1.利用AOP实现Redis缓存
1.1为什么使用AOP
1).业务代码与Redis缓存服务,紧紧的耦合在一起. 不方便后期维护.
2).如果采用下列代码的形式添加缓存机制,则不方便.每次使用缓存时,都需要按照缓存的机制重新执行业务代码. 显得特别的繁琐.
3).利用AOP的形式实现该操作.!!
@SuppressWarnings("unchecked")
@Override
public List<EasyUITree> findItemCatCache(Long parentId) {
String key = "ITEM_CAT_PARENTID_"+parentId;
List<EasyUITree> treeList = new ArrayList<>();
//1.判断redis中是否有记录
if(jedis.exists(key)) {
//表示redis中有记录.
String json = jedis.get(key);
treeList =
ObjectMapperUtil.toObj(json, treeList.getClass());
System.out.println("实现redis缓存查询");
}else {
//redis中没有记录,需要先查询数据库.
treeList = findItemCatList(parentId);
//将数据库记录转化为json之后保存到redis中
String json = ObjectMapperUtil.toJSON(treeList);
jedis.set(key, json);
System.out.println("第一次查询数据库!!!!!");
}
return treeList;
}
1.2AOP复习
1.2.1 AOP说明
AOP: 对原有的方法进行扩展,可以将重复的事情,但是右不得不做的事情,放到AOP中执行.可以减少代码的耦合性.降低维护的成本.

