接口,然后,就没有然后了。spring data jpa帮你完成后面所有的操作。
基于spring data jpa编写持久层逻辑,一般分为如下几步:
- 定义实体类,关联数据库中的表。
- 声明持久层接口,接口需要继承Repository。
- 接口中声明需要的方法,spring data jpa会自动给我们生成实现代码
Spring data jpa有以下几个常用的接口:
-
Repository:仅仅是一个标识,表明任何继承它的均为仓库接口类,方便Spring自动扫描识别, 一般不在程序中直接使用。
-
CrudRepository:继承Repository,实现了一组CRUD相关的方法,这个用的比较多,一般如果上层业务只需要基本的增删改查,继承这个接口就可以了。
-
JpaRepository:继承PagingAndSortingRepository,实现一组JPA规范相关的方法。这个也用的比较多,它和CrudRepository区别在于支持分页和排序。
使用示例
废话不多说,上代码。
本示例可以在我的github下直接下载:
https://github.com/pony-maggie/spring-boot-jpa-demo
首先需要引入mysql和spring data jpa的依赖包
<!--引入MySQL的依赖关系 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--引入JPA的依赖关系 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
先来写一个实体类,这里给出部分代码,
@Entity
@Table(name="t_student")
public class Student {
@Id
@GeneratedValue
@Column(name = "t_id")
private Long id;
@Column(name = "t_name")
private String name;
@Column(name = "t_age")
private String age;
@Column(name = "t_school")
private String school;
- @Id 标注用于声明一个实体类的属性映射为数据库的主键列。该属性通常置于属性声明语句之前,可与声明语句同行,也可写在单独行上。
- @GeneratedValue 用于标注主键的生成策略,一般情况下建议明确声明使用的策略,比如这里使用的是strategy = GenerationType.IDENTITY,表示数据库会在新行插入时自动给ID赋值,这也叫做ID自增长列。
声明一个持久层接口,
public interface StudentRepository extends JpaRepository<Student, Long> {
}
我们并不需要做其他的任何操作了,因为SpringBoot以及spring data jpa会为我们全部搞定。
JpaRepository接口拥有基本的增删改查接口,包括:
- save
- findAll
- findOne
- delete
所以这些方法我们就不需要声明了,另外还可以添加一些规范方法名进行特定字段的查询,如果在接口中定义的查询方法符合它的命名规则,就可以不用写实现,规则是findXXBy,readAXXBy,queryXXBy,countXXBy, getXXBy后面跟属性名称。
我们添加一个controller进行测试,
@RestController
@RequestMapping(value = "/student")
public class JPAController {
@Autowired
private StudentRepository studentRepository;
@RequestMapping(value = "/save", method = RequestMethod.GET)
public Student save(Student user) {
return studentRepository.save(user);
}
@RequestMapping(value = "/list", method = RequestMethod.GET)
public List<Student> list() {
return studentRepository.findAll();
}
@RequestMapping(value = "/findByName", method = RequestMethod.GET)
public List<Student> findByName(String name) {
return studentRepository.findByName(name);
}
@RequestMapping(value = "/count", method = RequestMethod.GET)
public Long countByName(String name) {
return studentRepository.countByName(name);
}
}
测试
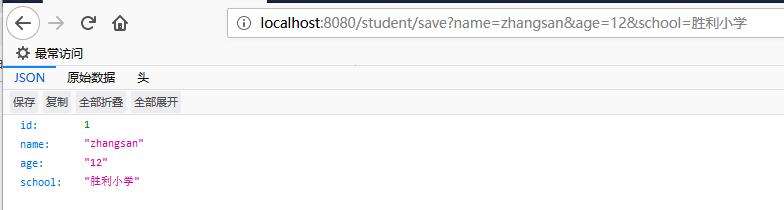
启动spring boot工程,我们在浏览器里进行如下测试,
- 插入两个学生的信息
[外链图片转存失败(img-kAoNEMti-1563726828859)(https://raw.githubusercontent.com/pony-maggie/spring-boot-jpa-demo/master/images/1-1.jpg)]
- 查看两个学生的信息
- 统计学生信息
- 删除其中一个

{kind=link}