前言
- 很久以前,生活中使用c#和java分别写过网页游戏外挂,通过语言中内置的方式进行爬取数据,并发送新的指令,非常有意思,既能研究爬虫相关技术又能实践在休闲生活中。
- 后面也有在工作中,定时爬取中国天气预报官方信息,提供给前端主页显示天气信息。
需求
- 有朋友需要帮忙收集豆瓣读书中的书籍信息,根据传入的书丛地址,获取书丛中的书籍的信息、封面,并存到excel.如果没有这种自动工具,那么朋友就需要几个通宵才能完成,而且是非常非常重复的事,我一听,我就想起了以前做过的,就答应下来了。
处理思路
-
虽然答应,但也不会像以前那样说干就干,重复造轮子的事,没有意义,第一个想到 ,现在这种爬虫类的软件或半自动的软件很多,直接借用巨人的肩膀不是又快又好,结果发现爬是可以爬,但满足不了需求。
-
研究了一些自动的或半自动的工具后(也需要懂一些html方面的选择表达式的基础,对于程序员来讲,还是比较简单的),发现数据是出来了,要把这样的数据清洗成excel的格式,基本上都是需要人工操作,对于不懂技术的朋友来讲,这是一件无法逾越的坑。特别还有封面这种图片格式的需求。。。
-
查了一下资料,现在爬虫类的,太多太多Python相关的资料了,不得感触Python的发展迅猛。虽然我也会写一些简单的,但要抓取数据,清洗数据,生成EXCEL,用不熟悉的语言,会浪费大量的时间在语法研究上面。
-
所以看到 一个在多个语言都支持的组件
selenium,它有多个语言版本的组件,兼容不同的浏览器。这个东西非常符合我的胃口,既兼容多个语言,又兼容不同的浏览器。此组件的自身定位设计太妙了,很有生命力。 -
然后想直接找一下selenium的现成解析豆瓣读书的java工程来改造,发生都已经不能解析目前的豆瓣读书,看来豆瓣读书也在不断的迭代,之前格式已经变了,到了这一步,基本上不用想了,可以开始自己动手搭建全新工程
实践
源代码
首先,什么都不说,先上源代码地址,奉上github地址
https://github.com/riso-jay/riso/tree/master/riso-parent/riso-web-crawler
或下载打成zip的附件:https://download.csdn.net/download/vipshop_fin_dev/12536676
使用方式:
在/riso-parent/riso-web-crawler/jar 文件夹有打好包的jar及批处理(只要jdk是1.8以上就可以直接运行)
附上二种不同的豆瓣读书的丛书来源页,供测试
推荐列表页 https://www.douban.com/doulist/1257960 下面是生成的效果

丛书列表页https://book.douban.com/series/46192 下面是生成的效果

selenium
selenium 的使用示例,这里不展开讲,上面有源码可以自己看,讲一些印象深刻部分
- 关于浏览器可见的不生效问题
我选择的是chrome的驱动,在使用浏览器驱动时,有些坑,网上没有可用的解决方案。
这里我发现一个很意思的地方,selenium我用的是3.9.1 版本,然后我按当前chrome浏览器版本( 75.0.3770.142)去选择下载(75.0.3770.140),发生在selenium控制浏览器可见时,会不起作用,后面换了几个版本,用(70.0.3538.97)是可以控制 浏览器可见不可见的。
附上参考代码:
System.setProperty("webdriver.chrome.driver", chromedriverFilePath);
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless"); //无浏览器模式
WebDriver driver = new ChromeDriver(options);
- 关于网页中的图片处理
这个之前没有弄过,想用传统的java 用 URL或apache的httpclient的方式抓取图片,熟悉的方式快速解决,忽视了豆瓣是https的协议,行不通了,发现selenium有对指定4轴截图,通过WebElement可以简单获取,完美的解决图片问题 ,还不限定对文件的格式及动态网页一些特殊性。非常不错的功能
附上参考代码:
/**
* 通过webElement获取图片文件
* @param driver
* @param ele
* @return
*/
private File getPicFile(WebDriver driver, WebElement ele) throws IOException {
File screenshot = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
// Get entire page screenshot
BufferedImage fullImg = ImageIO.read(screenshot);
// Get the location of element on the page
org.openqa.selenium.Point point = ele.getLocation();
// Get width and height of the element
int eleWidth = ele.getSize().getWidth();