1.3 AOP入门案例
@Component //将该类交给Spring容器管理
@Aspect //标识我是一个切面
public class CacheAOP {
//切面 = 切入点表达式 + 通知方法
//可以理解为 就是一个if判断
@Pointcut("bean(itemCatServiceImpl)") //只对特定的某个类有效
//@Pointcut("within(com.jt.*.ItemCatServiceImpl)")
//拦截com.jt.service下边的所有类的所有方法并且所有的参数
//@Pointcut("execution(* com.jt.service..*.*(..))")
public void joinPoint() {
}
/**
* 记录程序的执行状态 获取哪个类,哪个方法执行的
*/
@Before("joinPoint()")
public void before(JoinPoint joinPoint) {
Date date = new Date();
String strDate = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date);
String typeName = joinPoint.getSignature().getDeclaringTypeName();
String methodName = joinPoint.getSignature().getName();
System.out.println("我是前置通知");
System.out.println(strDate+":"+typeName+":"+methodName);
}
/*定义环绕通知 控制程序的执行过程*/
@Around("joinPoint()")
public Object around(ProceedingJoinPoint joinPoint) {
System.out.println("我是环绕通知开始");
Object result = null;
try {
result = joinPoint.proceed(); //执行真实的目标方法
} catch (Throwable e) {
e.printStackTrace();
throw new RuntimeException(e);
}
System.out.println("我是环绕通知结束");
return result;
}
/**
* 通知类型:
* 1.前置通知: 在目标方法执行之前执行
* 2.后置通知: 在目标方法执行之后执行
* 3.异常通知: 在目标方法执行之后发生异常时执行
* 4.最终通知: 在程序执行最后执行的通知方法
* 5.环绕通知: 在目标方法执行前后都要执行的通知方法.
*
* 记忆:
* 1.如果要对程序的执行的流程进行控制,则首选环绕通知. 最重要的通知方法
* 2.如果需要对程序的执行的状态进行记录,则使用其他四大通知类型.
*
*
* 切入点表达式:
* bean= Spring容器管理的对象称之为bean
* 1. bean(bean的ID) 只能拦截某个bean的操作.执行通知方法 1个
* 2. within(包名.类名) 按类匹配,类可以有多个
* //上述的切入点表达式控制的粒度较粗 只能控制到类级别.
*
* //可以控制到方法参数级别
* 3. execution(返回值类型 包名.类名.方法名(参数列表)) 控制粒度较细
* 4. annotation(包名.注解名) 按照指定的注解进行匹配.
*
*/
}
}
1.4 AOP实现redis缓存
1.4.1 设计思路
1.自定义缓存注解 CacheFind 如果需要缓存,则添加该注解即可. 在注解中可以指定用户的key.
2.如果需要使用Redis进行缓存的处理,必须定义key-value, value就是方法的返回值结果.
3.之后利用AOP中的环绕通知的思想进行缓存的操作.
1.4.2 自定义注解CacheFind
根据规则,在jt-common中添加自定义注解.CacheFind.
@Retention(RetentionPolicy.RUNTIME) //运行期有效
@Target(ElementType.METHOD) //该注解对方法有效
public @interface CacheFind {
public String key(); //定义用户的key
public int seconds() default 0; //定义超时时间
}
1.4.3 添加缓存注解
@CacheFind(key="ITEM_CAT_PARENTID")
@Override
public List<EasyUITree> findItemCatList(Long parentId) {
//1.先获取所有的一级商品分类信息.
List<ItemCat> itemCatList = findItemCatListByParentId(parentId);
//2.将CartList转化为VOlist
List<EasyUITree> treeList = new ArrayList<>(itemCatList.size());
for (ItemCat itemCat : itemCatList) {
Long id = itemCat.getId();
String text = itemCat.getName();
//如果是父级则默认关闭,如果是子级则默认打开.
String state = itemCat.getIsParent()?"closed":"open";
EasyUITree easyUITree = new EasyUITree(id, text, state);
treeList.add(easyUITree);
}
return treeList;
}
1.4.4 AOP实现Redis缓存
@Component //将该类交给Spring容器管理
@Aspect //标识我是一个切面
public class CacheAOP {
@Autowired
private Jedis jedis;
/**
* 根据@CacheFind注解,实现缓存控制
*
* 1.切入点表达式 "@annotation(cacheFind)" 只拦截cacheFind注解
* 2.通知方法如何控制
*
* 缓存实现的策略:
* 1.拼接key 用户输入的内容 + 动态参数
*/
@SuppressWarnings("unchecked")
@Around("@annotation(cacheFind)")
public Object cacheAround(ProceedingJoinPoint joinPoint,CacheFind cacheFind) {
String key = cacheFind.key();
String strArg0 = joinPoint.getArgs()[0].toString(); //获取其中的第一个参数
key = key +"::" + strArg0;
Object result = null;
//1.判断redis中是否有该记录 没有 需要查询数据 有 直接返回数据
try {
if(jedis.exists(key)) { //redis中有结果
String json = jedis.get(key); //获取redis中的记录.
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();
Class returnClass =methodSignature.getReturnType();
//动态的获取目标方法的返回值类型.
result = ObjectMapperUtil.toObj(json, returnClass);
System.out.println("查询AOP缓存");
}else { //表示redis中没有记录,查询数据库
result = joinPoint.proceed();
String json = ObjectMapperUtil.toJSON(result);
int seconds = cacheFind.seconds();
System.out.println("AOP执行数据库查询");
if(seconds>0)
jedis.setex(key, seconds, json); //添加超时时间
else
jedis.set(key, json); //不需要超时时间
}
} catch (Throwable e) {
// TODO Auto-generated catch block
e.printStackTrace();
throw new RuntimeException(e);
}
return result;
}
//切面 = 切入点表达式 + 通知方法
//可以理解为 就是一个if判断
//@Pointcut("bean(itemCatServiceImpl)") //只对特定的某个类有效
//@Pointcut("within(com.jt.*.ItemCatServiceImpl)")
//拦截com.jt.service下边的所有类的所有方法并且所有的参数
//@Pointcut("execution(* com.jt.service..*.*(..))")
public void joinPoint() {
}
/**
* 记录程序的执行状态 获取哪个类,哪个方法执行的
*/
//@Before("joinPoint()")
public void before(JoinPoint joinPoint) {
Date date = new Date();
String strDate = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date);
String typeName = joinPoint.getSignature().getDeclaringTypeName();
String methodName = joinPoint.getSignature().getName();
System.out.println("我是前置通知");
System.out.println(strDate+":"+typeName+":"+methodName);
}
/*定义环绕通知 控制程序的执行过程*/
//@Around("joinPoint()")
public Object around(ProceedingJoinPoint joinPoint) {
System.out.println("我是环绕通知开始");
Object result = null;
try {
result = joinPoint.proceed(); //执行真实的目标方法
} catch (Throwable e) {
e.printStackTrace();
throw new RuntimeException(e);
}
System.out.println("我是环绕通知结束");
return result;
}
/**
* 通知类型:
* 1.前置通知: 在目标方法执行之前执行
* 2.后置通知: 在目标方法执行之后执行
* 3.异常通知: 在目标方法执行之后发生异常时执行
* 4.最终通知: 在程序执行最后执行的通知方法
* 5.环绕通知: 在目标方法执行前后都要执行的通知方法.
*
* 记忆:
* 1.如果要对程序的执行的流程进行控制,则首选环绕通知. 最重要的通知方法
* 2.如果需要对程序的执行的状态进行记录,则使用其他四大通知类型.
*
*
* 切入点表达式:
* bean= Spring容器管理的对象称之为bean
* 1. bean(bean的ID) 只能拦截某个bean的操作.执行通知方法 1个
* 2. within(包名.类名) 按类匹配,类可以有多个
* //上述的切入点表达式控制的粒度较粗 只能控制到类级别.
*
* //可以控制到方法参数级别
* 3. execution(返回值类型 包名.类名.方法名(参数列表)) 控制粒度较细
* 4. annotation(包名.注解名) 按照指定的注解进行匹配.
*
*/
}
2.Redis属性说明
2.1 Redis持久化策略
2.1.1 什么是持久化
说明: Redis中的数据都保存在内存中.内存如果遇到宕机/断电,则内存数据将会直接删除. 必须将内存数据定期持久化到磁盘中,从而实现了内存数据的保存.
2.1.2 Redis中的持久化策略
Redis根据配置文件中指定的持久化策略的描述,都是定期的将内存的数据按照指定的规则持久化的磁盘中.当Redis服务器重启时根据配置文件中指定的持久化文件的名称 读取持久化文件中的数据,从而实现了内存数据的恢复.
2.2持久化策略-RDB模式
2.2.1 RDB模式说明
说明:
1.RDB模式是redis中默认的持久化策略.
2.RDB模式定期将内存数据持久化到磁盘中. 可能会导致内存数据丢失.
3.RDB模式中持久化文件名称默认条件下 dump.rdb. 该文件中记录的是内存数据的快照.并且只记录最新的数据. 持久化文件相对较小. 该操作的持久化效率是最高的.
2.2.2 RDB模式-命令
说明: RDB模式如果需要进行持久化操作时,可以通过手动的方式执行如下的命令
命令:
1. save 指令 如果执行了save指令,则要求redis立即马上执行持久化操作,如果这时有用户操作redis则会陷入阻塞状态.
2. bgsave 指令
在后台启动单独的线程去执行持久化操作.该操作是异步的操作方式.用户操作时不会陷入阻塞.
2.2.3 RDB模式-持久化策略
说明:在redis.conf的配置文件中,记录了redis中持久化周期的配置文件.如果需要改动则需要编辑该文件.
save 900 1 在900秒内 如果用户执行了1次更新操作 则持久化一次
save 300 10 在300秒内 如果用户执行了10次更新操作 则持久化一次
save 60 10000 在60秒内 如果用户执行了10000次更新操作 则持久化一次
save 1 1 在1秒内 如果用户执行了1次更新操作 则持久化一次 效率极低.
用户操作越频繁,则持久化的周期就越短.
2.2.4 RDB模式-配置文件说明
1).配置持久化文件的名称

