摘要:为了研究Hadoop与本系统Linux的兼容性,使用最新的hadoop版本2.7.2进行兼容性测试以及WordCount示例运行。
Hadoop简介
Hadoop下载
首先,根据自己系统的内核情况以及操作系统版本下载所需的软件。
此次测试系统的Linux 内核:3.10.0-327.el7.x86_64,类似RHEL7.2
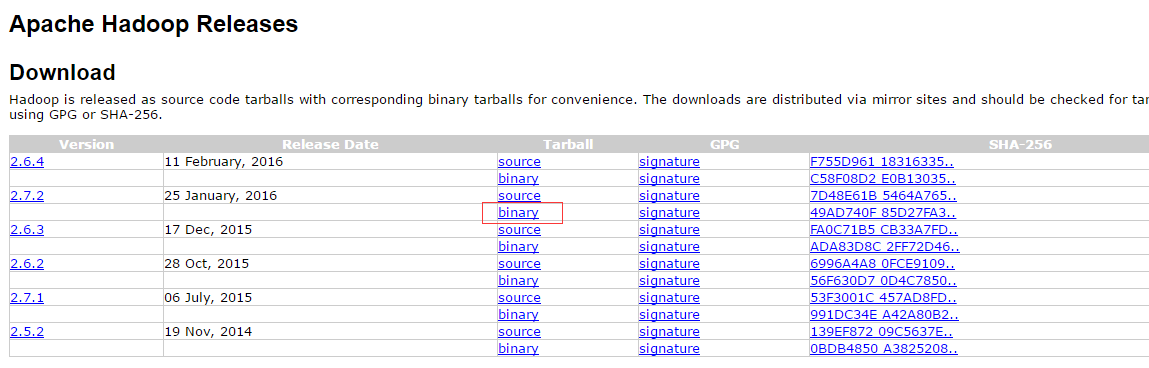
前往:http://hadoop.apache.org/releases.html,如下图中红色框即2.7.2对应的下载地址。
同时“source”即对应hadoop的源码。此处下载免安装压缩包hadoop-2.7.2.tar.gz
Hadoop安装以及集群环境配置
1.硬件环境
利用virt-manager工具进行虚拟机的安装(待细化如何安装),总共安装4台虚拟机
注意:为了网络的正常和实际性,建议选择虚拟机网络使用桥接方式,windows下利用vmware或者virtual box选择桥接方式是比较合适的方法。
物理机为服务器:
内存:64G
CPU:2路32核
其中1台为master,剩余3台为slaves,节点名称以及IP如下所示:
192.168.122.65 master
192.168.122.8 hadoop-node1
192.168.122.149 hadoop-node2
192.168.122.14 hadoop-node3硬件条件:内存2G、CPU:2核、存储:40G
2、四台虚拟机均使用同一个系统RHELV7.2
3、配置master虚拟机准备安装hadoop
a)、添加hadoop组和hadoop用户
$groupadd hadoop
$useradd hadoop –g hadoop
$passwd hadoop密码设置为八位:qwer1234
同理,其余三个机器进行相同配置
b)、配置机器的/etc/hosts文件
按照硬件环境的要求来配置IP和hosts内容,利用ping+[hostname],如果能够通则表示设置/etc/hosts成功。使用linux自带的vim或者其他文本编辑器。添加如下内容:
192.168.122.65 master
192.168.122.8 hadoop-node1
192.168.122.149 hadoop-node2
192.168.122.14 hadoop-node3
c)、下载Sun JDK并且进行配置
前往:http://www.oracle.com/technetwork/java/javase/downloads/index.html
下载最新的JDK,本次测试使用JDK8u77版本,本次下载jdk-8u77-linux-x64.tar.gz压缩包
此压缩包为免安装解压后则可以直接使用
首先解压此文件,解压目录需要可以hadoop用户访问,否则后续使用中则会提示权限问题。
#tar xf jdk-8u77-linux-x64.tar.gz –C /opt/jdk/其次配置JAVA路径,编辑/etc/profile文件,并添加如下内容:
JAVA_HOME=/opt/jdk/jdk1.8.0_73
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH最后,利用souce命令来生效此配置,并利用java –version命令查看配置是否成功
#source /etc/profile
#java –version 如果结果如下内容则表示配置成功:
java version “1.8.0_73”
Java™ SE Runtime Environment (build 1.8.0_73-b02)
Java HotSpot™ 64-Bit Server VM( build 25.73-b02,mixed mode)d)、SSH无密码验证配置(关键部分,否则会报错,具体原理待细化)
前提:安装ssh,本系统默认已经安装;关闭防火墙
#systemctl stop firewalld.service
#systemctl disable firewalld.service基本原理:master主机生成公钥和私钥,将公钥拷贝到各个slaves,利用密钥对进行登录则不需密码实际使用如下所示
配置master无密码登录所有slaves
1)、master节点生成无密码密钥对
#su - hadoop #登录hadoop用户
#ssh-keygen –t rsa
#下面提示中都使用默认即可(都按下“Enter”即可)此时则可以查看/home/hadoop/.ssh/下是否有id_rsa(私钥)和id_rsa.pub(公钥)
2)拷贝公钥到localhost和slaves
$ssh-copy-id -i localhost
$ssh-copy-id -i hadoop-node1
$ssh-copy-id -i hadoop-node2
$ssh-copy-id -i hadoop-node3中间过程中需要输入各个节点的密码。
6)、验证是否成功,是否不需要密码则可以成功登陆
同理,配置salves可以无密码访问master则类似于上述步骤
同理其他机器进行系统操作则可以完成无密码登录master
4、安装并配置hadoop
root用户下解压压缩包到/opt/下,并将权限赋予hadoop
#chown –R hadoop:hadoop /opt/hadoop-2.7.2/配置hadoop,/etc/profile,添加如下内容
export HADOOP_HOME=/opt/hadoop-2.7.2
export PATH=$HADOOP_HOME/bin:$PATH验证:hadoop用户下可以使用“hadoop”命令
配置hadoop
1. hadoop-env.sh 位置在$HADOOP_HOME/etc/hadoop文件夹下
将JAVA_HOME配置成上述jdk的位置即可
export JAVA_HOME=/opt/jdk/jdk1.8.0_732. core-site.xml,新建的$HADOOP_HOME/tmp目录存放临时文件,否则默认为/tmp/hadoo-hadoop
在标签中添加标签
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.3/tmp/</value>
<description>A base for temporary directories</description>
</property>
<!—file system properties>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>3. hdfs-site.xml,分布式文件系统的配置,其中replication为数据副本数量
<property>
<name>dfs.replication</name>
<value>1</value>
</property>4. mapred-site.xml,拷贝自mapred-site.xml.template
<property>