int eleHeight = ele.getSize().getHeight();
// Crop the entire page screenshot to get only element screenshot
BufferedImage eleScreenshot = fullImg.getSubimage(point.getX(), point.getY(), eleWidth, eleHeight);
ImageIO.write(eleScreenshot, "jpg", screenshot);
return screenshot;
}
注意:
chrome官网是访问不了,这里有一个淘宝的仓库可用: http://npm.taobao.org/mirrors/chromedriver/
设计模式
-
个人觉的,不管是大项目,还是小项目,优雅的代码是让人赏心悦目的,如果时间不够,也不能将代码的框架设计给省略 。有句俗话说的好,代码往往有华丽的外表,却有一个垃圾的内心。怎么理解这句话呢:“你可以有很烂的代码,但对外的接口一定要够好。因为你再烂,你也可以在后面迭代它,去修正它,但抛出来的接口已经不能随便修改,很可能伴随一世。”,这也就说明了对代码不同层次的优化先处理方式,代码的整体框架是很重要的。
-
所以我也非常重视设计模式,因为设计模式是一个将抽象的解决方案落地的描述。这里我主要使用了设计模式: 策略模式及一些基础的面向对象手段继承等方式(工厂和单例就 不用说了,虽然我没有使用spring,但这个已经溶入骨子里了)。来解决对于不同网页的爬取解析不同逻辑的地方,这里主要是处理豆瓣读书详情页的上级多种来源(目前可以感知到 有丛书和推荐)
下面贴一下,工程结构及策略实现的关键代码
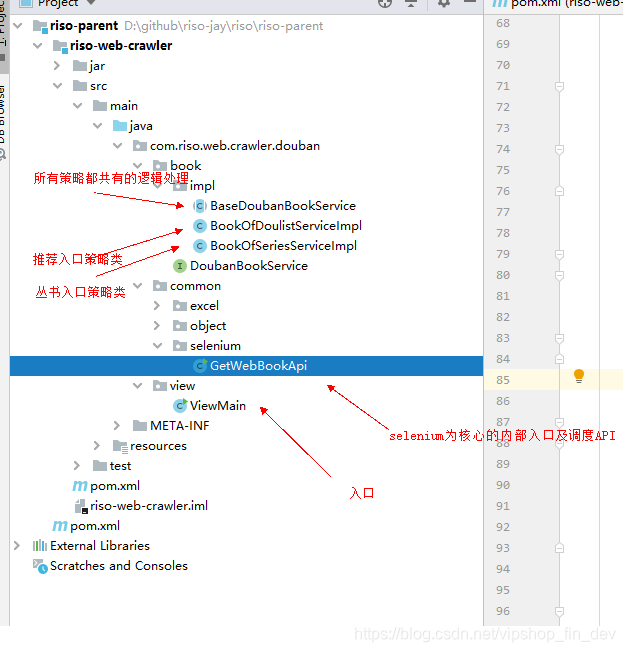
策略接口:
/**
* 豆辨书解析接口
* @author: jie01.zhu
* @Date: 2020/6/15
*/
public interface DoubanBookService {
/**
* 是否需要处理
* @param url
* @return
*/
boolean isProcess(String url);
/**
* 获取分页个性化参数
* @param pageNum 分页数量
* @return
*/
String getPageStr(int pageNum);
/**
* 通过列表首页获取书的集合信息
* @param driver
* @param url
* @return
*/
List<DoubanBook> getDoubanBookListByTopPage(WebDriver driver, String url);
}
豆瓣读书推荐页的策略实现
public class BookOfDoulistServiceImpl extends BaseDoubanBookService implements DoubanBookService {
private final String INDEX_STR = "https://www.douban.com/doulist/";
@Override
public boolean isProcess(String url) {
if (url.indexOf(INDEX_STR) == -1) {
return false;
}
return true;
}
/**
* doulist的分页是按25的倍数翻页的
* @param pageNum 分页数量
* @return
*/
@Override
public String getPageStr(int pageNum) {
return "start=" + ((pageNum - 1) * 25);
}
@Override
public List<DoubanBook> getDoubanBookListByTopPage(WebDriver driver, String url) {
。。。后面省略推荐的具体代码解析逻辑
豆瓣读书书丛页的策略实现
public class BookOfSeriesServiceImpl extends BaseDoubanBookService implements DoubanBookService {
private final String INDEX_STR = "https://book.douban.com/series/";
@Override
public boolean isProcess(String url) {
if (url.indexOf(INDEX_STR) == -1) {
return false;
}
return true;
}
/**
* Series 是按页数简单翻页的
* @param pageNum 分页数量
* @return
*/
@Override
public String getPageStr(int pageNum) {
return "page=" + pageNum;
}
@Override
public List<DoubanBook> getDoubanBookListByTopPage(WebDriver driver, String url) {