2).持久化文件位置 可以指定持久化文件的存储的路径.默认条件下在当前文件的目录中.

2.3 持久化策略-AOF模式
2.3.1 AOF模式说明
- AOF模式需要手动的开启
- AOF模式可以实现实时的数据持久化操作, 可以保证数据不丢失.
- AOF模式记录的是用户的操作过程.AOF持久化文件很大,所以需要定位更新维护.
- 如果用户开启了AOF模式,则rdb模式将不起作用. 但是可以进行持久化操作.
2.3.2 AOF配置文件说明

2.3.3AOF持久化策略
AOF模式持久化操作都是异步的操作方式
# appendfsync always 用户每做一次操作则持久化一次.
appendfsync everysec 每秒进行一次持久化操作. 效率略低于rdb模式.
# appendfsync no
2.3.4 关于持久化操作的总结
1. 如果redis中的内存数据,运行少量的数据丢失,则首选RDB 快
2. 如果redis中保存了业务数据不允许丢失,则选中AOF模式.
面试题:
当先redis选中AOF持久化方式. 由于操作不慎.执行了FLUSHALL命令,问如何快速恢复内存数据????
答:首先关闭redis 之后找到AOF持久化文件,将flushALL命令删除,之后重启redis服务器即可.
2.2Redis内存优化策略
2.2.1 为什么需要内存策略
如果向redis中添加数据,如果不定期维护内存的大小,则可能会出现内存溢出的问题. 所以通过有效的内存的策略来维护内存的大小.
2.2.2 LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
2.2.3 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
2.2.4 Random算法
随机算法
2.2.5 TTL算法
说明:在设定了超时时间的数据中,将马上超时的数据提前删除.
2.2.6Redis内存策略的配置
1.volatile-lru -> 在设定超时时间的数据选中lru算法提前删除数据.
2.allkeys-lru -> 所有的数据都采用lru算法删除.
3.volatile-lfu -> 设定了超时时间的数据采用lfu算法
4.allkeys-lfu -> 所有的数据采用lfu
5.volatile-random -> 设定超时时间的数据采用random算法
6.allkeys-random -> 所有数据随机
7.volatile-ttl -> 将马上要超时的数据提前删除.
8.noeviction -> 不会删除数据,并且该配置项是默认的配置.如果内存数据存满了将会报错返回.

