第七章是查找
以下是第七章的知识点总结

以下是我对这一章某些小细节的总结
小细节:
1.若表中不存在关键字等于给定值的记录,则称查找不成功,此时查找结果可给出一个“空”记录或“空”指针
2.动态查找表:表结构是在查找过程中产生的,即在创建表的过程中,对于给定值,若表中存在其关键字等于给定值的记录,则返回查找成功;
否则插入关键字等于给定值的记录

顺序查找:1.适用于线性表的顺序存储结构,又适用于链式存储结构;
2.时间复杂度O(n),空间复杂度O(1)
3.优点:算法简单,对表结构没有要求,且对记录是否按关键字有序均可应用
4.缺点:平均查找长度较大,查找效率较低,n很大的时候不适合用
折半查找:1.线性表必须采用顺序存储结构,而且表中的元素按关键字有序排列;
2.时间复杂度O(log2 n)
3.在查找成功与否的情况下:和给定值进行比较的关键字个数最多也不超过向下取整的(log2 n )+1
4.优点:比较次数少,查找效率高;
5.缺点:对表的要求高,一定要是顺序存储,且关键字必须有序;费时:1.查找前排序;2.对有序表进行插入和删除的时候,平均比较和移动表中一半的元素
6.折半查找不适用于数据元素经常变动的线性表
分块查找:1.优点:.在表中插入和删除元素时,只要找到该元素对应的块,就可以在该块内进行插入和删除。由于块内无序,故插入和删除比较容易,无序进行大量移动
2.缺点:要增加一个索引表的存储空间并对索引表进行排序运算
3.适用于动态变化的线性表
!!!!!这是一条分界线:为了保护表的有序性,线性表的查找更适用于静态查找表,若要对动态查找表进行高效率的查找,可采用几种特殊的二叉树作为查找表的组织形式,在此统称“树表”
树表的查找
1.二叉排序树:又称二叉查找树;!!!!中序遍历一课二叉排序树时可以得到一个节点值递增的有序序列
2.考点:①二叉树的查找,
②插入(在查找的基础上):当树中不存在关键字等于key的结点时才进行插入。新插入的结点一定是新添加的叶子结点,并且是查找不成功时查找路径上访问的最后一个结点的左孩子或右孩子。
时间复杂度O(log2 n)
③创建
假设有n个结点,需要n此插入操作,而插入一个结点的算法时间复杂度是O(log2 n),所以创建二叉排序树算法的时间复杂度为O(nlog2 n)
④删除
基本过程还是在查找,时间复杂度O(log2 n)
删除结点为*p(指向结点的指针为p),其双亲结点为*f,PL和PR分别表示其左子树和右子树
1)*p结点的左右结点均为空:f->lchild=NULL
2) *p结点只有左子树PL或者右子树PR,此时直接令PL 或PR直接成为其双亲结点*f的左子树即可
f->lchild=p->lchild;(或f->lchild=p->rchild)
3)*p结点左右子树均不为空:
总结:①缺右子树用左孩子填补;②缺左子树用右孩子填补;③在左子树上找中序最后一个结点填补
B+树和B树的区别:!!!B+树是重点
一棵m阶的B+树和m阶的B树的差异:
1)有n棵子树的结点中含有n个关键字
2)所有的叶子结点中包含全部关键字的信息,以及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接
3)所有的非终端节点可以看成是索引部分,结点中仅含有其子树(根节点)中的最大(或最小)关键字
哈希表查找!!!重点
构造方法:1)数字分析法;2)平方取中法;3)折叠法;4)除留余数法
处理冲突的方法:1)开放地址法
Hi=(H(key)+di)%m(H(key)为散列函数,m为散列表表长,di为增量序列)
根据di的不同分为三种探测方法:
①线性探测法:di=1,2,3......
