一、本章思维导图

二、知识点
1、顺序查找
(1)普通的顺序查找
(2)设置监视哨的顺序查找


int search(SSTable ST, KeyType key) { for(i=ST.length;i>=1;--i) if(ST.R[i].key==key) return i; //从后往前找 return 0; }
int search(SSTable ST, KeyType key) { ST.R[0].key==key; //"哨兵" for(i=ST.length;ST.R[i].key!=key;--i); //从后往前找 return 0; }
2、折半查找
int search(SSTable ST, KeyType key) { low=1; high=ST.length; while(low<=high) { mid=(low+high)/2; if(key==ST.R[mid].key) return mid; //找到待查元素 else if(key<ST.R[mid].key) high=mid-1; //继续在前一子表进行查找 else low=mid+1; // 继续在后一子表进行查找 } return 0; //表中不存在待查元素 }
适合折半查找的数据量分析:
数据量太小不适用,直接用顺序查找即可;
数据量太大也不适用,数据元素存储在数组中,若数据量太大会超出内存课连续空间。
3、分块查找(索引顺序查找)
块间有序,块内无序。
索引表(关键字项和指针项)
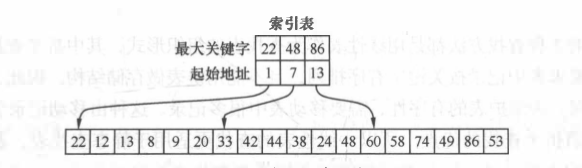
ASL=Lb+Lw=[1/2(n/s)+s]+1,其中Lb为查找索引表确定所在块的平均查找长度,Lw为在块中查找元素的平均查找长度,s为块内的记录个数。
4、二叉排序树
(1)二叉排序树定义:
二叉排序树或者是空树或者是具有下列性质的二叉树:
-
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值。
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值。
- 它的左、右子树也分别为二叉排序树。
(2)二叉树的查找算法
BSTree SearchBST(BSTree T, KeyType key) {//二叉排序树查找 if((T==NULL) || key==T->data.key) return T; //查找结束 else if(key < T->data.key) return SearchBST(T->lchild, key); //在左子树中继续查找 else return SearchBST(T->rchild, key); //在右子树中继续查找 }
5、散列表(哈希表)
(1)散列函数的构造方法
- 数字分析法:从关键字中提取分布均匀的若干位或他们的组合作为地址。
适用情况:事先必须明确知道所有关键字每一位上各种数字的分布情况。
- 平方取中法:取关键字平方后的中间几位或其组合作为散列地址,则使随机分布的关键字得到的散列地址也是随机的。
适用情况:不能事先了解关键字的所有情况,或难于直接从关键字中找到取值较分散的几位。
- 折叠法:
适用情况:适用于散列地址的位数较少,而关键字的位数较多,且难于直接从关键字中找到取值较分散的几位。
- 除留余数法:H(key)=key%p;选取适当的p,一般情况下,p为小于表长的最大质数
适用范围广,计算简单,是常用的构造散列函数的方法。不仅可以对关键字取模,也可以在折叠、平方取中等运算后取模。
(2)处理冲突方法
开放地址法:Hi=(H(key)+di)%m
线性探测法:di=1,2,3,...,m-1
二次探测法:di=di = 12,-12,22,-22,32,-32,… +k2,-k2(k<=m/2)
伪随机探测法:di= 伪随机数序列
链地址法:
散列表:
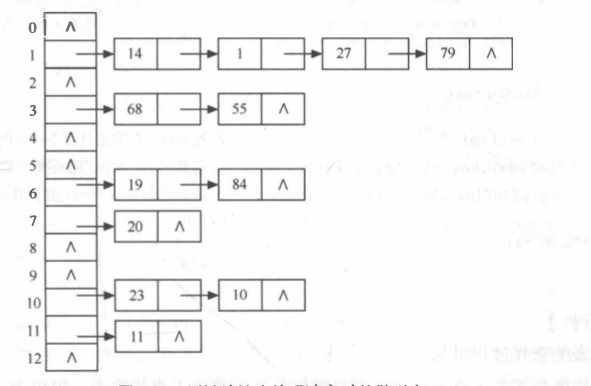
(3)总结:
- 哈希表技术具有很好的平均性能,优于一些传统技术
- 链地址法优于开地址法
- 除留余数法作为哈希函数优于其他类型函数
6、各种比较
(1)平均查找长度比较

(2)顺序查找、折半查找和分块查找的比较

(3)折半查找和二叉排序树查找的比较

三、分享资料:
平衡二叉树的平衡调整:平衡二叉树(树的旋转),我觉得这篇博客写得很清楚,当时听完课懵懵的,看完清晰了,里面还附有实例帮助理解。
B-树和B+树:B树和B+树的插入、删除图解,这篇博客也可以帮助你理解B-树和B+树。