3.Redis集群搭建
3.1 为什么需要搭建集群
1.如果网站中有海量的数据需要进行缓存存储, 如果使用1台redis来维护海量的内存空间,明显效率很低.
2.如果使用单台redis.则如果redis服务器宕机.则直接影响用户的使用. 因为单台没有办法实现高可用.
思考: 是否有一种机制 既可以满足海量的内存要求.同时能够满足redis高可用机制???
可以搭建redis集群.
3.2 集群的规划
主机:3台 端口:7000/7001/7002
从机:3台 端口:7003/7004/7005
具体的搭建的步骤:参数课前资料的文档!!!
3.2 集群搭建错误的解决方案
注意事项: 搭建redis集群之前,不允许操作redis. redis节点中的数据必须为空.
1).利用脚本关闭redis sh stop.sh
2).删除多余的配置文件
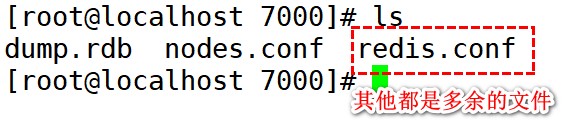

3).重启redis服务器
4).重新执行挂载指令
3.3检查集群中主从结构状态
1).通过命令检查主从状态


4.SpringBoot整合Redis集群
4.1入门案例
public class TestCluster {
/**
* 测试redis集群
*/
@Test
public void test01() {
//2.准备redis节点信息
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.126.129", 7000));
nodes.add(new HostAndPort("192.168.126.129", 7001));
nodes.add(new HostAndPort("192.168.126.129", 7002));
nodes.add(new HostAndPort("192.168.126.129", 7003));
nodes.add(new HostAndPort("192.168.126.129", 7004));
nodes.add(new HostAndPort("192.168.126.129", 7005));
//1.实例化工具API
JedisCluster jedisCluster = new JedisCluster(nodes);
jedisCluster.set("abc", "redis集群测试");
System.out.println(jedisCluster.get("abc"));
}
}
4.2编辑pro配置文件
#redis.host=192.168.126.129
#redis.port=6379
#配置redis集群
redis.nodes=192.168.126.129:7000,192.168.126.129:7001,192.168.126.129:7002,192.168.126.129:7003,192.168.126.129:7004,192.168.126.129:7005
4.3修改代码

4.4编辑配置类
package com.jt.config;
import java.util.HashSet;
import java.util.Set;
import javax.print.attribute.HashAttributeSet;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisCluster;
//代表早期的配置文件
@Configuration
@PropertySource("classpath:/properties/redis.properties")
public class RedisConfig {
@Value("${redis.nodes}")
private String nodes; //node,node,node,node
@Bean
public JedisCluster jedisCluster() {
Set<HostAndPort> set = new HashSet<>();
String[] nodeArray = nodes.split(",");
for (String node : nodeArray) { //node=ip:port
String host = node.split(":")[0];
int port = Integer.parseInt(node.split(":")[1]);
set.add(new HostAndPort(host, port));
}
return new JedisCluster(set);
}
}
/* @Value("${redis.host}")
private String host;
@Value("${redis.port}")
private Integer port;
//bean注解 将生成的jedis对象交给Spring容器管理
@Bean
public Jedis jedis() {
return new Jedis(host,port);
}*/
4.5实现AOP操作Redis集群

作业
1. word 编辑 AOP中切入点表达式的种类 并且举例说明其用法.
例子: bean(xxxxx) //该切入点表达式对xxxxx有效.
2. word: 总结5大通知的用法 通过代码的形式进行总结
@Before("joinPoint()")
public void before(JoinPoint joinPoint) {
Date date = new Date();
String strDate = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date);
String typeName = joinPoint.getSignature().getDeclaringTypeName();
String methodName = joinPoint.getSignature().getName();
System.out.println("我是前置通知");
System.out.println(strDate+":"+typeName+":"+methodName);
}
总结: 前置通知一般用来记录程序调用之前的状态.
- 完成redis集群搭建,并且能够展现测试效果 (拍段视频)最好或者文档
1.记录配置类信息
2.记录AOP中注入信息
3.页面效果 记录执行情况
不到40分钟完成了…