将散列表假想成一个循环表,发生冲突的时候,从冲突地址的下一单元顺序寻找空单元,如果到最后一个位置也没有找到空单元,则回到表头开始继续查找,直到找到一个空位,把此元素放入此空位中,如果找不到空位,说明散列表已满,需要进行溢出处理
②二次探测法:di=1²,-1²,2²,-2².......+k²,-k²(k<=m/2)
③伪随机探测法:di=伪随机数序列
2)链地址法:把具有相同散列地址的记录放在同一个单链表中,称为“同义词链表”
PTA上的编程题Hashing就是用了哈希表法
1.先贴上完整代码:


1 #include<iostream> 2 #include<cmath> 3 using namespace std; 4 5 int largestPrime(int MSize); 6 7 int main() 8 { 9 int MSize,N;//MSize是哈希表的表长,N是将要插入N个数 10 cin >> MSize >> N; 11 int prime = largestPrime(MSize); 12 bool *Hashtable ;//将表中所有地址置为不冲突 13 Hashtable = new bool[MSize+1]; 14 for(int i =0;i<=MSize;i++) 15 Hashtable[i] = false; 16 17 int num,H;//准备插入的正整数 num,准备插入的num的地址H 18 for(int i = 0;i < N;i++) 19 { 20 cin >> num; 21 int j = 0; //这个是你用来解决冲突的,j*j,开始肯定是0 22 int flag = 0; //这个是打标记用的,表示已经找到空位插入了,如果没找到,那么就要返回 - 23 H = num % prime; 24 int temp = H; //用来保存最初的下标 25 while(1) 26 { 27 if(j >= prime) break; //如果平方解决冲突的 j超过了素数 那就已经找不到空位了,退出 28 if(Hashtable[H] == false)//如果这个H下标里是空位,那就加进去 29 { 30 Hashtable[H] = true; 31 if (i > 0) cout << " "; 32 cout << H; 33 flag = 1; 34 break; 35 } 36 H = (temp + j*j) % prime; //每一次的H下标,都以上一次的结果H坐标来处理 37 j++; //如果不是空位,就j++ 38 } 39 if(flag == 1) continue; 40 if(i > 0) cout << " "; 41 cout<< "-"; 42 } 43 cout << endl; 44 return 0; 45 } 46 47 int largestPrime(int MSize) 48 {//找到最大的质数 49 if(MSize<=2) return 2;//如果表长为1或2,即最大质数就是2 50 bool Find = true; 51 int i; 52 while(Find) 53 { 54 55 int Prime = sqrt(MSize);//以表长的算术平方根为界限 56 for(i = 2;i<=Prime&&MSize%i !=0;i++){}; 57 //从最小质数2开始,确保表长不能整除i,不然的话就不是质数,直到最后找到最大的质数 58 if(i > Prime) Find = false;//若最后得到的i 大于 MSize的算术平方根就不行 59 else MSize++; 60 } 61 62 return MSize;//返回最大的质数 63 }
2.代码思路:
在hashing中①先是要找到hashing表表长的最大质数,从而才可以运用二次探测法
1 int largestPrime(int MSize) 2 {//找到最大的质数 3 if(MSize<=2) return 2;//如果表长为1或2,即最大质数就是2 4 bool Find = true; 5 int i; 6 while(Find) 7 { 8 9 int Prime = sqrt(MSize);//以表长的算术平方根为界限 10 for(i = 2;i<=Prime&&MSize%i !=0;i++){}; 11 //从最小质数2开始,确保表长不能整除i,不然的话就不是质数,直到最后找到最大的质数 12 if(i > Prime) Find = false;//若最后得到的i 大于 MSize的算术平方根就不行 13 else MSize++; 14 } 15 16 return MSize;//返回最大的质数 17 }