<name>mapred.job.tracker</name>
<value>http://localhost:9001</value>
</property>5. slaves文件,添加几个slaves节点的主机名称即可,例如此处即添加
hadoop-node1
hadoop-node2
hadoop-node3
6. 最后则拷贝这些配置文件到slaves即可,但是注意权限问题,同时修改各个slaves对应的/etc/profile
5、启动验证
以hadoop用户登录master,启动hadoop
$hdfs namenode –format (只需要第一次进行格式化)
$$HADOOP_HOME/sbin/start-all.sh
则可以启动hadoop,查看输出则知道是否输出成功与否
在此版本的hadoop中,start-all.sh被start-dfs.sh、start-yarn.sh代替
如果启动正常则可以看到一些log输出
验证hadoop,master端
$jps
5557 SecondaryNameNode
5366 DataNode
5817 Jps
5214 NameNodeslave端:
8677 NodeManager
8538 DataNode
8876 Jps由此可见均能正常启动成功了。
验证hdfs
$hdfs dfsadmin –report
结果如下所示:
[hadoop@hadoop-node1 ~]$ hdfs dfsadmin -report
Configured Capacity: 152782585856 (142.29 GB)
Present Capacity: 125864767488 (117.22 GB)
DFS Remaining: 125864595456 (117.22 GB)
DFS Used: 172032 (168 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (4):
Name: 192.168.122.14:50010 (hadoop-node3)
Hostname: hadoop-node3
Decommission Status : Normal
Configured Capacity: 38195646464 (35.57 GB)
DFS Used: 45056 (44 KB)
Non DFS Used: 6058930176 (5.64 GB)
DFS Remaining: 32136671232 (29.93 GB)
DFS Used%: 0.00%
DFS Remaining%: 84.14%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Apr 05 11:32:16 CST 2016
Name: 192.168.122.149:50010 (hadoop-node2)
Hostname: hadoop-node2
Decommission Status : Normal
Configured Capacity: 38195646464 (35.57 GB)
DFS Used: 45056 (44 KB)
Non DFS Used: 6750404608 (6.29 GB)
DFS Remaining: 31445196800 (29.29 GB)
DFS Used%: 0.00%
DFS Remaining%: 82.33%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Apr 05 11:32:17 CST 2016
Name: 192.168.122.65:50010 (master)
Hostname: master
Decommission Status : Normal
Configured Capacity: 38195646464 (35.57 GB)
DFS Used: 57344 (56 KB)
Non DFS Used: 7136018432 (6.65 GB)
DFS Remaining: 31059570688 (28.93 GB)
DFS Used%: 0.00%
DFS Remaining%: 81.32%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Apr 05 11:32:15 CST 2016
Name: 192.168.122.8:50010 (hadoop-node1)
Hostname: hadoop-node1
Decommission Status : Normal
Configured Capacity: 38195646464 (35.57 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 6972465152 (6.49 GB)
DFS Remaining: 31223156736 (29.08 GB)
DFS Used%: 0.00%
DFS Remaining%: 81.75%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Apr 05 11:32:16 CST 2016以上为通过命令行方式显示HDFS情况,同时,使用WEB端也可以完成正常的显示和管理操作。
打开192.168.122.65:5007,即可出线如下的界面
WordCount示例
1.hadoop用户下,完成准备工作
创建文件夹
mkdir ~/file
准备文件
echo “word test word hadoop hello” > ~/file/file1.txt
echo “word word word word hadoop hello” > ~/file/file2.txt
echo “word word word word hadoop hello” > ~/file/file3.txt
重启hadoop服务
cd $HADOOP_HOME/sbin
./stop-all.sh
./start-all.sh
确保都正常启动了则可以进行下面内容了。
2.HDFS下创建文件夹input和output文件
hadoop fs -mkdir /input
hadoop fs -mkdir /outputPS:注意“/”是必须的否则提示“No such file or directory”
3.上传本地文件到HDFS上
hadoop fs -put ~/file/file*.txt /input4.运行wordcount
$hadoop jar $HADOOP_HOOME/share/hadoop/mapreduce/hadoop-mapreduce-example-2.7.2.jar wordcount /input /output/wordcount1
此时则运行完成了,查看结果
$hadoop fs -cat /output/wordcount1/part-r-00000此时则会统计本地创建的多个文件的单词数量
例如:
and 1
hello 3
hadoop 2
到此,hadoop真实集群搭建基本完成