。。。后面省略推荐的具体代码解析逻辑
通过这样的拆分,我们用代码分层拆分什么是组件,什么是前端入口,什么是策略,基本上可以保证业务的变化不会对结构造成重大的结调和冲击。
访问入口
最后为什么要再说一下访问入口,因为我真的被 javax.swing给恶心到 了,下面的如此简单的界面,写起代码非常麻烦。但从用户的角度思考,它确实是最轻量级的。我不想使用网页的方式,这样太笨重了(需要再拉一个应用服务器,配合脚本弹出一个网页)。

再看一下swing的流式界面开发代码
GetWebBookApi getWebBookApi = new GetWebBookApi();
JFrame jf = new JFrame("豆瓣书单抓取");
jf.setDefaultCloseOperation(WindowConstants.EXIT_ON_CLOSE);
// 创建内容面板容器
JPanel jPanel = new JPanel();
// 创建分组布局,并关联容器
GroupLayout layout = new GroupLayout(jPanel);
// 设置容器的布局
jPanel.setLayout(layout);
JLabel urlJLabel = null;
urlJLabel = new JLabel();
urlJLabel.setText("豆瓣丛书入口地址:");
urlJLabel.setFont(new Font(null, Font.PLAIN, 18)); // 设置字体,null 表示使用默认字体
// 创建文本框,指定可见列数为8列
final JTextField urlTextField = new JTextField(50);
urlTextField.setText("https://book.douban.com/series/46192");
urlTextField.setFont(new Font(null, Font.PLAIN, 18));
JLabel chromedriverFilePathJLabel = new JLabel();
chromedriverFilePathJLabel.setText("chrome浏览器驱动文件地址:");
chromedriverFilePathJLabel.setFont(new Font(null, Font.PLAIN, 18)); // 设置字体,null 表示使用默认字体
jPanel.add(chromedriverFilePathJLabel);
final JTextField chromedriverFilePathTextField = new JTextField(50);
chromedriverFilePathTextField.setFont(new Font(null, Font.PLAIN, 18));
chromedriverFilePathTextField.setText("c:/chromedriver.exe");
jPanel.add(chromedriverFilePathTextField);
JLabel fileLocationPathJLabel = new JLabel();
fileLocationPathJLabel.setText("excel生成目件夹(必须存在):");
fileLocationPathJLabel.setFont(new Font(null, Font.PLAIN, 18)); // 设置字体,null 表示使用默认字体
jPanel.add(fileLocationPathJLabel);
final JTextField fileLocationPathTextField = new JTextField(50);
fileLocationPathTextField.setFont(new Font(null, Font.PLAIN, 18));
fileLocationPathTextField.setText("c:/");
jPanel.add(fileLocationPathTextField);
// 创建一个按钮,点击后获取文本框中的文本
JButton btn = new JButton("抓取");
btn.setFont(new Font(null, Font.PLAIN, 18));
btn.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
System.out.println("提交: " + urlTextField.getText());
try {
getWebBookApi.getWebStart(urlTextField.getText(), chromedriverFilePathTextField.getText(),
fileLocationPathTextField.getText());
} catch (Exception ex) {
log.error(ex.getMessage(), ex);
JOptionPane.showMessageDialog(jPanel, ex.getMessage(), "发生错误", JOptionPane.WARNING_MESSAGE);
} finally {
System.exit(0);