②在找到最大的质数后,就要开始构造我的哈希表了 也是在这里遇到了很大的困难
一开始的时候我的代码是这样的
1 #include<iostream> 2 #include<math.h> 3 using namespace std; 4 5 int largestPrime(int MSize); 6 7 int main() 8 { 9 int MSize,N;//MSize是哈希表的表长,N是将要插入N个数 10 cin >> MSize >> N; 11 int prime = largestPrime(MSize); 12 bool *Hashtable ;//将表中所有地址置为不冲突 13 Hashtable = new bool[MSize+1]; 14 for(int i =0;i<=N;i++) 15 { 16 Hashtable[i] = false; 17 } 18 int num,H;//准备插入的正整数 num,准备插入的num的地址H 19 for (int i = 0;i < N;i++) 20 { 21 cin >> num; 22 int j = 0; 23 H = (num + j*j) % prime; 24 if(!Hashtable[H] && H <=N) 25 { 26 Hashtable[H] = true;//将该地址置为已有元素,为下一元素的冲突地址 27 if (i > 0) cout << " "; 28 cout << H; 29 j++; 30 } 31 if(Hashtable[H] && j ==0) 32 { 33 if(i > 0) cout << " "; 34 cout<< "-"; 35 36 } 37 38 } 39 cout << endl; 40 return 0; 41 } 42 43 int largestPrime(int MSize) 44 {//找到最大的质数 45 if(MSize<=2) return 2;//如果表长为1或2,即最大质数就是2 46 bool Find = true; 47 int i; 48 while(Find) 49 { 50 51 int Prime = sqrt(MSize);//以表长的算术平方根为界限 52 for(i = 2;i<=Prime&&MSize%i !=0;i++){}; 53 //从最小质数2开始,确保表长不能整除i,不然的话就不是质数,直到最后找到最大的质数 54 if(i > Prime) Find = false;//若最后得到的i 大于 MSize的算术平方根就不行 55 else MSize++; 56 } 57 58 return MSize;//返回最大的质数 59 }
1 int main() 2 { 3 int MSize,N;//MSize是哈希表的表长,N是将要插入N个数 4 cin >> MSize >> N; 5 int prime = largestPrime(MSize); 6 bool *Hashtable ;//将表中所有地址置为不冲突 7 Hashtable = new bool[MSize+1]; 8 for(int i =0;i<=N;i++) 9 { 10 Hashtable[i] = false; 11 } 12 int num,H;//准备插入的正整数 num,准备插入的num的地址H 13 for (int i = 0;i < N;i++) 14 { 15 cin >> num; 16 int j = 0; 17 H = (num + j*j) % prime; 18 if(!Hashtable[H] && H <=N) 19 { 20 Hashtable[H] = true;//将该地址置为已有元素,为下一元素的冲突地址 21 if (i > 0) cout << " "; 22 cout << H; 23 j++; 24 } 25 if(Hashtable[H] && j ==0) 26 { 27 if(i > 0) cout << " "; 28 cout<< "-"; 29 30 } 31 32 } 33 cout << endl; 34 return 0; 35 }
