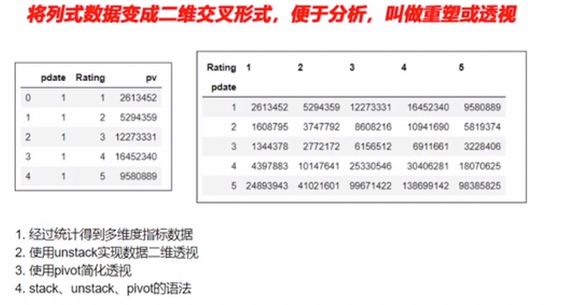
1. 经过统计得到多维度指标数据
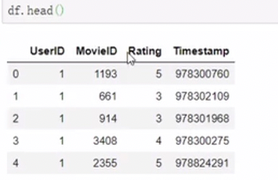
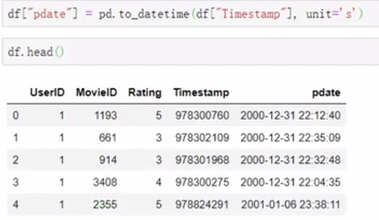
时间转化 转化后之后可以利用时间对象获取更多的数据
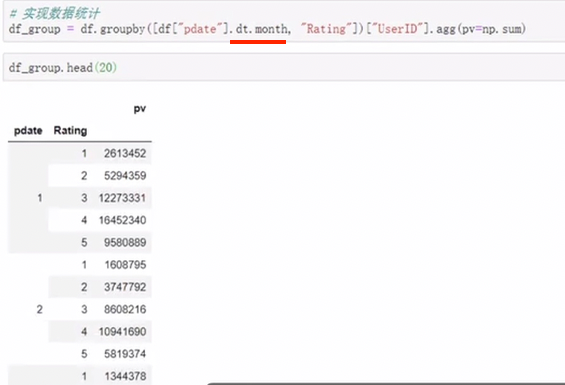
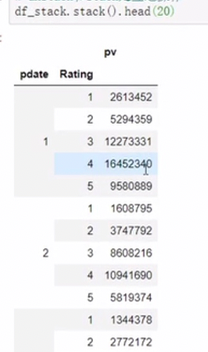
2. stack df.stack(level=-1, dropna=True)
level 代表多层索引的最内层,可以通过 0 1 2等制定多层索引的对应层
dropna 是否删除空值
将column变为index 类似把横放的数变成竖放 分层索引会增加
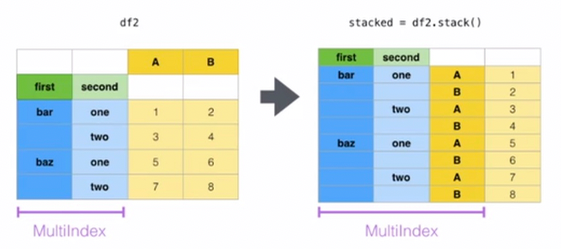
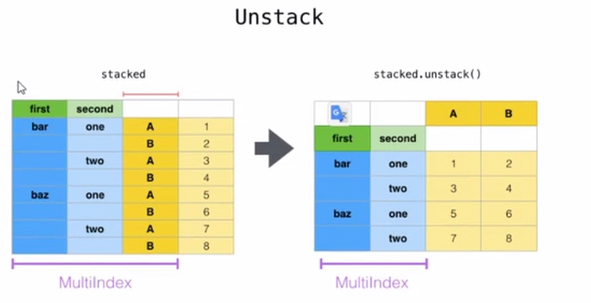
3. unstack df.unstack(level=-1, fill_value=None)
将index变为column,把竖放的书横着放
使用unstack 实现数据的二维透视
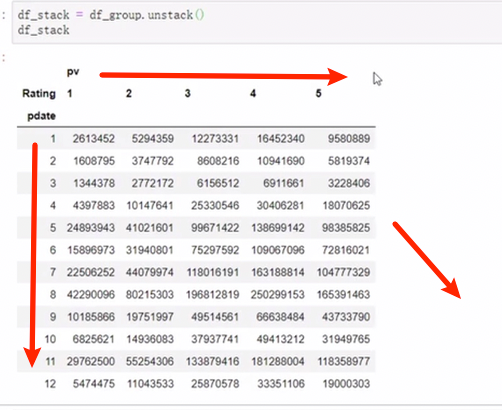
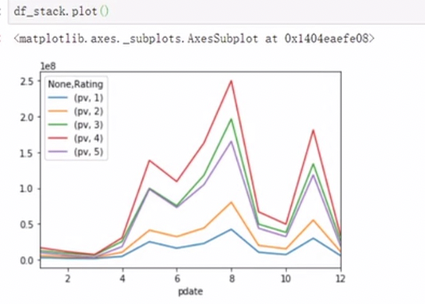
相较于关系型数据库中的关系数据,每个数据都有了一个做表,更容易绘图
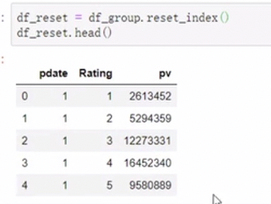
使用reset_index
stack unstack 为互逆操作
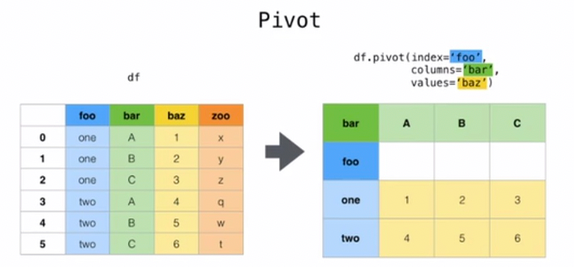
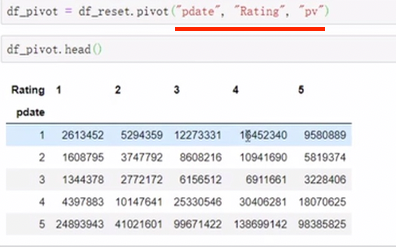
4. pivot df.pivot(index=None, columns=None,values=None) 制定index columns value实现二维透视表
相当于对df使用了set_index创建分层索引,然后调用了unstack