}
}
});
// 自动创建组件之间的间隙
layout.setAutoCreateGaps(true);
// 自动创建容器与触到容器边框的组件之间的间隙
layout.setAutoCreateContainerGaps(true);
/*
* 水平组(仅确定 X 轴方向的坐标/排列方式)
*
* 水平串行: 水平排列(左右排列)
* 水平并行: 垂直排列(上下排列)
*/
// 水平并行(上下) btn01 和 btn02
GroupLayout.ParallelGroup hParalGroup01 = layout.createParallelGroup().addComponent(urlJLabel)
.addComponent(chromedriverFilePathJLabel).addComponent(fileLocationPathJLabel);
// 水平并行(上下)btn03 和 btn04
GroupLayout.ParallelGroup hParalGroup02 = layout.createParallelGroup().addComponent(urlTextField)
.addComponent(chromedriverFilePathTextField).addComponent(fileLocationPathTextField);
// 水平串行(左右)hParalGroup01 和 hParalGroup02
GroupLayout.SequentialGroup hSeqGroup = layout.createSequentialGroup().addGroup(hParalGroup01)
.addGroup(hParalGroup02);
// 水平并行(上下)hSeqGroup 和 btn05
GroupLayout.ParallelGroup hParalGroup = layout.createParallelGroup().addGroup(hSeqGroup)
.addComponent(btn, GroupLayout.Alignment.CENTER);
layout.setHorizontalGroup(hParalGroup); // 指定布局的 水平组(水平坐标)
/*
* 垂直组(仅确定 Y 轴方向的坐标/排列方式)
*
* 垂直串行: 垂直排列(上下排列)
* 垂直并行: 水平排列(左右排列)
*/
// 垂直并行(左右)btn01 和 btn03
GroupLayout.ParallelGroup vParalGroup01 = layout.createParallelGroup().addComponent(urlJLabel)
.addComponent(urlTextField);
// 垂直并行(左右)btn02 和 btn04
GroupLayout.ParallelGroup vParalGroup02 = layout.createParallelGroup().addComponent(chromedriverFilePathJLabel)
.addComponent(chromedriverFilePathTextField);
// 垂直并行(左右)btn02 和 btn04
GroupLayout.ParallelGroup vParalGroup03 = layout.createParallelGroup().addComponent(fileLocationPathJLabel)
.addComponent(fileLocationPathTextField);
// 垂直串行(上下)vParalGroup01, vParalGroup02 和 btn05
GroupLayout.SequentialGroup vSeqGroup = layout.createSequentialGroup().addGroup(vParalGroup01)
.addGroup(vParalGroup02).addGroup(vParalGroup03).addComponent(btn);
layout.setVerticalGroup(vSeqGroup); // 指定布局的 垂直组(垂直坐标)
jf.setContentPane(jPanel);
jf.pack();
jf.setLocationRelativeTo(null);
jf.setVisible(true);
最后附上我之前写的博文入口:
[1] https://blog.csdn.net/vipshop_fin_dev/article/details/89303458
[2] https://blog.csdn.net/vipshop_fin_dev/article/details/85323076
[3] https://blog.csdn.net/vipshop_fin_dev/article/details/85239099
[4] https://blog.csdn.net/vipshop_fin_dev/article/details/79618067
[5] https://blog.csdn.net/vipshop_fin_dev/article/details/79313432
朱杰
2020-06-19