这个样子的main函数,虽然在Dev里面运行出来是正确 的
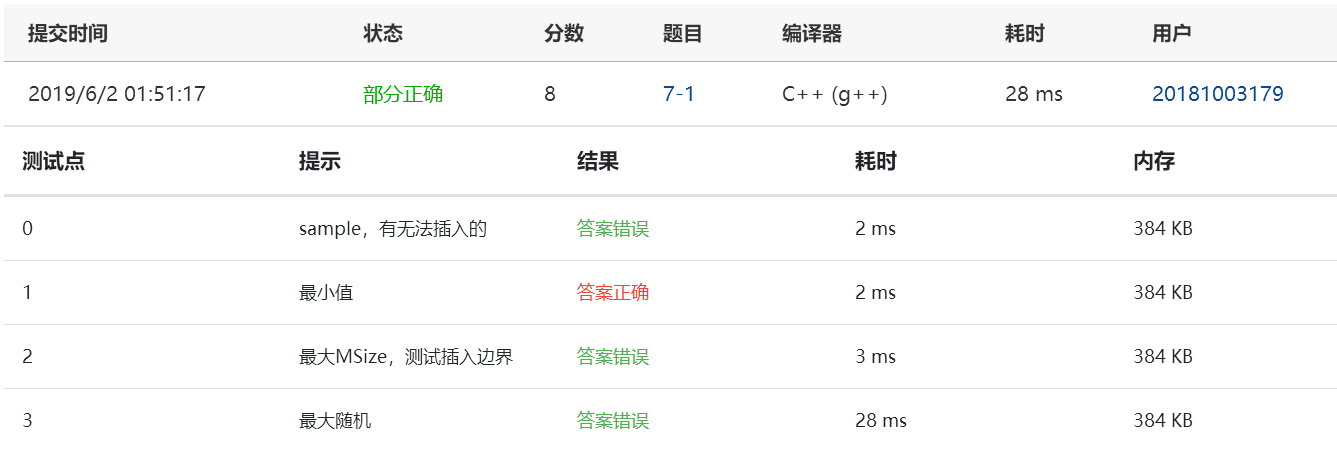
但是实际上在PTA上是只有一个测试点通过了的
后面我求助了班上的一位大佬,在他的指导下我明白了,
原因是出在了我第一次的main函数里面,并没有对冲突进行处理,我的j相当于是没有用的,

我相当于是只对第一次出现的冲突做出了处理,在j==0和该地址被占据后,就直接输出“-”了,但是还需要对下一个地址进行查找看看是否还是冲突
因此我是缺少了一步for循环,需要多一步for循环,才可以在发生冲突的时候,继续探测下一个非冲突地址
下面是正确的main函数
1 int main() 2 { 3 int MSize,N;//MSize是哈希表的表长,N是将要插入N个数 4 cin >> MSize >> N; 5 int prime = largestPrime(MSize); 6 bool *Hashtable ;//将表中所有地址置为不冲突 7 Hashtable = new bool[MSize+1]; 8 for(int i =0;i<=MSize;i++) 9 Hashtable[i] = false; 10 11 int num,H;//准备插入的正整数 num,准备插入的num的地址H 12 for(int i = 0;i < N;i++) 13 { 14 cin >> num; 15 int j = 0; //这个是你用来解决冲突的,j*j,开始肯定是0 16 int flag = 0; //这个是打标记用的,表示已经找到空位插入了,如果没找到,那么就要返回 - 17 H = num % prime; 18 int temp = H; //用来保存最初的下标 19 while(1) 20 { 21 if(j >= prime) break; //如果平方解决冲突的 j超过了素数 那就已经找不到空位了,退出 22 if(Hashtable[H] == false)//如果这个H下标里是空位,那就加进去 23 { 24 Hashtable[H] = true; 25 if (i > 0) cout << " "; 26 cout << H; 27 flag = 1; 28 break; 29 } 30 H = (temp + j*j) % prime; //每一次的H下标,都以上一次的结果H坐标来处理 31 j++; //如果不是空位,就j++ 32 } 33 if(flag == 1) continue; 34 if(i > 0) cout << " "; 35 cout<< "-"; 36 } 37 cout << endl; 38 return 0; 39 }
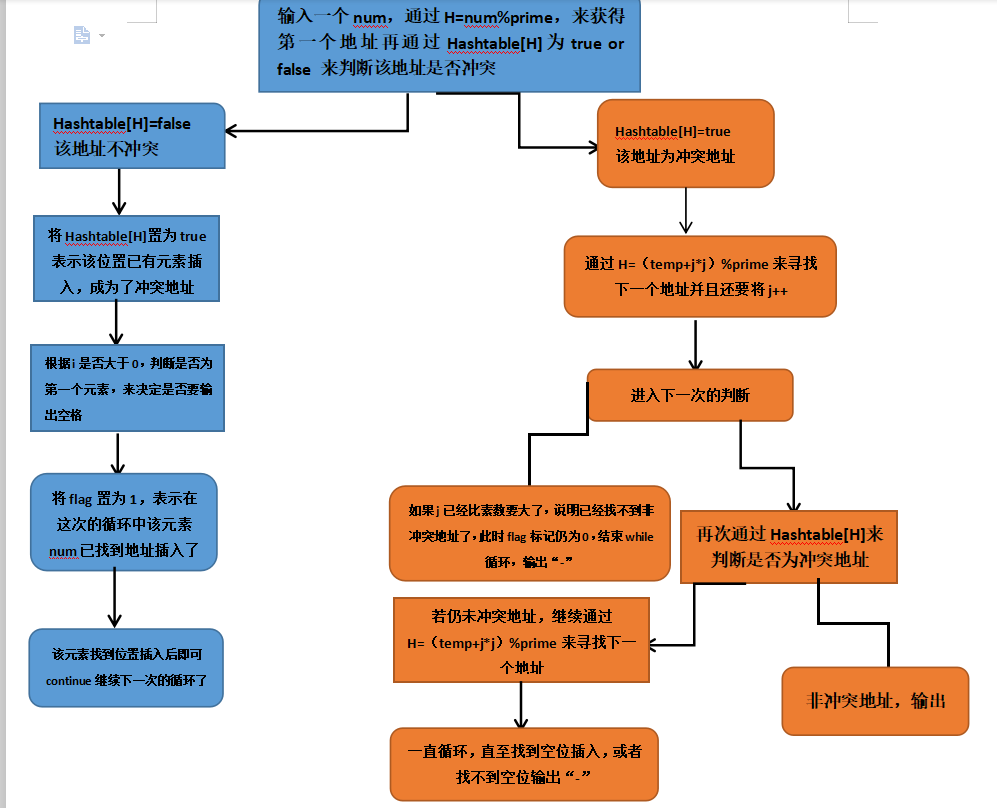
以下是对冲突处理的图解
总结:
在这一章的学习中,我觉得我学得还挺认真的,不像上一章一样,上一章,上课的时候总是很困,很多重要的知识点都没理解,导致小测也考得很差,这一章在写pta和博客园前我把书认认真真的看了一遍,然后在写pta时,虽然还是会先参考了一次网上的代码,但是和之前不一样,这次我只是参考了大部分代码的思路,然后按自己的理解写了和网上大多不大一样的程序,虽然一道Hashing题就写了我一天,最后还是在同学的帮助下完成的,但是还是值得的!
上次的目标完成的差不多了,这次的目标是,每天按照计划开始复习数据结构,准备好期末的备考
最后我想说一下写博客园这一个学期以来的感受,其实刚开始我的确不知道该怎么写博客园,转变是在有一次第四章吧,我觉得我写的很认真,但是助教说我的格式不大好,我才去参考了其他同学的博客园,后来复习的确,我跟别人的差距还很大,这次写之前我也看了班上几个同学的博客园,发现他们的知识点总结还有题解都很详细。而且他们的图解大多都是用框架的形式,不像我之前是手画图在复制到电脑,就会显得整个界面很乱,所以这次我也采取了这种方法,感觉还不错。
这次是倒数第二次的博客园了,下次就是最后一次,我觉得我这学期在写博客园的过程中,还是有进步的,第八章继续努力,下次写要写得最好!!
要期末考了,要好好复习数据结构啊啊啊!!!!!!